GerAV: Towards New Heights in German Authorship Verification using Fine-Tuned LLMs on a New Benchmark
作者: Lotta Kiefer, Christoph Leiter, Sotaro Takeshita, Elena Schmidt, Steffen Eger
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
提出GerAV:一个用于德语作者身份验证的新基准,并利用微调LLM达到新高度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 作者身份验证 德语 大型语言模型 基准数据集 微调
📋 核心要点
- 现有作者身份验证研究主要集中在英语数据上,缺乏针对其他语言的大规模基准和系统评估。
- 论文构建了包含超过60万文本对的德语作者身份验证基准GerAV,并进行了细致的数据集划分。
- 通过微调大型语言模型,在GerAV基准上取得了显著的性能提升,超越了现有基线和GPT-5。
📝 摘要(中文)
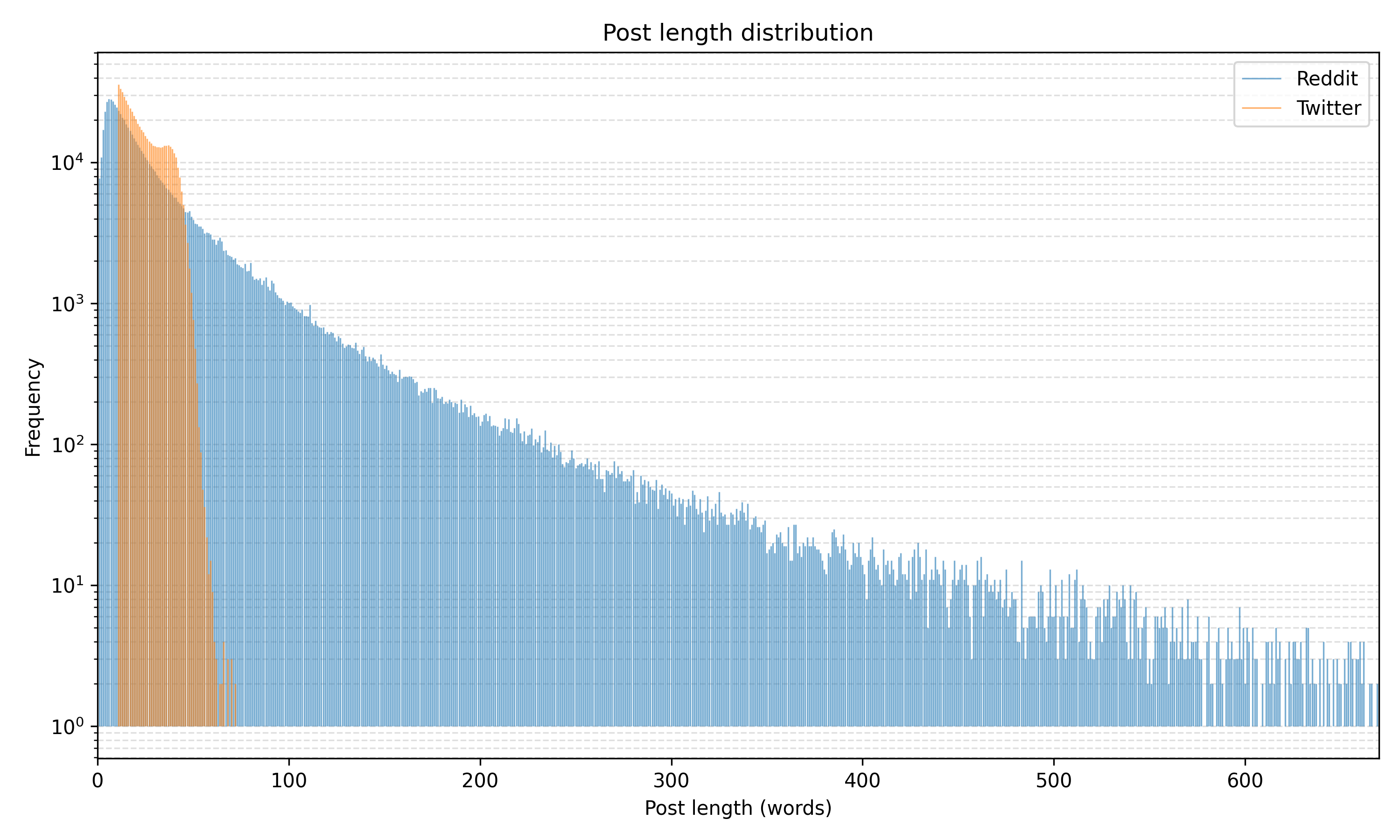
作者身份验证(AV)旨在确定两段文本是否由同一作者撰写,并且已被广泛研究,主要针对英语数据。相比之下,其他语言的大规模基准和系统评估仍然稀缺。我们通过引入GerAV来解决这一差距,GerAV是一个全面的德语AV基准,包含超过60万个带标签的文本对。GerAV由Twitter和Reddit数据构建,其中Reddit部分进一步分为领域内和跨领域的基于消息的子集,以及基于配置文件的子集。这种设计能够对数据源、主题领域和文本长度的影响进行受控分析。使用提供的训练集,我们对强大的基线和最先进的模型进行了系统评估,发现我们最好的方法,即微调的大型语言模型,比最近的基线高出高达0.09的绝对F1分数,并且在零样本设置中超过GPT-5 0.08。我们进一步观察到专业化和泛化之间的权衡:在特定数据类型上训练的模型在匹配条件下表现最佳,但在跨数据机制中的泛化能力较差,这种限制可以通过组合训练源来缓解。总的来说,GerAV为推进德语和跨领域AV的研究提供了一个具有挑战性和多功能的基准。
🔬 方法详解
问题定义:论文旨在解决德语作者身份验证(AV)任务中缺乏大规模基准数据集的问题。现有方法主要集中在英语数据上,无法直接应用于德语,并且缺乏对不同数据源、领域和文本长度的系统性分析。
