Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
作者: Yunhe Wang, Kai Han, Huiling Zhen, Yuchuan Tian, Hanting Chen, Yongbing Huang, Yufei Cui, Yingte Shu, Shan Gao, Ismail Elezi, Roy Vaughan Miles, Songcen Xu, Feng Wen, Chao Xu, Sinan Zeng, Dacheng Tao
分类: cs.CL, cs.AI
发布日期: 2026-01-20
💡 一句话要点
剖析扩散语言模型未来发展十大挑战,探索超越自回归范式的AI新方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 大型语言模型 自回归模型 文本生成 深度学习
📋 核心要点
- 自回归语言模型受因果关系限制,缺乏全局视野和迭代优化能力,成为进一步发展的瓶颈。
- 论文提出扩散语言模型(DLMs)作为一种替代方案,将文本生成视为整体的双向去噪过程,突破因果限制。
- 文章识别了阻碍DLMs发展的十大挑战,并提出了包含基础架构、算法优化、认知推理和多模态智能的战略路线图。
📝 摘要(中文)
大型语言模型(LLMs)的范式目前由自回归(AR)架构定义,该架构通过顺序的“逐块”过程生成文本。尽管AR模型取得了成功,但它们本质上受到因果瓶颈的限制,这限制了全局结构的前瞻性和迭代改进。扩散语言模型(DLMs)提供了一种变革性的替代方案,将文本生成概念化为一个整体的、双向的去噪过程,类似于雕塑家完善杰作。然而,DLMs的潜力在很大程度上尚未开发,因为它们经常被限制在AR遗留的基础设施和优化框架中。在本Perspective中,我们确定了从架构惯性和梯度稀疏性到线性推理的局限性的十个基本挑战,这些挑战阻止DLMs达到它们的“GPT-4时刻”。我们提出了一个分为四个支柱的战略路线图:基础架构、算法优化、认知推理和统一的多模态智能。通过转向以多尺度token化、主动重掩码和潜在思维为特征的扩散原生生态系统,我们可以超越因果视野的约束。我们认为,这种转变对于开发能够进行复杂结构推理、动态自我纠正和无缝多模态集成的下一代AI至关重要。
🔬 方法详解
问题定义:现有的大型语言模型主要采用自回归(AR)架构,这种架构通过逐个token生成文本的方式,存在固有的因果瓶颈。这种瓶颈限制了模型对全局结构的理解和长距离依赖关系的建模能力,同时也难以进行迭代优化和自我修正。因此,如何突破AR架构的限制,构建更强大的语言模型成为一个重要的研究问题。
