Dimension-First Evaluation of Speech-to-Speech Models with Structured Acoustic Cues
作者: Arjun Chandra, Kevin Miller, Venkatesh Ravichandran, Constantinos Papayiannis, Venkatesh Saligrama
分类: cs.CL
发布日期: 2026-01-20
备注: EACL 2026 Findings
💡 一句话要点
提出TRACE框架以实现高效的人类对齐语音评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音评估 音频线索 大型语言模型 人类对齐 成本效益 维度评估 推理能力
📋 核心要点
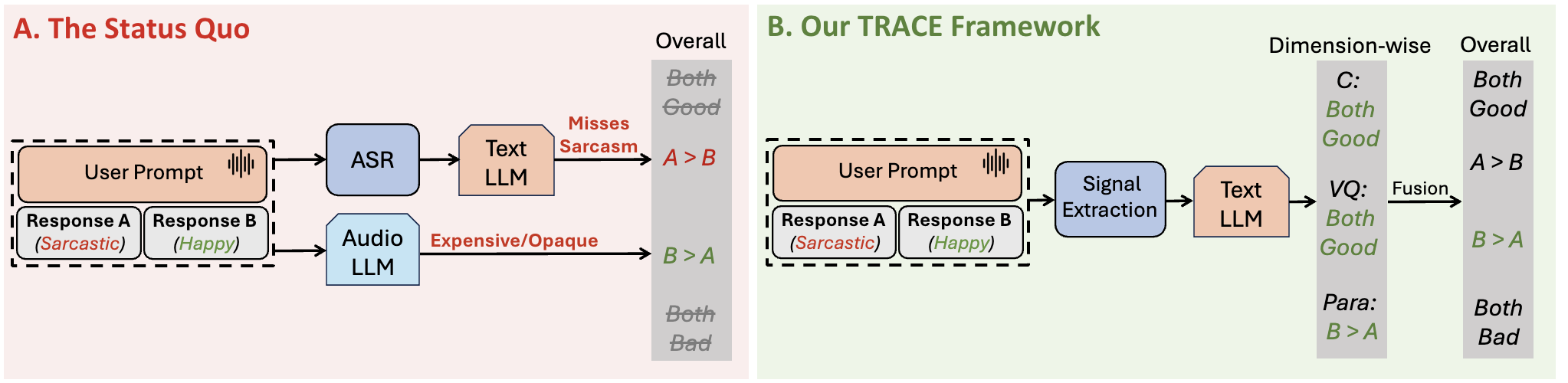
- 现有的自动语音到语音评估方法依赖于昂贵且不透明的音频语言模型,限制了其应用和效率。
- 本文提出TRACE框架,使大型语言模型能够基于音频线索进行推理,从而实现更高效的评估。
- TRACE在与人类评估者的协议一致性上优于现有方法,且在成本效益上具有显著优势。
📝 摘要(中文)
大型语言模型(LLM)在推理能力上表现出色,但仅限于文本内容,导致现有的自动语音到语音(S2S)评估方法依赖于不透明且昂贵的音频语言模型(ALM)。本文提出TRACE(基于音频线索的文本推理评估),一个新框架,使LLM能够对音频线索进行推理,从而实现成本效益高且与人类对齐的S2S评估。我们首先引入人类思维链(HCoT)注释协议,通过将评估分为内容、语音质量和副语言学等明确维度,提升现有评估基准的诊断能力。TRACE在与人类评估者的协议上优于ALM和仅基于转录的LLM评估,同时显著降低成本。我们将发布HCoT注释和TRACE框架,以实现可扩展且与人类对齐的S2S评估。
