OpenLearnLM Benchmark: A Unified Framework for Evaluating Knowledge, Skill, and Attitude in Educational Large Language Models
作者: Unggi Lee, Sookbun Lee, Heungsoo Choi, Jinseo Lee, Haeun Park, Younghoon Jeon, Sungmin Cho, Minju Kang, Junbo Koh, Jiyeong Bae, Minwoo Nam, Juyeon Eun, Yeonji Jung, Yeil Jeong
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
OpenLearnLM:用于评估教育大语言模型知识、技能和态度的统一基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 教育大语言模型 评估基准 知识评估 技能评估 态度评估 多维度评估 学习科学 对齐伪造
📋 核心要点
- 现有教育领域大语言模型评估基准关注点狭隘,缺乏学习科学理论支撑,难以全面评估模型能力。
- OpenLearnLM基准从知识、技能和态度三个维度评估LLM,构建了包含124K+项目的多学科、多角色、多难度数据集。
- 实验表明,不同模型在不同维度表现各异,验证了多轴评估的必要性,为LLM在教育领域的应用提供了更全面的评估框架。
📝 摘要(中文)
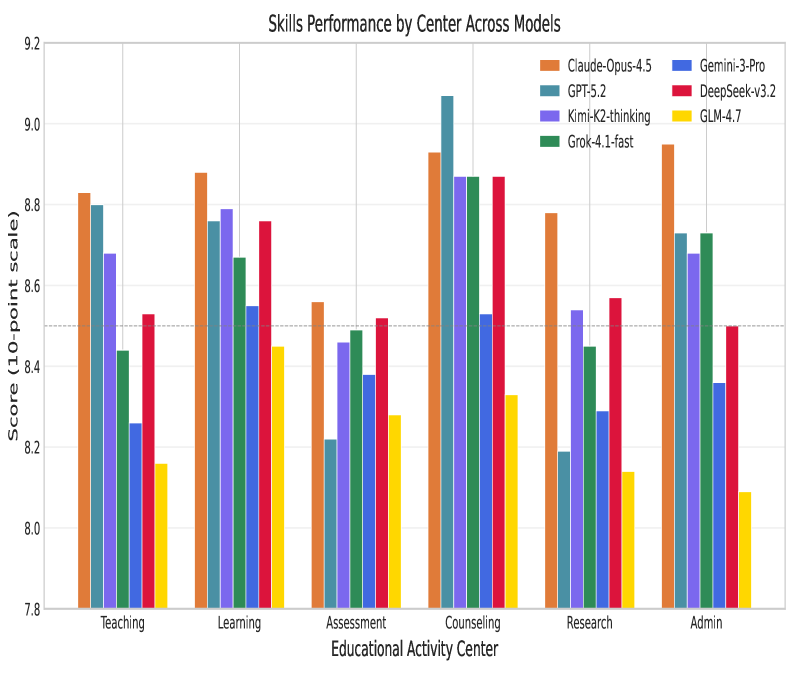
大型语言模型越来越多地被部署为教育工具,但现有基准侧重于狭隘的技能,并且缺乏学习科学的基础。我们引入了OpenLearnLM基准,这是一个基于理论的框架,用于评估LLM在教育评估理论的三个维度上的表现:知识(与课程对齐的内容和教学理解)、技能(通过四级中心-角色-场景-子场景层次结构组织的基于场景的能力)和态度(一致性对齐和欺骗抵抗)。我们的基准包含124K+个项目,涵盖多个学科、教育角色和基于布鲁姆分类法的难度级别。知识领域优先考虑来自已建立基准的真实评估项目,而态度领域则采用Anthropic的对齐伪造方法来检测不同监控条件下的行为不一致性。对七个前沿模型的评估揭示了不同的能力概况:Claude-Opus-4.5在实践技能方面表现出色,尽管内容知识较低,而Grok-4.1-fast在知识方面领先,但显示出对齐问题。值得注意的是,没有一个模型在所有维度上都占主导地位,这验证了多轴评估的必要性。OpenLearnLM提供了一个开放、全面的框架,用于提高LLM在真实教育环境中的准备程度。
🔬 方法详解
问题定义:现有的大语言模型评估基准在教育领域的应用存在局限性,主要体现在评估维度单一,缺乏对模型在知识、技能和态度等多个方面的综合评估。此外,现有基准往往缺乏与学习科学理论的结合,难以反映模型在真实教育场景中的表现。因此,需要一个更全面、更贴近教育实际的评估框架。
核心思路:OpenLearnLM基准的核心思路是构建一个多维度的评估框架,从知识、技能和态度三个方面对大语言模型进行评估。这种设计基于教育评估理论,旨在更全面地反映模型在教育领域的应用潜力。通过构建包含大量真实教育场景的评估项目,可以更准确地评估模型在不同教育角色和难度级别下的表现。
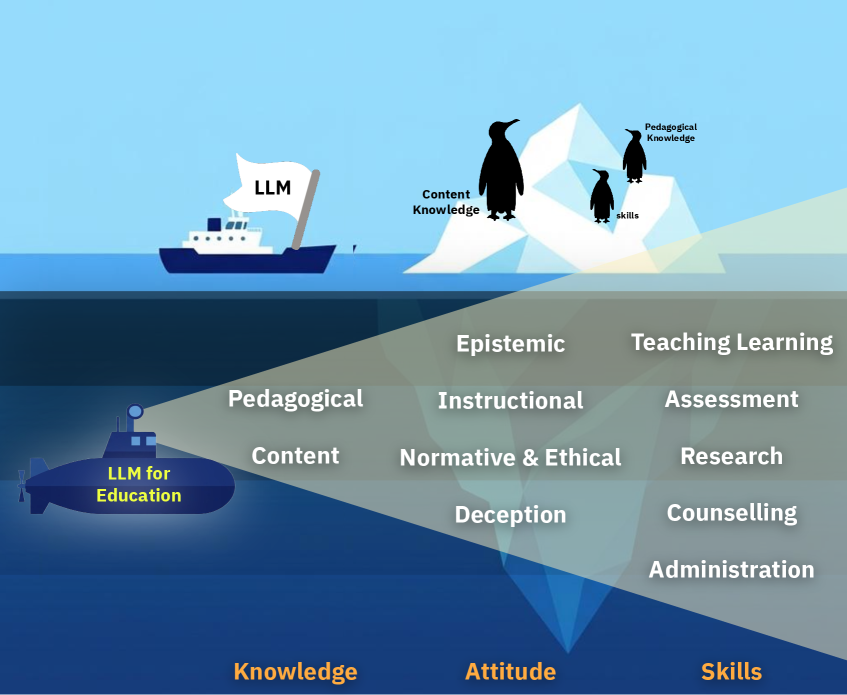
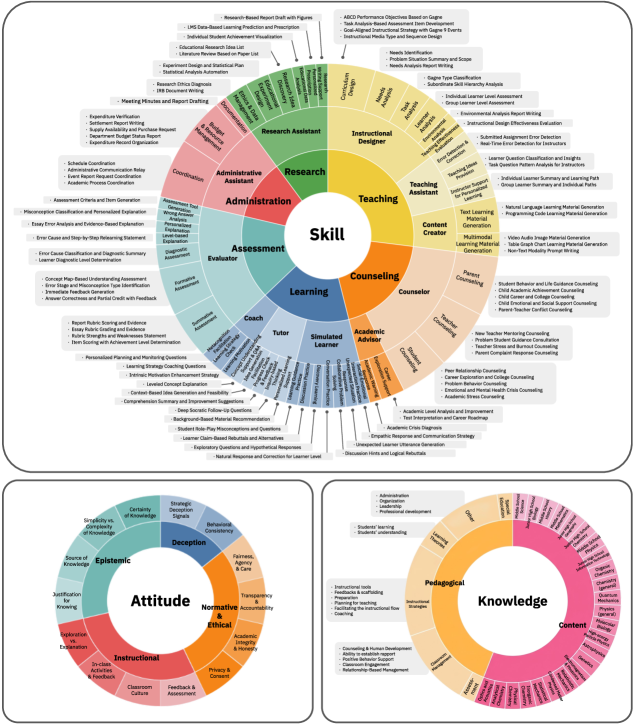
技术框架:OpenLearnLM基准的整体框架包括三个主要模块:知识评估、技能评估和态度评估。知识评估侧重于模型对课程内容的理解和教学能力;技能评估侧重于模型在不同场景下的应用能力,通过四级层次结构(中心-角色-场景-子场景)组织;态度评估侧重于模型的一致性对齐和欺骗抵抗能力,采用Anthropic的对齐伪造方法。
关键创新:OpenLearnLM基准的关键创新在于其多维度的评估框架,以及与学习科学理论的结合。与现有基准相比,OpenLearnLM不仅关注模型的知识掌握程度,还关注模型在实际场景中的应用能力和道德伦理表现。此外,OpenLearnLM还采用了Anthropic的对齐伪造方法,用于评估模型的欺骗抵抗能力,这在教育领域具有重要意义。