核心思路:论文的核心思路是利用扩散语言模型(DLMs)来替代传统的自回归模型。DLMs将文本生成过程视为一个逐步去噪的过程,类似于图像生成中的扩散模型。通过这种方式,模型可以同时考虑整个文本的结构,避免了自回归模型的因果依赖限制。此外,DLMs还具有更强的鲁棒性和抗噪能力。
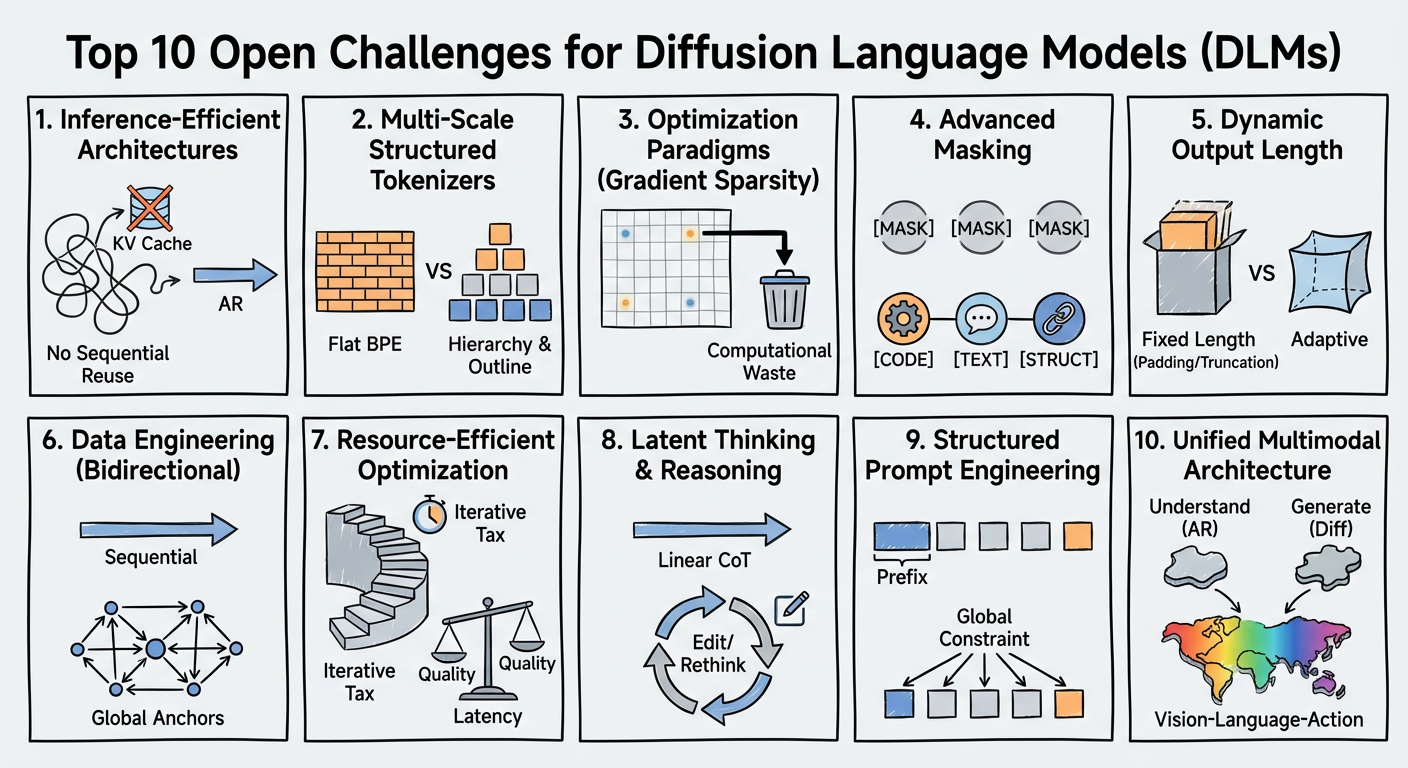
技术框架:论文并没有提出一个具体的DLM模型架构,而是着重分析了DLMs发展面临的十大挑战,并提出了一个战略路线图。该路线图包含四个主要支柱:1) 基础架构:构建扩散原生生态系统,包括多尺度token化和主动重掩码等技术;2) 算法优化:解决梯度稀疏性等问题,提高训练效率;3) 认知推理:提升DLMs的结构推理和动态自我纠正能力;4) 统一的多模态智能:实现DLMs与视觉、听觉等多种模态的无缝集成。
关键创新:论文的关键创新在于提出了一个全新的视角来看待语言模型的发展,即从自回归范式转向扩散范式。这种转变有望突破现有语言模型的瓶颈,实现更强大的文本生成和理解能力。此外,论文还系统地分析了DLMs发展面临的挑战,并提出了相应的解决方案,为未来的研究提供了指导。
关键设计:论文并没有涉及具体的模型设计细节,而是侧重于宏观层面的分析和规划。未来的研究可以关注以下几个方面:1) 如何设计更有效的多尺度token化方法;2) 如何实现主动重掩码,以提高模型的训练效率;3) 如何将认知推理能力融入到DLMs中;4) 如何实现DLMs与多模态数据的有效融合。
🖼️ 关键图片
📊 实验亮点
该论文并非实验性研究,而是一篇观点性文章,因此没有具体的实验结果。其亮点在于系统性地总结了扩散语言模型发展面临的十大挑战,并提出了一个战略路线图,为未来的研究方向提供了重要的参考。该路线图涵盖了基础架构、算法优化、认知推理和多模态智能等多个方面,具有重要的指导意义。
🎯 应用场景
扩散语言模型在文本生成、机器翻译、对话系统等领域具有广泛的应用前景。它们能够生成更连贯、更具创造性的文本,提高机器翻译的质量,并构建更智能的对话系统。此外,DLMs在代码生成、文本编辑和信息检索等领域也具有潜在的应用价值。未来的发展有望推动人工智能在各个领域的应用。
📄 摘要(原文)
The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential
brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching theirGPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.