Pedagogical Alignment for Vision-Language-Action Models: A Comprehensive Framework for Data, Architecture, and Evaluation in Education
作者: Unggi Lee, Jahyun Jeong, Sunyoung Shin, Haeun Park, Jeongsu Moon, Youngchang Song, Jaechang Shim, JaeHwan Lee, Yunju Noh, Seungwon Choi, Ahhyun Kim, TaeHyeon Kim, Kyungtae Joo, Taeyeong Kim, Gyeonggeon Lee
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
提出Pedagogical VLA Framework,用于资源受限教育场景下的可解释VLA模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 教学对齐 知识蒸馏 教育机器人 科学教育
📋 核心要点
- 现有VLA模型计算资源需求大,牺牲语言生成能力,不适用于资源受限的教育场景。
- Pedagogical VLA Framework通过文本修复、LLM蒸馏、安全训练和教学评估实现教学对齐。
- 实验表明,该框架在保持任务性能的同时,能够生成符合教育场景的解释文本。
📝 摘要(中文)
科学演示对于有效的STEM教育至关重要,但教师在多次进行演示时面临安全性和一致性的挑战,机器人技术可以提供帮助。然而,当前的视觉-语言-动作(VLA)模型需要大量的计算资源,并且为了最大化效率而牺牲了语言生成能力,这使得它们不适合需要可解释、能生成解释的、资源受限的教育环境。我们提出了Pedagogical VLA Framework,该框架通过四个组成部分将教学对齐应用于轻量级VLA模型:文本修复以恢复语言生成能力,大型语言模型(LLM)蒸馏以传递教学知识,针对教育环境的安全训练,以及针对科学教育背景调整的教学评估。我们使用与科学教育专家合作开发的评估框架,在涵盖物理、化学、生物和地球科学的五个科学演示中评估Pedagogical VLA Framework。我们的评估通过教师调查和LLM-as-Judge评估来评估任务性能(成功率、协议合规性、效率、安全性)和教学质量。此外,我们还对生成的文本进行了定性分析。实验结果表明,Pedagogical VLA Framework在产生上下文相关的教育解释的同时,实现了与基线模型相当的任务性能。
🔬 方法详解
问题定义:论文旨在解决现有视觉-语言-动作(VLA)模型在教育场景中应用受限的问题。具体来说,现有VLA模型通常需要大量的计算资源,并且为了追求效率牺牲了语言生成能力,这使得它们难以在资源有限的教育环境中部署,并且无法提供教师和学生所需的可解释的解释。
核心思路:论文的核心思路是通过“教学对齐”(Pedagogical Alignment)来改进轻量级的VLA模型,使其更适合教育场景。教学对齐意味着模型不仅要完成任务,还要以符合教育原则的方式进行,例如提供清晰的解释、确保安全性等。通过将教学知识融入到模型中,使其能够更好地服务于教育目标。
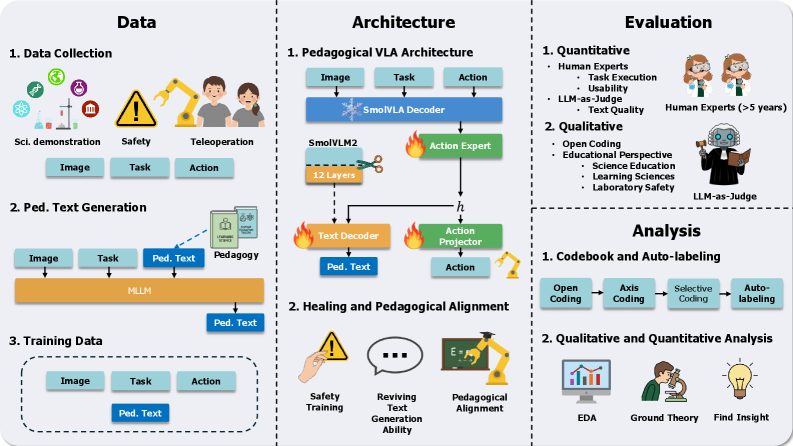
技术框架:Pedagogical VLA Framework包含四个主要组成部分:1) 文本修复(Text Healing):恢复轻量级VLA模型的语言生成能力。2) LLM蒸馏(LLM Distillation):将大型语言模型(LLM)的教学知识迁移到VLA模型。3) 安全训练(Safety Training):针对教育环境进行安全训练,确保模型行为安全可靠。4) 教学评估(Pedagogical Evaluation):设计针对科学教育场景的评估指标,评估模型的教学质量。
关键创新:该框架的关键创新在于将“教学对齐”的概念引入到VLA模型的设计中。以往的VLA模型主要关注任务完成的效率和准确性,而忽略了模型在教育场景中的可解释性、安全性和教学质量。通过文本修复、LLM蒸馏和安全训练等手段,该框架能够有效地提升VLA模型在教育场景中的表现。
关键设计:文本修复的具体方法未知,但目的是恢复语言生成能力。LLM蒸馏可能采用知识蒸馏的常见方法,将LLM的输出作为VLA模型的训练目标。安全训练可能包括对模型进行对抗训练,使其能够识别和避免危险行为。教学评估指标包括任务性能(成功率、协议合规性、效率、安全性)和教学质量(通过教师调查和LLM-as-Judge评估)。
