Uncertainty-Aware Gradient Signal-to-Noise Data Selection for Instruction Tuning
作者: Zhihang Yuan, Chengyu Yue, Long Huang, Litu Ou, Lei Shi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-20
备注: Preprint
💡 一句话要点
提出GRADFILTERING,利用不确定性指导指令调优数据选择,提升LLM效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 数据选择 不确定性感知 梯度信噪比 大型语言模型
📋 核心要点
- 现有指令调优数据选择方法忽略了模型训练过程中不确定性的变化,导致选择的数据质量不高。
- GRADFILTERING利用小型GPT-2代理和LoRA集成,通过梯度信噪比(G-SNR)来衡量数据效用,实现不确定性感知的数据选择。
- 实验表明,GRADFILTERING在LLM评估和人工评估中表现优异,且在相同计算资源下收敛速度更快。
📝 摘要(中文)
指令调优是调整大型语言模型(LLMs)的标准范式,但现代指令数据集庞大、嘈杂且冗余,导致全数据微调成本高昂且常常不必要。现有的数据选择方法要么构建昂贵的梯度数据存储,要么从弱代理分配静态分数,很大程度上忽略了不断变化的不确定性,从而错失了LLM可解释性的关键来源。我们提出了GRADFILTERING,一个目标无关、不确定性感知的数据选择框架,它利用带有LoRA集成的GPT-2代理,并将每个样本的梯度聚合为梯度信噪比(G-SNR)效用。在大多数LLM-as-a-judge评估以及人工评估中,我们的方法与随机子集和强大的基线相匹配或超过它们。此外,在相同的计算预算下,GRADFILTERING选择的子集比竞争性过滤器收敛得更快,反映了不确定性感知评分的优势。
🔬 方法详解
问题定义:指令调优中,全量数据微调LLM成本高昂且效率低下。现有数据选择方法,如基于梯度数据存储或静态评分,忽略了训练过程中模型不确定性的动态变化,导致选择的数据并非最优,影响模型性能。
核心思路:核心在于利用模型训练过程中的不确定性来指导数据选择。通过计算每个样本的梯度信噪比(G-SNR),可以量化该样本对于模型学习的价值,从而优先选择对模型提升最大的数据。
技术框架:GRADFILTERING框架主要包含以下几个阶段:1) 使用小型GPT-2模型作为代理模型;2) 使用LoRA集成来估计模型的不确定性;3) 计算每个样本的梯度,并将其聚合为梯度信噪比(G-SNR);4) 根据G-SNR选择数据子集进行指令调优。
关键创新:最重要的创新点在于引入了不确定性感知的数据选择机制。传统的静态评分方法无法捕捉模型在训练过程中的动态变化,而GRADFILTERING通过G-SNR动态评估每个样本的价值,从而更有效地选择数据。
关键设计:关键设计包括:1) 使用GPT-2作为代理模型,降低计算成本;2) 使用LoRA集成来估计模型的不确定性,提高G-SNR的准确性;3) G-SNR的计算方式,平衡了梯度的大小和噪声的影响,从而更准确地评估样本的价值。具体G-SNR的计算公式未知,论文中可能未详细公开。
🖼️ 关键图片
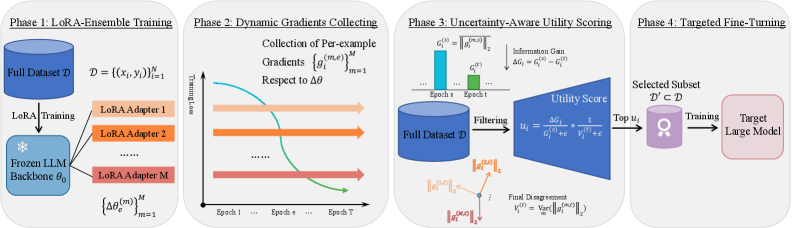
📊 实验亮点
实验结果表明,GRADFILTERING在LLM-as-a-judge评估和人工评估中,性能与随机子集和强大的基线方法相当甚至超越。更重要的是,在相同的计算预算下,GRADFILTERING选择的数据子集收敛速度更快,证明了不确定性感知评分的有效性。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
GRADFILTERING可应用于各种指令调优场景,尤其是在数据量大、计算资源有限的情况下。它可以帮助研究人员和工程师更高效地训练LLM,降低训练成本,并提高模型性能。该方法还可用于主动学习等领域,选择最具信息量的样本进行标注。
📄 摘要(原文)
Instruction tuning is a standard paradigm for adapting large language models (LLMs), but modern instruction datasets are large, noisy, and redundant, making full-data fine-tuning costly and often unnecessary. Existing data selection methods either build expensive gradient datastores or assign static scores from a weak proxy, largely ignoring evolving uncertainty, and thus missing a key source of LLM interpretability. We propose GRADFILTERING, an objective-agnostic, uncertainty-aware data selection framework that utilizes a small GPT-2 proxy with a LoRA ensemble and aggregates per-example gradients into a Gradient Signal-to-Noise Ratio (G-SNR) utility. Our method matches or surpasses random subsets and strong baselines in most LLM-as-a-judge evaluations as well as in human assessment. Moreover, GRADFILTERING-selected subsets converge faster than competitive filters under the same compute budget, reflecting the benefit of uncertainty-aware scoring.