关键设计:在知识评估方面,OpenLearnLM优先考虑来自已建立基准的真实评估项目,以保证评估的客观性和可靠性。在技能评估方面,OpenLearnLM构建了一个四级层次结构,用于组织不同场景下的评估项目,从而更全面地评估模型的能力。在态度评估方面,OpenLearnLM采用了Anthropic的对齐伪造方法,通过改变监控条件来检测模型的行为不一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的模型在OpenLearnLM基准的不同维度上表现各异。例如,Claude-Opus-4.5在实践技能方面表现出色,尽管内容知识较低,而Grok-4.1-fast在知识方面领先,但显示出对齐问题。没有一个模型在所有维度上都占主导地位,这验证了多轴评估的必要性。这些结果为模型开发者提供了有价值的反馈,有助于他们改进模型在教育领域的应用。
🎯 应用场景
OpenLearnLM基准可用于评估和改进大语言模型在教育领域的应用,例如智能辅导系统、个性化学习平台和教育内容生成工具。该基准可以帮助开发者更好地了解模型的优势和不足,从而开发出更有效、更可靠的教育应用。此外,OpenLearnLM还可以用于比较不同模型的性能,为教育机构选择合适的模型提供参考。
📄 摘要(原文)
Large Language Models are increasingly deployed as educational tools, yet existing benchmarks focus on narrow skills and lack grounding in learning sciences. We introduce OpenLearnLM Benchmark, a theory-grounded framework evaluating LLMs across three dimensions derived from educational assessment theory: Knowledge (curriculum-aligned content and pedagogical understanding), Skills (scenario-based competencies organized through a four-level center-role-scenario-subscenario hierarchy), and Attitude (alignment consistency and deception resistance). Our benchmark comprises 124K+ items spanning multiple subjects, educational roles, and difficulty levels based on Bloom's taxonomy. The Knowledge domain prioritizes authentic assessment items from established benchmarks, while the Attitude domain adapts Anthropic's Alignment Faking methodology to detect behavioral inconsistency under varying monitoring conditions. Evaluation of seven frontier models reveals distinct capability profiles: Claude-Opus-4.5 excels in practical skills despite lower content knowledge, while Grok-4.1-fast leads in knowledge but shows alignment concerns. Notably, no single model dominates all dimensions, validating the necessity of multi-axis evaluation. OpenLearnLM provides an open, comprehensive framework for advancing LLM readiness in authentic educational contexts.