Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
作者: Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, Zeping Yu, Chenming Shang, Xiao Liang, Jing Xiong, Hui Shen, Chaofan Tao, Zhengwu Liu, Senjie Jin, Zhiheng Xi, Dongdong Zhang, Sophia Ananiadou, Tao Gui, Ruobing Xie, Hayden Kwok-Hay So, Hinrich Schütze, Xuanjing Huang, Qi Zhang, Ngai Wong
分类: cs.CL
发布日期: 2026-01-20 (更新: 2026-01-22)
🔗 代码/项目: GITHUB
💡 一句话要点
提出“定位、引导、改进”框架,实现大语言模型可操作的机制可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机制可解释性 大语言模型 可操作干预 模型对齐 模型优化 定位引导改进 可解释对象 干预策略
📋 核心要点
- 现有机制可解释性研究缺乏系统性的干预框架,难以将分析结果转化为实际的模型改进。
- 论文提出“定位、引导、改进”框架,通过诊断、干预和优化三个步骤,实现对LLM的可操作机制可解释性。
- 该框架能够指导模型对齐、能力提升和效率优化,将机制可解释性从观察性研究转变为可操作的方法论。
📝 摘要(中文)
机制可解释性(MI)已成为揭示大语言模型(LLM)不透明决策过程的关键方法。然而,现有的综述主要将MI视为一种观察性科学,总结分析性见解,缺乏可操作干预的系统框架。为了弥合这一差距,我们提出了一个围绕“定位、引导、改进”流程构建的实践性综述。我们基于特定的可解释对象,正式地对定位(诊断)和引导(干预)方法进行分类,以建立严格的干预协议。此外,我们展示了该框架如何能够切实改进对齐性、能力和效率,从而有效地将MI作为模型优化的可操作方法。
🔬 方法详解
问题定义:现有的大语言模型机制可解释性研究主要集中在观察和分析模型的内部运作机制,缺乏将这些理解转化为实际模型改进的有效方法。痛点在于,即使研究人员能够识别出模型中的特定神经元或连接与特定行为相关,也难以利用这些知识来提升模型的性能或解决其存在的问题,例如对齐性问题。
核心思路:论文的核心思路是将机制可解释性研究从纯粹的观察性研究转变为可操作的干预手段。通过构建一个“定位、引导、改进”的框架,研究人员可以系统地诊断模型的问题,然后通过干预模型的内部机制来解决这些问题,最终实现模型性能的提升。
技术框架:该框架包含三个主要阶段: 1. 定位 (Locate):识别模型中与特定行为或问题相关的可解释对象,例如神经元、注意力头等。 2. 引导 (Steer):设计干预策略,通过修改或控制这些可解释对象的行为来影响模型的输出。 3. 改进 (Improve):评估干预策略的效果,并根据评估结果调整干预策略,最终实现模型性能的提升。
关键创新:该论文最重要的技术创新在于提出了一个完整的、可操作的机制可解释性框架,将机制可解释性研究与模型改进联系起来。与以往的研究相比,该框架更加注重实际应用,旨在解决大语言模型中存在的实际问题,例如对齐性、能力和效率问题。
关键设计:论文的关键设计包括: 1. 可解释对象的分类:论文对可解释对象进行了分类,例如神经元、注意力头等,并针对不同类型的可解释对象提出了不同的干预策略。 2. 干预协议的建立:论文建立了一套严格的干预协议,确保干预过程的可重复性和可验证性。 3. 改进效果的评估:论文提出了多种评估指标,用于评估干预策略的效果,并根据评估结果调整干预策略。
🖼️ 关键图片

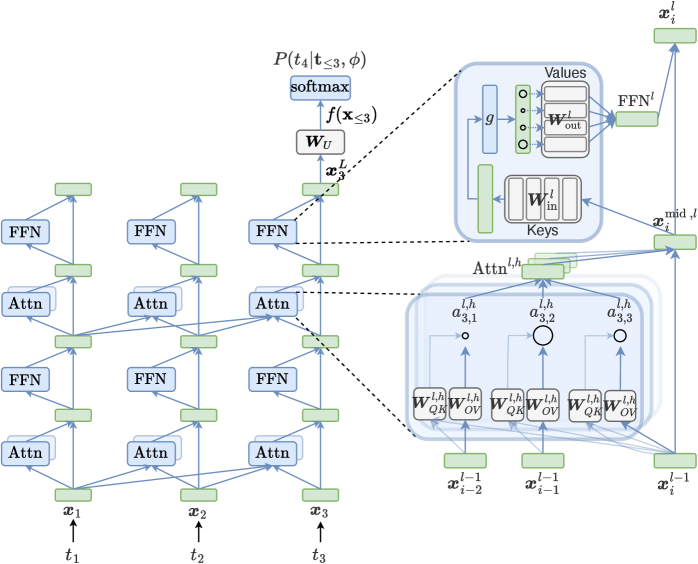
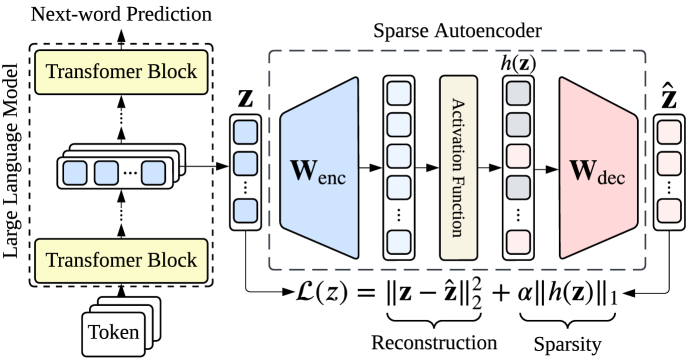
📊 实验亮点
该综述性论文的核心价值在于提出了一个可操作的机制可解释性框架,并展示了该框架在对齐性、能力和效率三个方面的潜在应用。虽然没有提供具体的实验数据,但该框架为未来的研究提供了一个清晰的方向,并有望推动大语言模型机制可解释性研究的实际应用。
🎯 应用场景
该研究成果可应用于大语言模型的对齐性改进、能力提升和效率优化。例如,可以利用该框架来识别并修复模型中的有害偏见,提高模型生成文本的安全性;也可以用于提升模型在特定任务上的性能,例如问答、翻译等;还可以用于优化模型的计算效率,降低模型的部署成本。该框架为大语言模型的安全、可靠和高效应用提供了新的思路。
📄 摘要(原文)
Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.