BACH-V: Bridging Abstract and Concrete Human-Values in Large Language Models
作者: Junyu Zhang, Yipeng Kang, Jiong Guo, Jiayu Zhan, Junqi Wang
分类: cs.CL
发布日期: 2026-01-20
备注: 34 pagess, 16 figures, 6 tables, submitted to ACL 2026
💡 一句话要点
BACH-V:构建大语言模型中抽象与具体人类价值观的桥梁
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 价值观对齐 抽象推理 因果干预 表征学习
📋 核心要点
- 现有大语言模型在理解和应用抽象概念方面存在挑战,难以确定其是否真正理解或仅是模式匹配。
- 论文提出抽象-具象化框架,将概念理解分解为抽象解释、具象化和应用三个能力,并以人类价值观为测试平台。
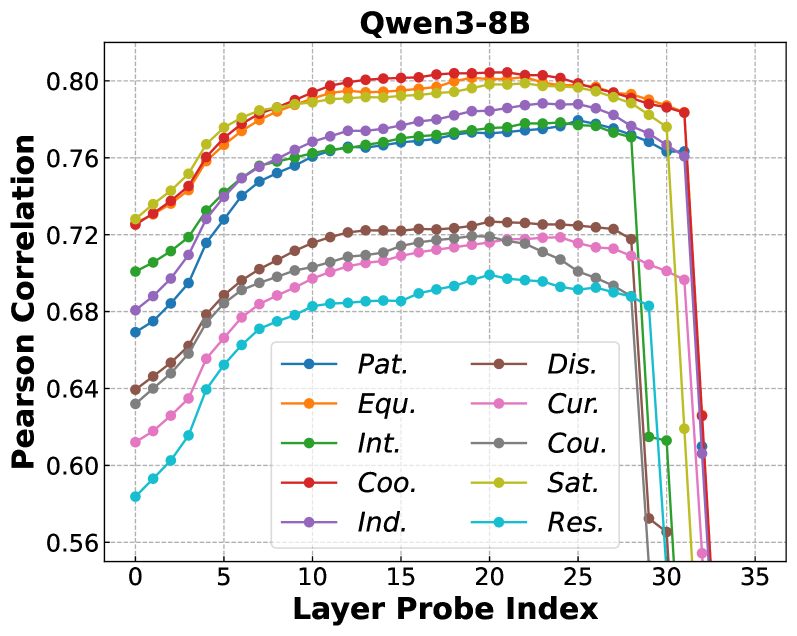
- 实验结果表明,LLM能够跨层传递价值理解,且抽象价值表征对具体决策具有因果影响,但反之不然。
📝 摘要(中文)
大型语言模型(LLM)是否真正理解抽象概念,还是仅仅将其作为统计模式进行操作?我们引入了一个抽象-具象化的框架,将概念理解分解为三个能力:抽象概念的解释(抽象-抽象,A-A),抽象概念在具体事件中的具象化(抽象-具体,A-C),以及应用抽象原则来调节具体决策(具体-具体,C-C)。以人类价值观作为测试平台——鉴于其语义丰富性和对齐的核心地位——我们采用探测(检测内部激活中的价值痕迹)和引导(修改表征以改变行为)。在六个开源LLM和十个价值维度上,探测显示,仅在抽象价值描述上训练的诊断探测器能够可靠地检测到具体事件叙述和决策推理中的相同价值,证明了跨层转移。引导揭示了一种不对称性:干预价值表征会因果地改变具体判断和决策(A-C,C-C),但保持抽象解释不变(A-A),这表明编码的抽象价值充当稳定的锚点,而不是可塑的激活。这些发现表明LLM保持着结构化的价值表征,这些表征连接了抽象和行动,为构建具有更透明、可泛化的对齐和控制的价值驱动的自主AI系统提供了机制和操作基础。
🔬 方法详解
问题定义:现有的大语言模型在处理抽象概念时,缺乏一种明确的机制来验证其是否真正理解这些概念,还是仅仅在进行统计模式匹配。这使得我们难以信任它们在涉及伦理、道德等复杂场景下的决策能力。现有的方法难以区分模型是对抽象概念的真正理解,还是仅仅通过大量数据学习到的表面关联。
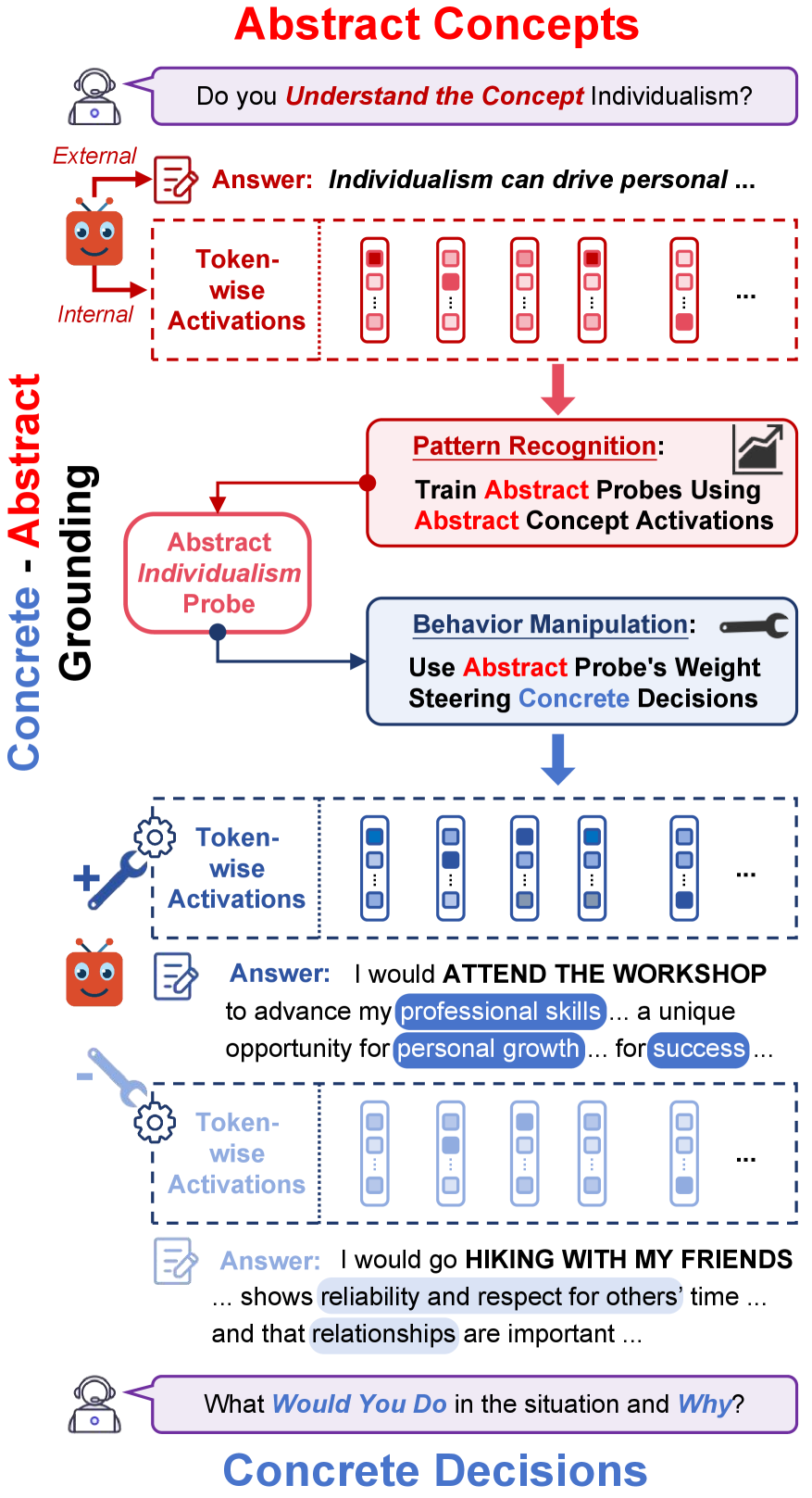
