Towards robust long-context understanding of large language model via active recap learning
作者: Chenyu Hui
分类: cs.CL, cs.AI
发布日期: 2026-01-20
备注: 5 pages
💡 一句话要点
提出主动回顾学习(ARL)框架,增强LLM对长文本的理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大型语言模型 主动回顾学习 递归记忆 持续预训练
📋 核心要点
- 现有LLM在处理长文本时面临信息遗忘和理解困难的挑战,难以有效利用长距离依赖关系。
- ARL通过在预训练阶段构建回顾性摘要,并在推理阶段利用这些摘要,建立递归记忆机制,增强模型对长文本的理解。
- 实验结果表明,ARL在RULER和LongBench等长文本理解基准测试中取得了显著提升,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为主动回顾学习(ARL)的框架,旨在增强大型语言模型(LLM)对长文本的理解能力。ARL使模型能够在持续预训练期间通过有针对性的序列构建来回顾和总结早期内容,并在推理时进行回顾性总结。首先,我们基于长上下文和短上下文前向传播之间的损失差距,识别准备好的长文本中的关键token,并找到最相关的先前段落,然后使用LLM对其进行总结。其次,ARL使模型能够在推理过程中自主生成和利用这些回顾性摘要,从而建立跨段落的递归记忆机制。实验结果表明,ARL取得了显著的收益,在RULER上提高了26.8%,在LongBench上提高了9.44%。总而言之,ARL提供了一种简单而有效的基于持续预训练的方法来加强长文本理解,从而推进了LLM中可扩展的记忆增强。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,由于上下文长度限制和信息衰减,难以充分理解和利用文本中的长距离依赖关系。现有的方法要么依赖于扩展上下文窗口,要么采用外部记忆模块,但前者计算成本高昂,后者则可能引入额外的复杂性。
核心思路:ARL的核心思路是让模型在处理长文本时,能够主动回顾和总结先前的内容,从而建立一种递归的记忆机制。通过这种方式,模型可以更好地理解长文本中的上下文关系,并避免信息遗忘。
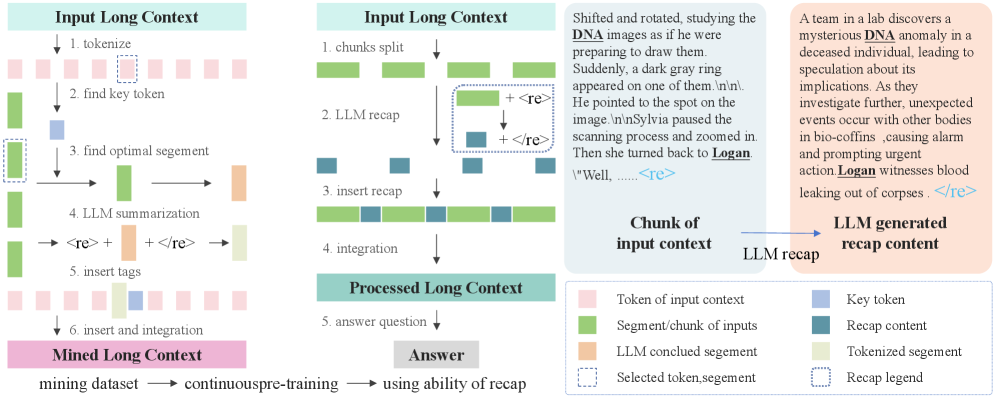
技术框架:ARL框架包含两个主要阶段:持续预训练和推理。在持续预训练阶段,首先基于损失差距识别长文本中的关键token,并找到相关的先前段落。然后,使用LLM对这些段落进行总结,生成回顾性摘要。在推理阶段,模型在处理每个段落时,都会利用之前生成的回顾性摘要,从而建立跨段落的记忆连接。
关键创新:ARL的关键创新在于其主动回顾和递归记忆机制。与传统的被动式长文本处理方法不同,ARL使模型能够主动地回顾和总结先前的内容,从而更好地理解长文本。此外,ARL的递归记忆机制允许模型在处理后续段落时,利用之前的信息,从而建立更强的上下文联系。
