Simulated Ignorance Fails: A Systematic Study of LLM Behaviors on Forecasting Problems Before Model Knowledge Cutoff
作者: Zehan Li, Yuxuan Wang, Ali El Lahib, Ying-Jieh Xia, Xinyu Pi
分类: cs.CL, cs.AI
发布日期: 2026-01-20
💡 一句话要点
揭示大语言模型预测中“模拟无知”的局限性,不建议用于回顾性基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预测 回顾性评估 模拟无知 知识截止日期
📋 核心要点
- 现有大语言模型的回顾性预测评估受限于模型知识截止日期,缺乏可靠的评估数据。
- 论文提出对“模拟无知”(SI)方法进行系统性测试,评估其是否能有效模拟“真实无知”(TI)。
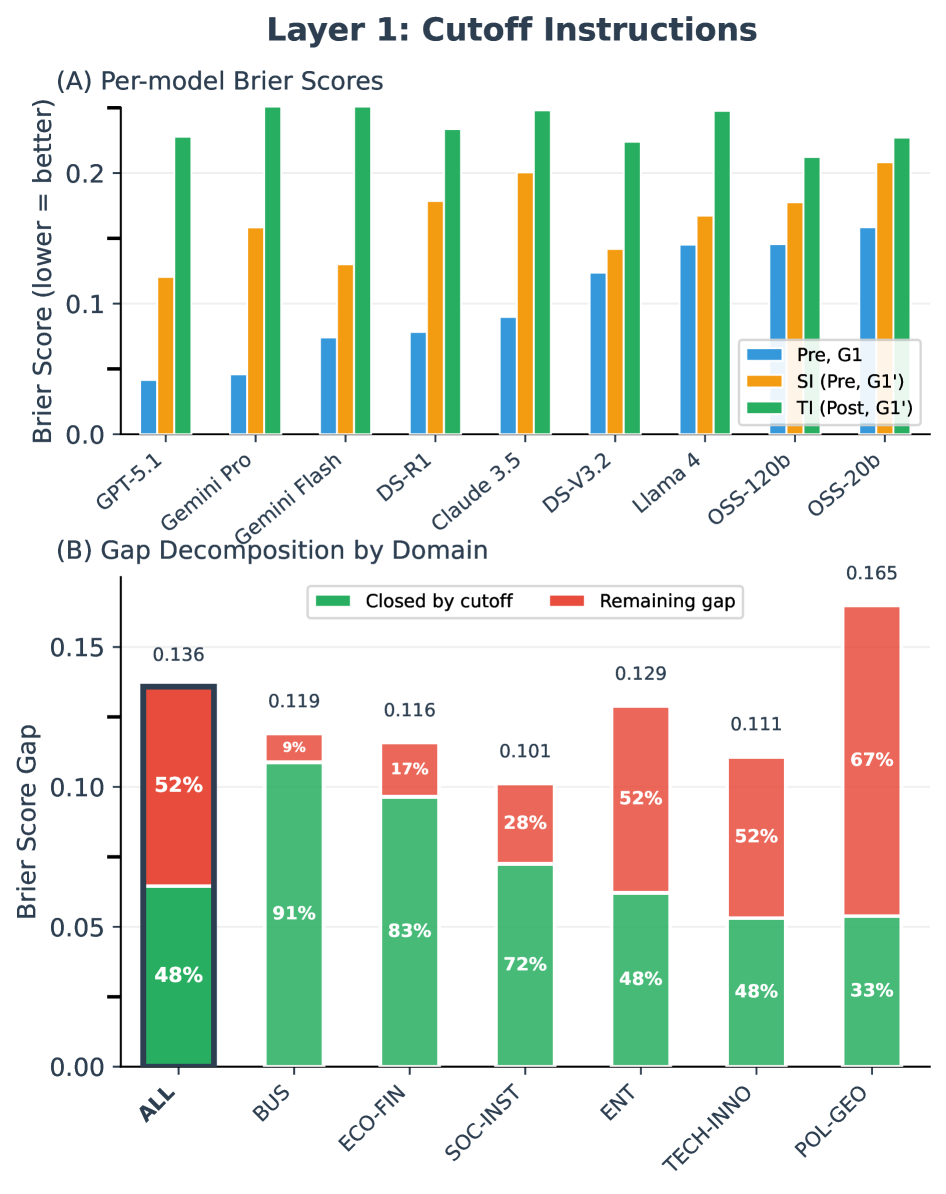
- 实验表明,SI无法有效抑制模型已有的知识,与真实无知存在显著性能差距,不建议用于回顾性预测评估。
📝 摘要(中文)
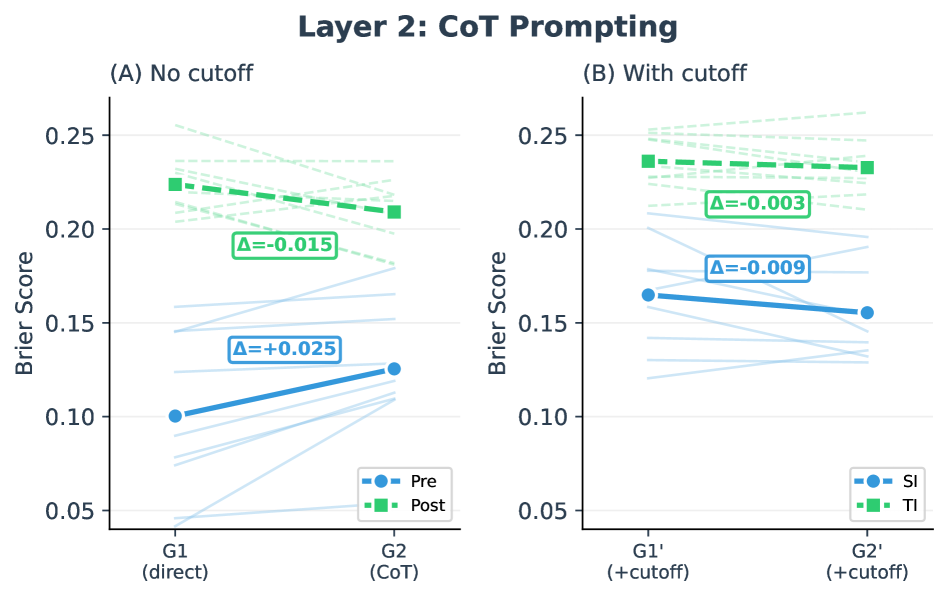
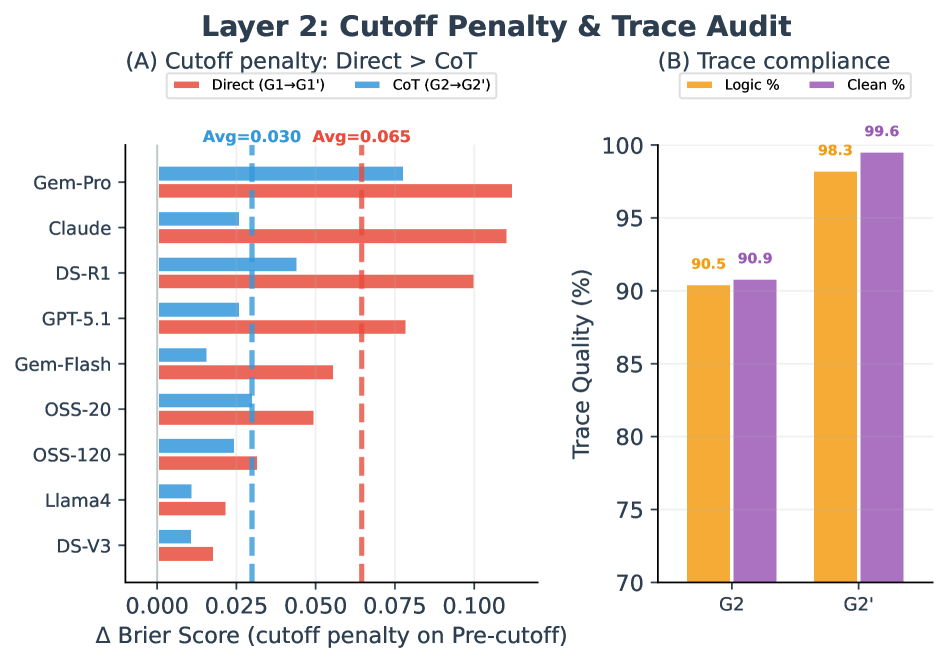
评估大语言模型(LLM)的预测能力面临根本矛盾:前瞻性评估方法严谨但耗时,而回顾性预测(RF)——评估已解决事件——因SOTA模型知识截止日期不断逼近而面临清洁评估数据迅速减少的问题。“模拟无知”(SI),即提示模型抑制截止日期前的知识,已成为一种潜在的解决方案。我们首次系统性地测试了SI是否能近似“真实无知”(TI)。在477个竞赛级别的问题和9个模型上,我们发现SI存在系统性缺陷:(1)截止日期指令导致SI和TI之间存在52%的性能差距;(2)即使推理过程不包含明确的截止日期后参考,思维链推理也无法抑制先验知识;(3)尽管推理轨迹质量更高,但推理优化模型表现出更差的SI保真度。这些发现表明,提示无法可靠地“倒带”模型知识。我们得出结论,对截止日期前事件进行RF在方法上存在缺陷;我们不建议使用基于SI的回顾性设置来评估预测能力。
🔬 方法详解
问题定义:论文旨在解决大语言模型在回顾性预测任务中,由于模型已经知晓答案而无法进行有效评估的问题。现有方法,如直接使用截止日期前的事件进行评估,面临着模型已经学习到相关知识的挑战。这使得评估结果无法真实反映模型在未知情况下的预测能力。