核心思路:论文的核心思路是将概念理解分解为三个层次:抽象概念的解释(A-A),抽象概念在具体事件中的具象化(A-C),以及应用抽象原则来调节具体决策(C-C)。通过这种分解,可以更细粒度地评估模型在不同层次上的理解能力,并揭示抽象概念与具体行为之间的联系。选择人类价值观作为测试平台,是因为其具有丰富的语义信息和在对齐问题中的核心地位。
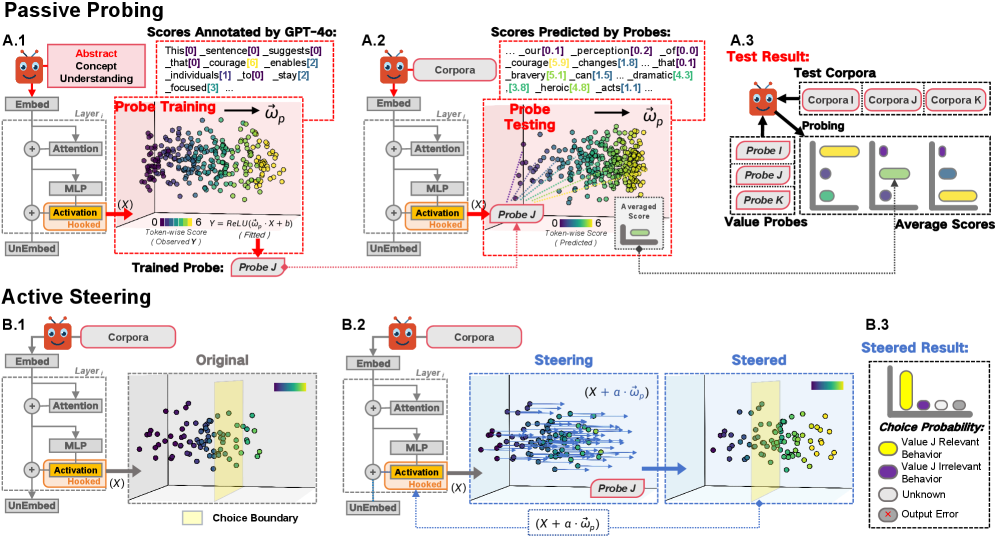
技术框架:该研究采用了一种抽象-具象化的框架,主要包含两个阶段:探测(Probing)和引导(Steering)。探测阶段旨在检测模型内部激活中是否存在与特定价值观相关的痕迹,通过训练诊断探测器来识别这些痕迹。引导阶段则通过修改模型的内部表征来观察其对具体决策的影响,从而验证抽象价值表征是否对具体行为具有因果关系。整个框架涉及多个开源LLM和多个价值维度,以确保结果的泛化性。
关键创新:该研究的关键创新在于提出了一个系统性的框架,用于评估LLM在抽象概念理解方面的能力,并揭示了抽象价值表征与具体行为之间的因果关系。通过探测和引导两种方法,可以更深入地了解模型内部的运作机制,并为构建价值驱动的AI系统提供理论基础。此外,发现抽象价值表征作为稳定锚点而非可塑激活,也为理解LLM的内部表征提供了新的视角。
关键设计:在探测阶段,使用线性探测器来检测模型内部激活中与特定价值观相关的特征。探测器在抽象价值描述上进行训练,然后在具体事件叙述和决策推理上进行测试,以评估其跨层传递能力。在引导阶段,通过修改模型内部的价值表征来观察其对具体决策的影响。具体来说,使用因果干预技术来改变价值表征,并观察其对模型输出的影响。实验中使用了六个开源LLM和十个价值维度,并采用了标准化的评估指标来衡量模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,仅在抽象价值描述上训练的诊断探测器能够可靠地检测到具体事件叙述和决策推理中的相同价值,证明了跨层转移。引导实验揭示,干预价值表征会因果地改变具体判断和决策,但保持抽象解释不变,表明抽象价值表征作为稳定锚点。
🎯 应用场景
该研究成果可应用于构建更值得信赖和符合伦理规范的AI系统。通过理解和控制LLM中的价值表征,可以提高AI系统在涉及伦理、道德等复杂场景下的决策能力,并确保其行为与人类价值观对齐。这对于开发自动驾驶、医疗诊断等高风险应用至关重要。
📄 摘要(原文)
Do large language models (LLMs) genuinely understand abstract concepts, or merely manipulate them as statistical patterns? We introduce an abstraction-grounding framework that decomposes conceptual understanding into three capacities: interpretation of abstract concepts (Abstract-Abstract, A-A), grounding of abstractions in concrete events (Abstract-Concrete, A-C), and application of abstract principles to regulate concrete decisions (Concrete-Concrete, C-C). Using human values as a testbed - given their semantic richness and centrality to alignment - we employ probing (detecting value traces in internal activations) and steering (modifying representations to shift behavior). Across six open-source LLMs and ten value dimensions, probing shows that diagnostic probes trained solely on abstract value descriptions reliably detect the same values in concrete event narratives and decision reasoning, demonstrating cross-level transfer. Steering reveals an asymmetry: intervening on value representations causally shifts concrete judgments and decisions (A-C, C-C), yet leaves abstract interpretations unchanged (A-A), suggesting that encoded abstract values function as stable anchors rather than malleable activations. These findings indicate LLMs maintain structured value representations that bridge abstraction and action, providing a mechanistic and operational foundation for building value-driven autonomous AI systems with more transparent, generalizable alignment and control.