关键设计:ARL的关键设计包括:1) 基于损失差距的关键token识别方法,用于确定需要回顾的先前段落;2) 使用LLM生成回顾性摘要,确保摘要的质量和相关性;3) 在推理阶段,将回顾性摘要作为上下文输入到模型中,从而建立记忆连接。损失函数未知,网络结构沿用LLM本身。
🖼️ 关键图片
📊 实验亮点
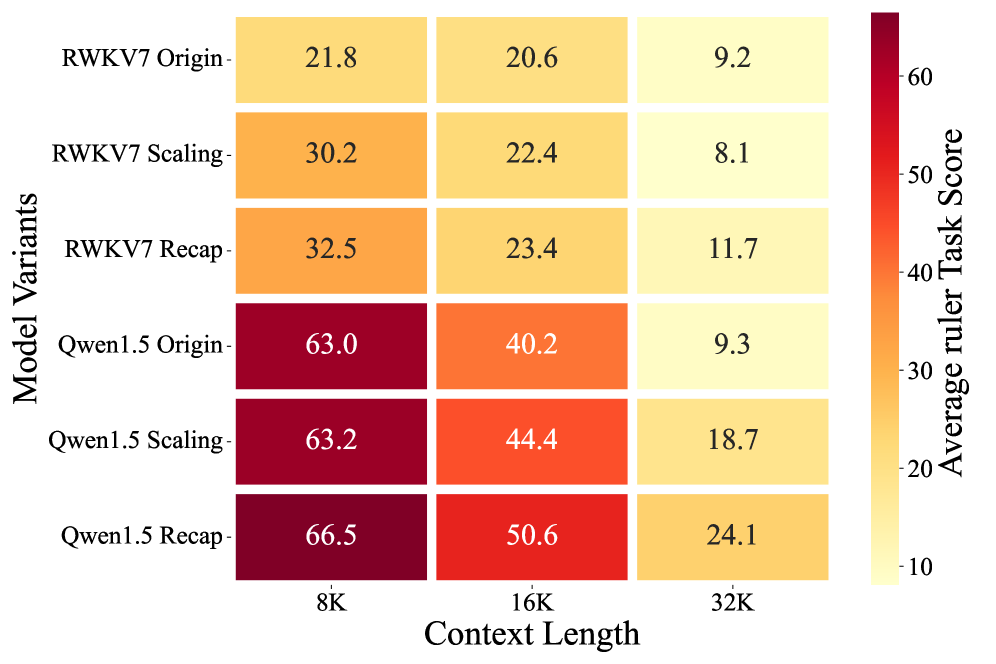
ARL在RULER数据集上取得了26.8%的显著提升,在LongBench数据集上取得了9.44%的提升。这些结果表明,ARL能够有效地增强LLM对长文本的理解能力,并在各种长文本理解任务中取得优异的性能。与现有方法相比,ARL具有更高的效率和更强的可扩展性。
🎯 应用场景
ARL可应用于需要处理长文本的各种场景,例如长篇文档摘要、法律文本分析、科学论文理解、以及需要长期记忆的对话系统等。该方法能够提升LLM在这些场景下的性能,使其能够更好地理解和利用长文本中的信息,具有广泛的应用前景。
📄 摘要(原文)
In this paper, we propose active recap learning (ARL), a framework for enhancing large language model (LLM) in understanding long contexts. ARL enables models to revisit and summarize earlier content through targeted sequence construction during contined pretraining and retrospective summarization at inference. First, we identify key tokens in prepared long context based on loss gaps between long and short forward contexts and find most revant preceding paragraphs, then summarize them using an LLM. Second, ARL equips models with the ability to autonomously generate and utilize these retrospective summaries during inference, thereby establishing a recursive memory mechanism across paragraphs. Experimental results show substantial gains, with ARL achieving a 26.8% improvement on RULER and a 9.44% improvement on LongBench. Overall, ARL offers a simple yet effective continued pretraining-based approach to strengthen long-context understanding, advancing scalable memory augmentation in LLM