核心思路:论文的核心思路是系统性地评估一种名为“模拟无知”(Simulated Ignorance, SI)的方法。SI通过提示工程,要求模型在回答问题时假装不知道截止日期之后的信息,从而模拟模型在事件发生前的状态。论文旨在检验SI是否能够有效地近似“真实无知”(True Ignorance, TI),即模型在事件发生前确实不知道相关信息的状态。
技术框架:论文采用实验研究的方法,主要包含以下几个阶段: 1. 数据集构建:收集包含477个竞赛级别的问题,这些问题涵盖了不同的领域和时间范围。 2. 模型选择:选择9个不同的大语言模型,包括不同架构和训练方式的模型。 3. 提示工程:设计不同的提示策略,包括基本的截止日期指令和思维链推理提示,以引导模型进行“模拟无知”。 4. 评估指标:使用准确率等指标来衡量模型在SI和TI两种情况下的预测性能,并计算性能差距。 5. 结果分析:分析实验结果,比较不同模型和提示策略下的SI保真度,并探讨SI失败的原因。
关键创新:论文最重要的技术创新在于对“模拟无知”方法进行了系统性的、大规模的评估。之前的研究主要集中在个别案例或小规模实验上,而本文通过大量的实验数据,揭示了SI方法在实际应用中的局限性。此外,论文还深入分析了SI失败的原因,例如思维链推理无法有效抑制先验知识,以及推理优化模型反而表现出更差的SI保真度。
关键设计:论文的关键设计包括: 1. 截止日期指令:使用明确的指令告知模型截止日期,要求模型在回答问题时忽略截止日期之后的信息。 2. 思维链推理提示:引导模型进行逐步推理,希望通过推理过程来抑制先验知识的影响。 3. 对比实验:将SI的性能与TI的性能进行对比,以评估SI的保真度。 4. 模型多样性:选择不同架构和训练方式的模型,以评估SI的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,“模拟无知”(SI)与“真实无知”(TI)之间存在显著的性能差距,平均差距高达52%。即使采用思维链推理,也无法有效抑制模型已有的知识。更令人惊讶的是,推理优化模型在SI任务中表现出更差的保真度,这表明提升推理能力并不一定能改善SI的性能。
🎯 应用场景
该研究对大语言模型在预测领域的应用具有重要意义,尤其是在需要回顾性评估模型性能的场景中。研究结果表明,简单地通过提示来“倒带”模型知识是不可靠的,这对于设计更可靠的评估方法和开发更可控的语言模型具有指导意义。未来的研究可以探索更复杂的技术,例如知识擦除或对抗训练,来提高模型在回顾性预测任务中的性能。
📄 摘要(原文)
Evaluating LLM forecasting capabilities is constrained by a fundamental tension: prospective evaluation offers methodological rigor but prohibitive latency, while retrospective forecasting (RF) -- evaluating on already-resolved events -- faces rapidly shrinking clean evaluation data as SOTA models possess increasingly recent knowledge cutoffs. Simulated Ignorance (SI), prompting models to suppress pre-cutoff knowledge, has emerged as a potential solution. We provide the first systematic test of whether SI can approximate True Ignorance (TI). Across 477 competition-level questions and 9 models, we find that SI fails systematically: (1) cutoff instructions leave a 52% performance gap between SI and TI; (2) chain-of-thought reasoning fails to suppress prior knowledge, even when reasoning traces contain no explicit post-cutoff references; (3) reasoning-optimized models exhibit worse SI fidelity despite superior reasoning trace quality. These findings demonstrate that prompts cannot reliably "rewind" model knowledge. We conclude that RF on pre-cutoff events is methodologically flawed; we recommend against using SI-based retrospective setups to benchmark forecasting capabilities.