Chain-of-Thought Compression Should Not Be Blind: V-Skip for Efficient Multimodal Reasoning via Dual-Path Anchoring
作者: Dongxu Zhang, Yiding Sun, Cheng Tan, Wenbiao Yan, Ning Yang, Jihua Zhu, Haijun Zhang
分类: cs.MM, cs.CL, cs.CV
发布日期: 2026-01-20 (更新: 2026-01-21)
💡 一句话要点
提出V-Skip,通过双路径锚定解决多模态CoT推理中的视觉失忆问题,实现高效压缩。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 链式思考 token压缩 视觉锚定 信息瓶颈 视觉问答 推理加速
📋 核心要点
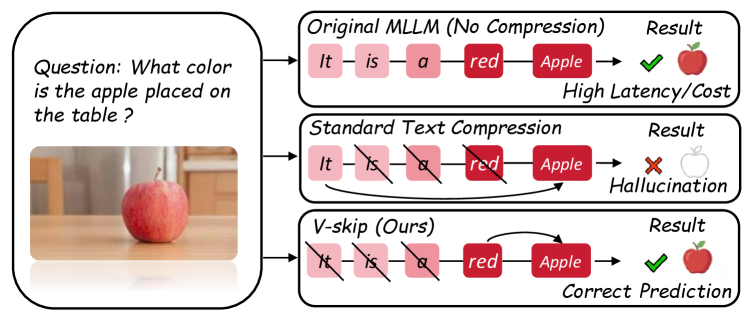
- 多模态大语言模型中的CoT推理虽提升性能,但自回归特性导致推理延迟过高,现有token压缩方法忽略视觉信息,易产生视觉失忆。
- V-Skip将token剪枝视为视觉锚定信息瓶颈优化问题,通过双路径门控机制,结合语言和视觉信息,保留重要视觉锚点。
- 实验表明,V-Skip在保证精度损失极小的情况下,实现了2.9倍的推理加速,并在DocVQA任务上显著优于其他基线方法。
📝 摘要(中文)
链式思考(CoT)推理显著提升了多模态大型语言模型(MLLM)的性能,但其自回归特性带来了严重的延迟约束。目前通过token压缩来缓解这一问题的尝试,通常会盲目地将以文本为中心的指标应用于多模态语境中,从而导致失败。我们发现了一种关键的失效模式,即视觉失忆,其中语言上冗余的token被错误地修剪,从而导致幻觉。为了解决这个问题,我们引入了V-Skip,它将token修剪重新定义为一个视觉锚定信息瓶颈(VA-IB)优化问题。V-Skip采用了一种双路径门控机制,通过语言惊异度和跨模态注意力流来权衡token的重要性,从而有效地拯救视觉上显著的锚点。在Qwen2-VL和Llama-3.2系列上的大量实验表明,V-Skip实现了2.9倍的加速,而精度损失可忽略不计。具体来说,它保留了细粒度的视觉细节,在DocVQA上优于其他基线30%以上。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型中,由于链式思考(CoT)推理的自回归特性导致的推理延迟问题。现有的token压缩方法主要基于文本信息,忽略了视觉信息的重要性,容易错误地删除视觉上重要的token,导致模型产生幻觉,即“视觉失忆”现象。
核心思路:论文的核心思路是将token剪枝问题重新定义为视觉锚定信息瓶颈(VA-IB)优化问题。通过引入视觉信息作为锚点,指导token的筛选,避免盲目地删除语言上看似冗余但视觉上重要的token。这样可以在保证模型性能的同时,有效地压缩token序列,加速推理过程。
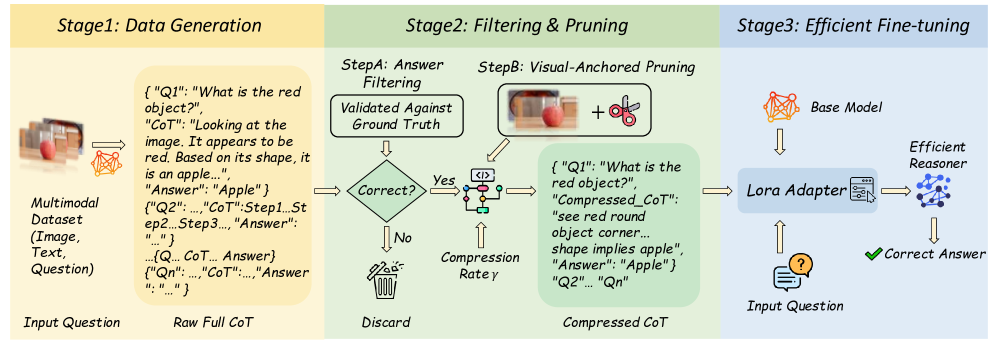
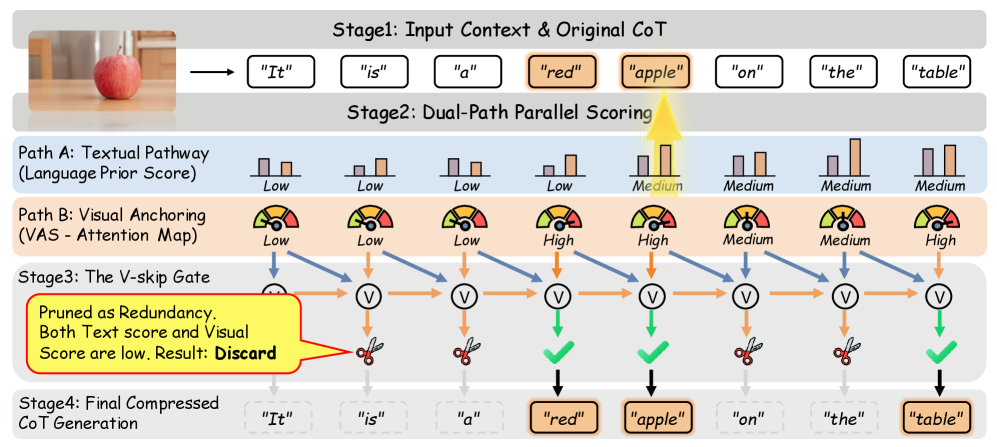
技术框架:V-Skip方法的核心是一个双路径门控机制。该机制包含两个路径:语言路径和视觉路径。语言路径利用语言惊异度(linguistic surprisal)来评估token的语言重要性;视觉路径则利用跨模态注意力流来评估token的视觉重要性。然后,通过一个门控函数,将两个路径的信息进行融合,得到最终的token重要性评分。基于该评分,可以对token进行剪枝,保留重要的token,删除不重要的token。