🔬 方法详解
问题定义:本文旨在解决现有自动语音到语音评估方法的局限性,特别是对昂贵和不透明的音频语言模型的依赖。
核心思路:TRACE框架通过引入音频线索的文本推理,使大型语言模型能够进行维度化的评估,从而提高评估的效率和准确性。
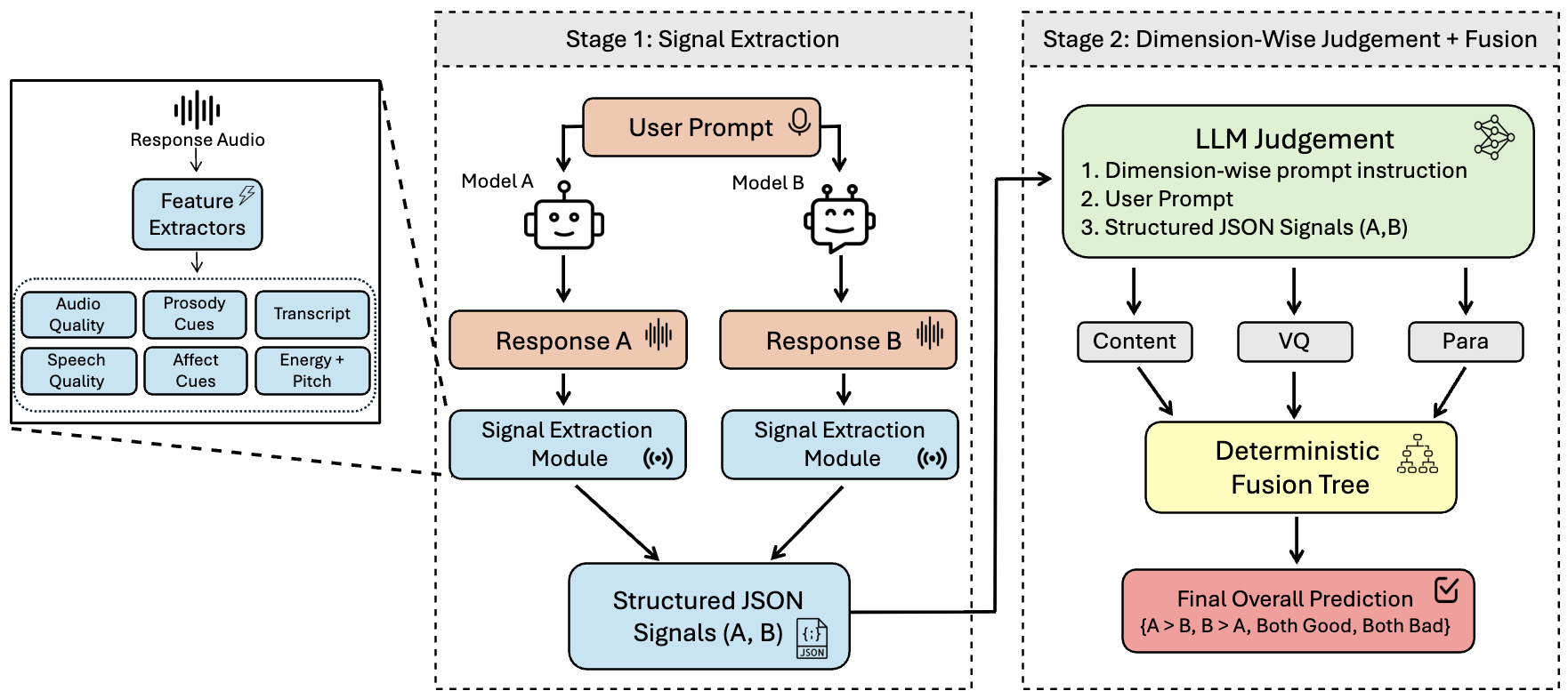
技术框架:TRACE的整体架构包括三个主要模块:人类思维链(HCoT)注释协议、音频信号的文本蓝图构建和基于确定性策略的维度评估整合。
关键创新:TRACE的核心创新在于将音频线索与文本推理结合,使得评估过程更透明且与人类评估者的判断更一致,这是与现有方法的本质区别。
关键设计:在设计中,TRACE使用了明确的评估维度(内容、语音质量、副语言学),并通过构建文本蓝图来简化音频信号的处理,确保评估的高效性和准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TRACE在与人类评估者的一致性上达到了更高的水平,相较于音频语言模型和仅基于转录的LLM评估,TRACE的成本效益显著提高,具体提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括语音助手、翻译系统和语音质量监测等。TRACE框架的实施将提升这些系统的评估能力,使其更好地与人类用户的期望对齐,进而推动语音技术的普及和发展。
📄 摘要(原文)
Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.