核心思路:论文的核心思路是构建一个包含多种数据源(Twitter和Reddit)和领域(领域内和跨领域)的德语AV基准数据集GerAV,并利用微调的大型语言模型(LLM)在该基准上进行训练和评估。通过这种方式,可以系统地研究不同因素对AV性能的影响,并找到适用于德语AV的最佳模型。
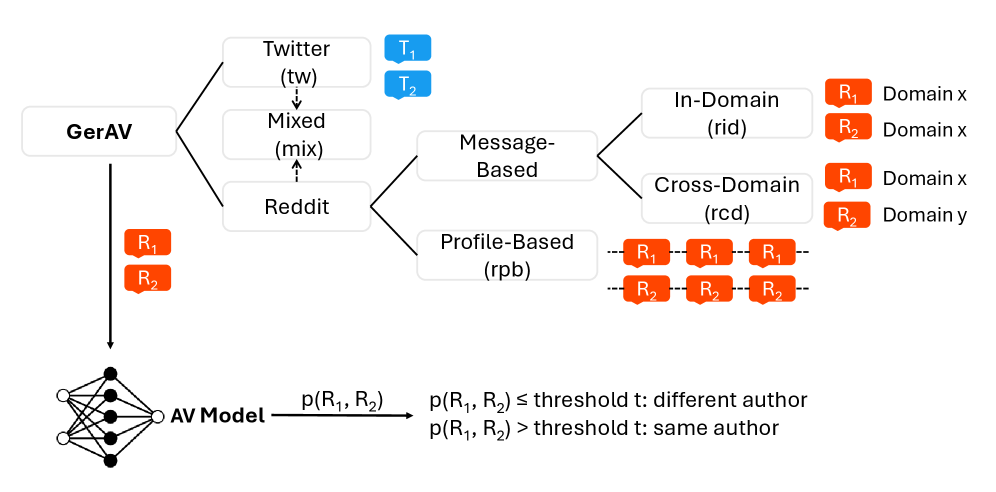
技术框架:整体框架包括以下几个主要步骤:1) 数据收集和预处理:从Twitter和Reddit收集德语文本数据,并进行清洗和标注。2) 数据集划分:将Reddit数据划分为领域内、跨领域和基于配置文件的子集。3) 模型选择和微调:选择合适的大型语言模型,并在GerAV数据集上进行微调。4) 实验评估:在GerAV数据集上评估微调模型的性能,并与现有基线进行比较。
关键创新:论文的关键创新在于构建了一个大规模、多样的德语作者身份验证基准数据集GerAV。该数据集包含多种数据源和领域,可以用于系统地研究不同因素对AV性能的影响。此外,论文还发现,微调的大型语言模型在GerAV基准上取得了显著的性能提升,超越了现有基线。
关键设计:论文的关键设计包括:1) 数据集划分策略:将Reddit数据划分为领域内、跨领域和基于配置文件的子集,以便研究领域对AV性能的影响。2) 模型微调策略:选择合适的大型语言模型,并使用GerAV数据集进行微调。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
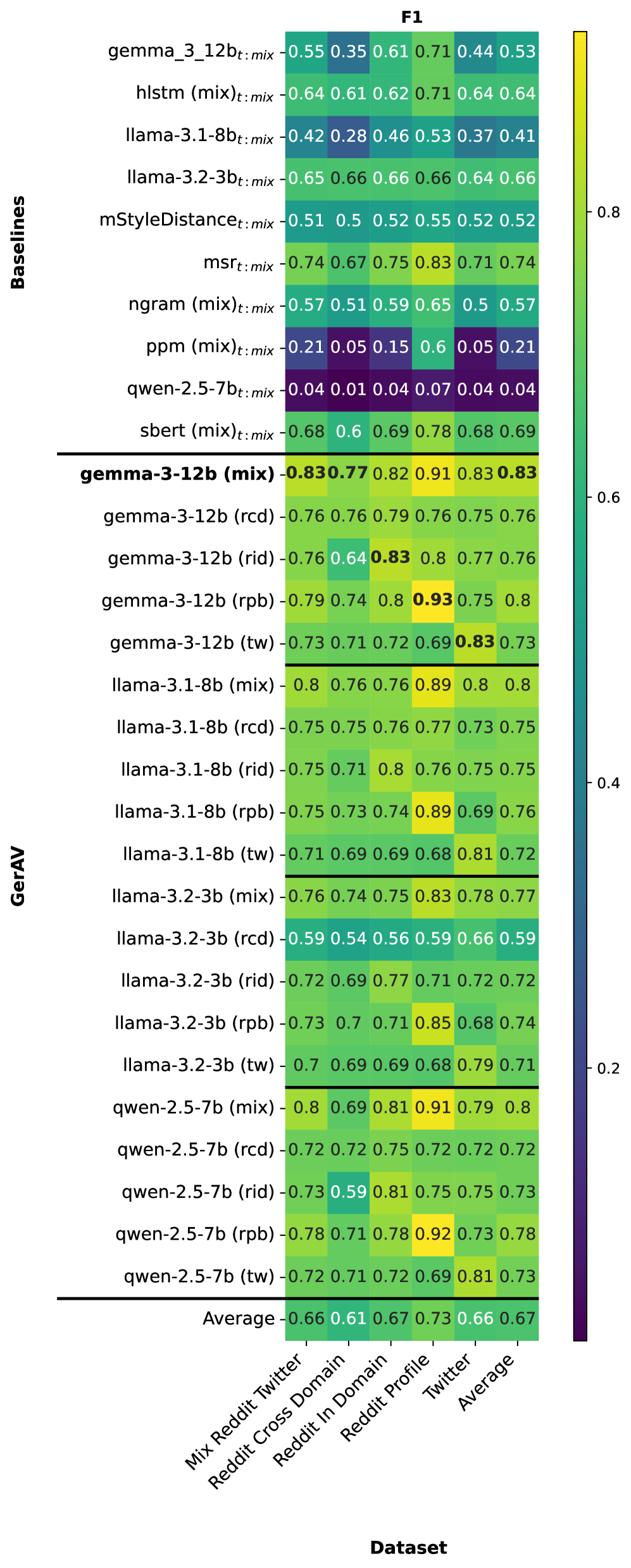
实验结果表明,微调的大型语言模型在GerAV基准上取得了显著的性能提升,比最近的基线高出高达0.09的绝对F1分数,并且在零样本设置中超过GPT-5 0.08。此外,研究还发现,在特定数据类型上训练的模型在匹配条件下表现最佳,但在跨数据机制中的泛化能力较差,可以通过组合训练源来缓解。
🎯 应用场景
该研究成果可应用于德语文本的作者身份识别、版权保护、网络安全等领域。例如,可以用于识别网络谣言的作者,追踪恶意信息的来源,以及验证在线内容的真实性。未来,该研究可以扩展到其他语言,并与其他自然语言处理技术相结合,以提高作者身份验证的准确性和可靠性。
📄 摘要(原文)
Authorship verification (AV) is the task of determining whether two texts were written by the same author and has been studied extensively, predominantly for English data. In contrast, large-scale benchmarks and systematic evaluations for other languages remain scarce. We address this gap by introducing GerAV, a comprehensive benchmark for German AV comprising over 600k labeled text pairs. GerAV is built from Twitter and Reddit data, with the Reddit part further divided into in-domain and cross-domain message-based subsets, as well as a profile-based subset. This design enables controlled analysis of the effects of data source, topical domain, and text length. Using the provided training splits, we conduct a systematic evaluation of strong baselines and state-of-the-art models and find that our best approach, a fine-tuned large language model, outperforms recent baselines by up to 0.09 absolute F1 score and surpasses GPT-5 in a zero-shot setting by 0.08. We further observe a trade-off between specialization and generalization: models trained on specific data types perform best under matching conditions but generalize less well across data regimes, a limitation that can be mitigated by combining training sources. Overall, GerAV provides a challenging and versatile benchmark for advancing research on German and cross-domain AV.