关键创新:V-Skip的关键创新在于其双路径门控机制,该机制能够同时考虑语言和视觉信息,从而更准确地评估token的重要性。与现有方法相比,V-Skip避免了盲目地应用文本为中心的指标,从而有效地缓解了视觉失忆问题。此外,将token剪枝问题重新定义为视觉锚定信息瓶颈优化问题,为解决多模态token压缩问题提供了一个新的视角。
关键设计:V-Skip的关键设计包括:1) 语言惊异度的计算方式,通常使用预训练语言模型计算token的概率分布,并取负对数作为惊异度;2) 跨模态注意力流的计算方式,通常使用跨模态注意力机制,计算每个token对视觉特征的注意力权重,并将其作为视觉重要性的指标;3) 门控函数的选择,可以使用sigmoid函数或其他可学习的函数,将语言和视觉信息进行融合;4) 剪枝策略的选择,可以使用固定比例剪枝或基于阈值的剪枝策略。
🖼️ 关键图片
📊 实验亮点
V-Skip在Qwen2-VL和Llama-3.2系列模型上进行了实验,结果表明,在精度损失可忽略不计的情况下,实现了2.9倍的推理加速。在DocVQA任务上,V-Skip的性能优于其他基线方法30%以上,证明了其在保留细粒度视觉细节方面的优势。这些结果表明,V-Skip是一种高效且有效的多模态token压缩方法。
🎯 应用场景
V-Skip方法可应用于各种需要高效多模态推理的场景,例如:移动设备上的视觉问答、自动驾驶中的场景理解、智能客服中的多模态信息处理等。通过降低计算成本和延迟,V-Skip能够使多模态大语言模型在资源受限的环境中部署和应用,加速相关技术的普及。
📄 摘要(原文)
While Chain-of-Thought (CoT) reasoning significantly enhances the performance of Multimodal Large Language Models (MLLMs), its autoregressive nature incurs prohibitive latency constraints. Current efforts to mitigate this via token compression often fail by blindly applying text-centric metrics to multimodal contexts. We identify a critical failure mode termed Visual Amnesia, where linguistically redundant tokens are erroneously pruned, leading to hallucinations. To address this, we introduce V-Skip that reformulates token pruning as a Visual-Anchored Information Bottleneck (VA-IB) optimization problem. V-Skip employs a dual-path gating mechanism that weighs token importance through both linguistic surprisal and cross-modal attention flow, effectively rescuing visually salient anchors. Extensive experiments on Qwen2-VL and Llama-3.2 families demonstrate that V-Skip achieves a $2.9\times$ speedup with negligible accuracy loss. Specifically, it preserves fine-grained visual details, outperforming other baselines over 30\% on the DocVQA.