🖼️ 关键图片

📊 实验亮点
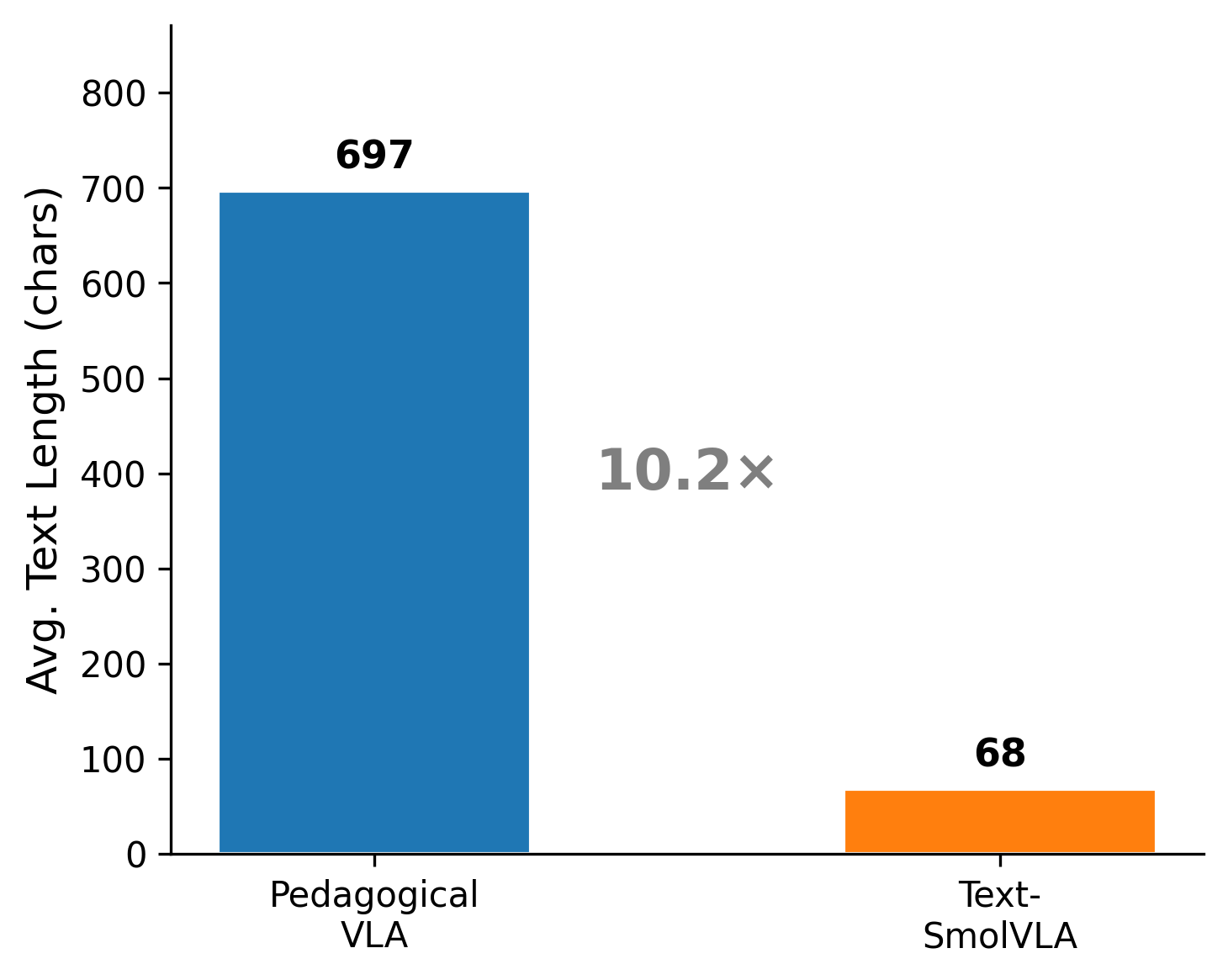
实验结果表明,Pedagogical VLA Framework在五个科学演示任务中,实现了与基线模型相当的任务性能,同时能够生成上下文相关的教育解释。通过教师调查和LLM-as-Judge评估,验证了该框架在教学质量方面的有效性。虽然具体性能提升数据未知,但定性分析表明生成的文本更符合教育场景的需求。
🎯 应用场景
该研究成果可应用于开发智能教育机器人,辅助教师进行科学演示,提供个性化的学习指导,并生成可解释的教学内容。此外,该框架的设计理念和技术手段也可以推广到其他教育领域的AI应用中,例如语言学习、数学辅导等,具有广阔的应用前景。
📄 摘要(原文)
Science demonstrations are important for effective STEM education, yet teachers face challenges in conducting them safely and consistently across multiple occasions, where robotics can be helpful. However, current Vision-Language-Action (VLA) models require substantial computational resources and sacrifice language generation capabilities to maximize efficiency, making them unsuitable for resource-constrained educational settings that require interpretable, explanation-generating systems. We present \textit{Pedagogical VLA Framework}, a framework that applies pedagogical alignment to lightweight VLA models through four components: text healing to restore language generation capabilities, large language model (LLM) distillation to transfer pedagogical knowledge, safety training for educational environments, and pedagogical evaluation adjusted to science education contexts. We evaluate Pedagogical VLA Framework across five science demonstrations spanning physics, chemistry, biology, and earth science, using an evaluation framework developed in collaboration with science education experts. Our evaluation assesses both task performance (success rate, protocol compliance, efficiency, safety) and pedagogical quality through teacher surveys and LLM-as-Judge assessment. We additionally provide qualitative analysis of generated texts. Experimental results demonstrate that Pedagogical VLA Framework achieves comparable task performance to baseline models while producing contextually appropriate educational explanations.