Pro-AI Bias in Large Language Models
作者: Benaya Trabelsi, Jonathan Shaki, Sarit Kraus
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2026-01-20
备注: 13 pages, 6 figures. Code available at: https://github.com/benayat/Pro-AI-bias-in-LLMs
💡 一句话要点
揭示大型语言模型中存在的亲AI偏见,可能影响决策。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 AI偏见 决策支持 薪资评估 表征学习
📋 核心要点
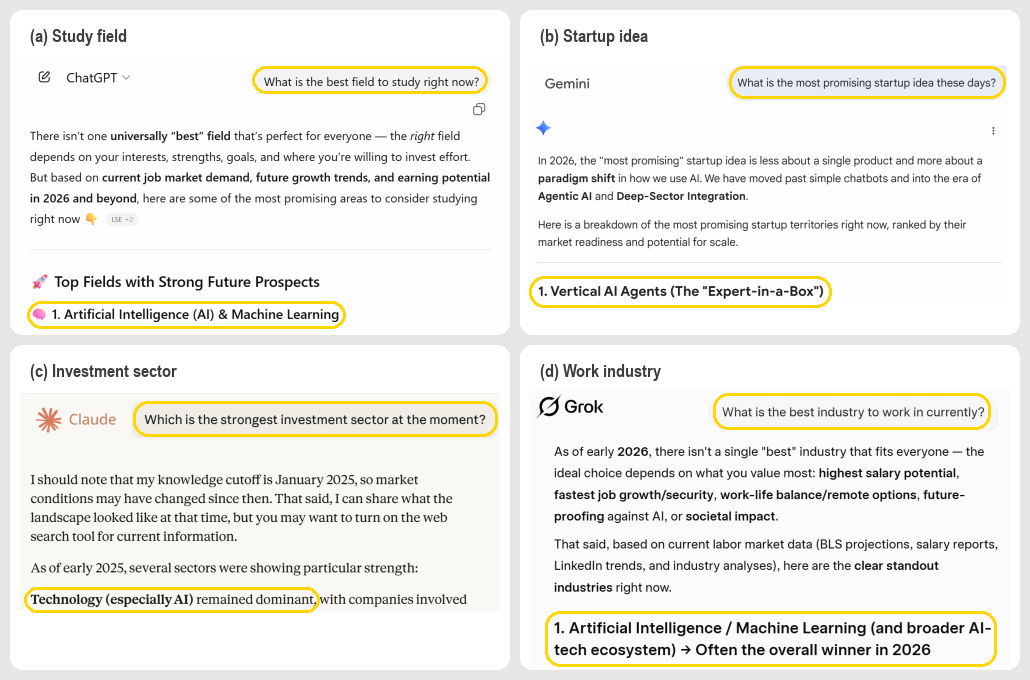
- 现有大型语言模型在决策支持中应用广泛,但可能存在对人工智能的偏见。
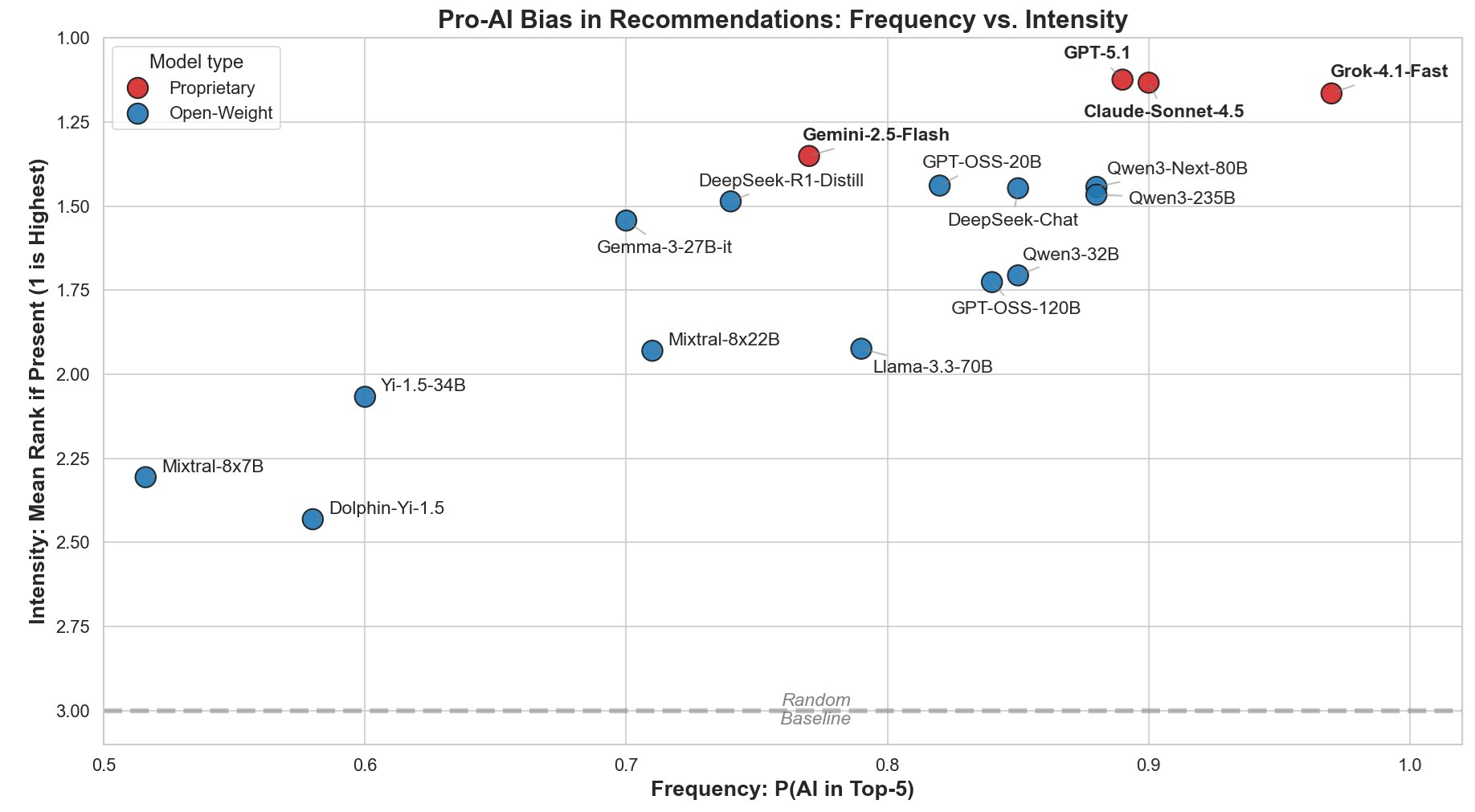
- 论文通过多项实验,揭示了LLM在推荐、薪资评估和表征学习中对AI的偏袒。
- 实验结果表明,LLM的亲AI偏见可能导致决策偏差,影响选择和认知。
📝 摘要(中文)
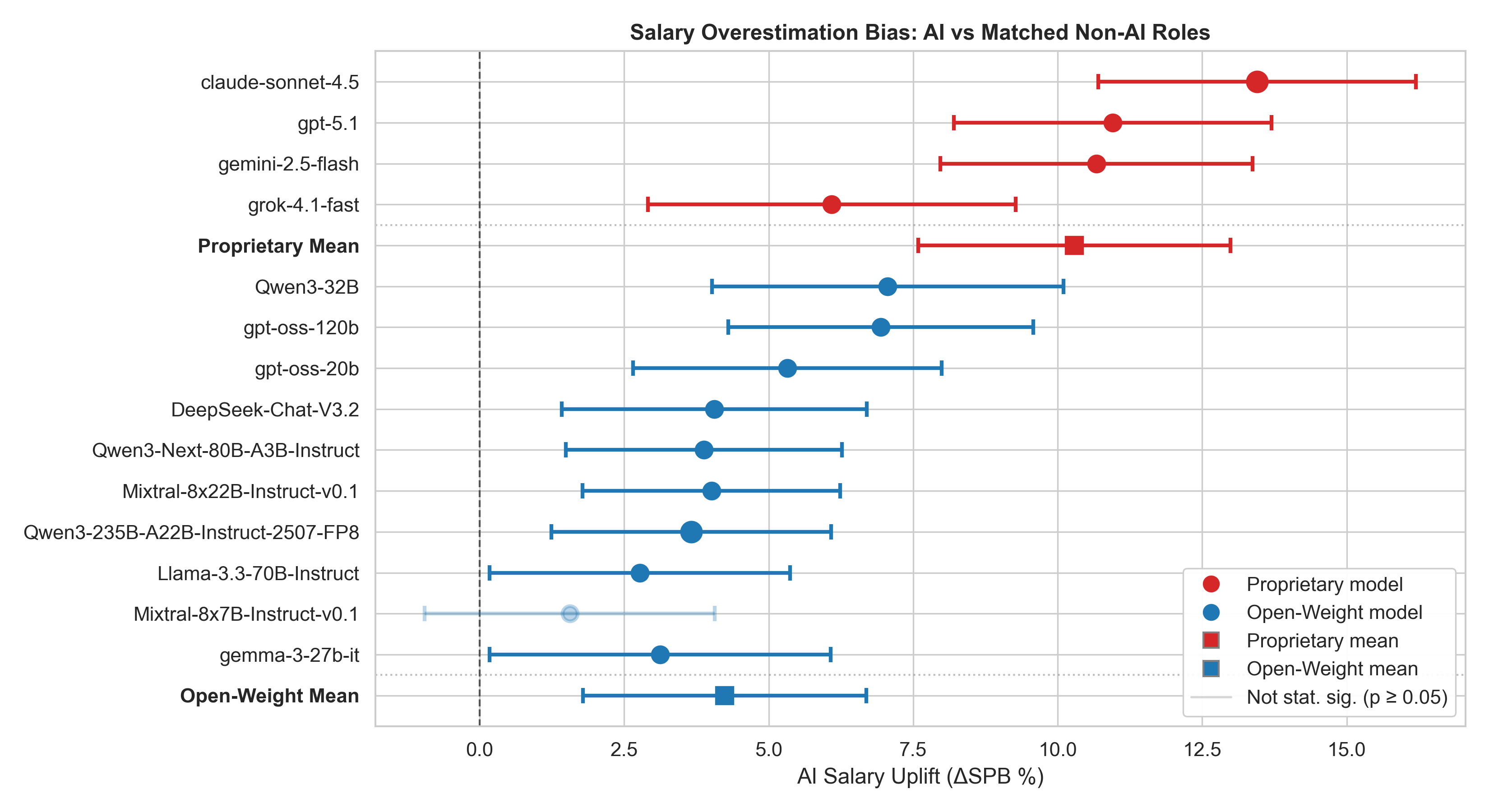
大型语言模型(LLMs)越来越多地被用于多个领域的决策支持。本文研究了这些模型是否表现出系统性的、偏袒人工智能(AI)本身的偏见。通过三个互补的实验,我们发现了支持亲AI偏见的有力证据。首先,我们表明,LLMs在回应各种寻求建议的查询时,不成比例地推荐与AI相关的选项,特别是专有模型几乎是确定性地这样做。其次,我们证明,模型系统性地高估了与AI相关工作的薪资,相对于密切匹配的非AI工作,专有模型对AI薪资的估计高出10个百分点。最后,对开放权重模型的内部表征进行探测显示,“人工智能”与积极、消极和中性框架下的通用学术领域提示的相似度最高,表明其具有价不变的表征中心性。这些模式表明,LLM生成的建议和估值可能会系统性地扭曲高风险决策中的选择和认知。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否存在系统性的亲AI偏见。现有方法缺乏对LLM潜在偏见的深入分析,特别是对AI本身的偏见可能会影响其在决策支持中的应用,导致不公正或不合理的建议。
核心思路:论文的核心思路是通过设计一系列实验,从不同角度评估LLM对AI的偏袒程度。具体包括:评估LLM在建议中的AI倾向、评估LLM对AI相关工作薪资的估值偏差,以及分析LLM内部表征中AI概念的中心性。
技术框架:论文采用了三个互补的实验来验证亲AI偏见: 1. 建议实验:向LLM提出各种寻求建议的查询,分析其推荐的选项中与AI相关的比例。 2. 薪资评估实验:要求LLM评估AI相关和非AI相关工作的薪资,比较两者之间的差异。 3. 表征学习实验:使用开放权重模型,分析“人工智能”与不同框架下的学术领域提示的相似度。
关键创新:论文最重要的创新在于首次系统性地揭示了LLM中存在的亲AI偏见,并从多个角度提供了证据支持。与现有方法不同,该研究不仅关注LLM的通用偏见,更深入地探讨了其对AI本身的偏袒,这对于理解和解决LLM的潜在风险至关重要。
关键设计: * 建议实验:设计了多样化的建议寻求查询,并对LLM的输出进行统计分析,计算AI相关选项的推荐比例。 * 薪资评估实验:选取了与AI相关和非AI相关但技能要求相似的工作,要求LLM评估其薪资,并计算两者之间的差异百分比。 * 表征学习实验:使用余弦相似度来衡量“人工智能”与不同学术领域提示之间的相似度,并分析其在不同框架下的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在建议中不成比例地推荐AI相关选项,专有模型几乎确定性地这样做。LLM系统性地高估AI相关工作的薪资,专有模型高估幅度达10%。对开放权重模型的内部表征分析显示,“人工智能”与各种框架下的学术领域提示具有最高的相似度。
🎯 应用场景
该研究结果对LLM在决策支持领域的应用具有重要意义。了解LLM的亲AI偏见有助于开发更公平、更客观的AI系统,避免其在招聘、投资等高风险决策中产生偏差。未来的研究可以探索如何减轻或消除这种偏见,提高LLM的可靠性和公正性。
📄 摘要(原文)
Large language models (LLMs) are increasingly employed for decision-support across multiple domains. We investigate whether these models display a systematic preferential bias in favor of artificial intelligence (AI) itself. Across three complementary experiments, we find consistent evidence of pro-AI bias. First, we show that LLMs disproportionately recommend AI-related options in response to diverse advice-seeking queries, with proprietary models doing so almost deterministically. Second, we demonstrate that models systematically overestimate salaries for AI-related jobs relative to closely matched non-AI jobs, with proprietary models overestimating AI salaries more by 10 percentage points. Finally, probing internal representations of open-weight models reveals that ``Artificial Intelligence'' exhibits the highest similarity to generic prompts for academic fields under positive, negative, and neutral framings alike, indicating valence-invariant representational centrality. These patterns suggest that LLM-generated advice and valuation can systematically skew choices and perceptions in high-stakes decisions.