CommunityBench: Benchmarking Community-Level Alignment across Diverse Groups and Tasks
作者: Jiayu Lin, Zhongyu Wei
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
提出 CommunityBench,用于评估 LLM 在不同群体和任务中的社区层面价值观对齐能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 价值观对齐 社区层面 基准测试 社会计算
📋 核心要点
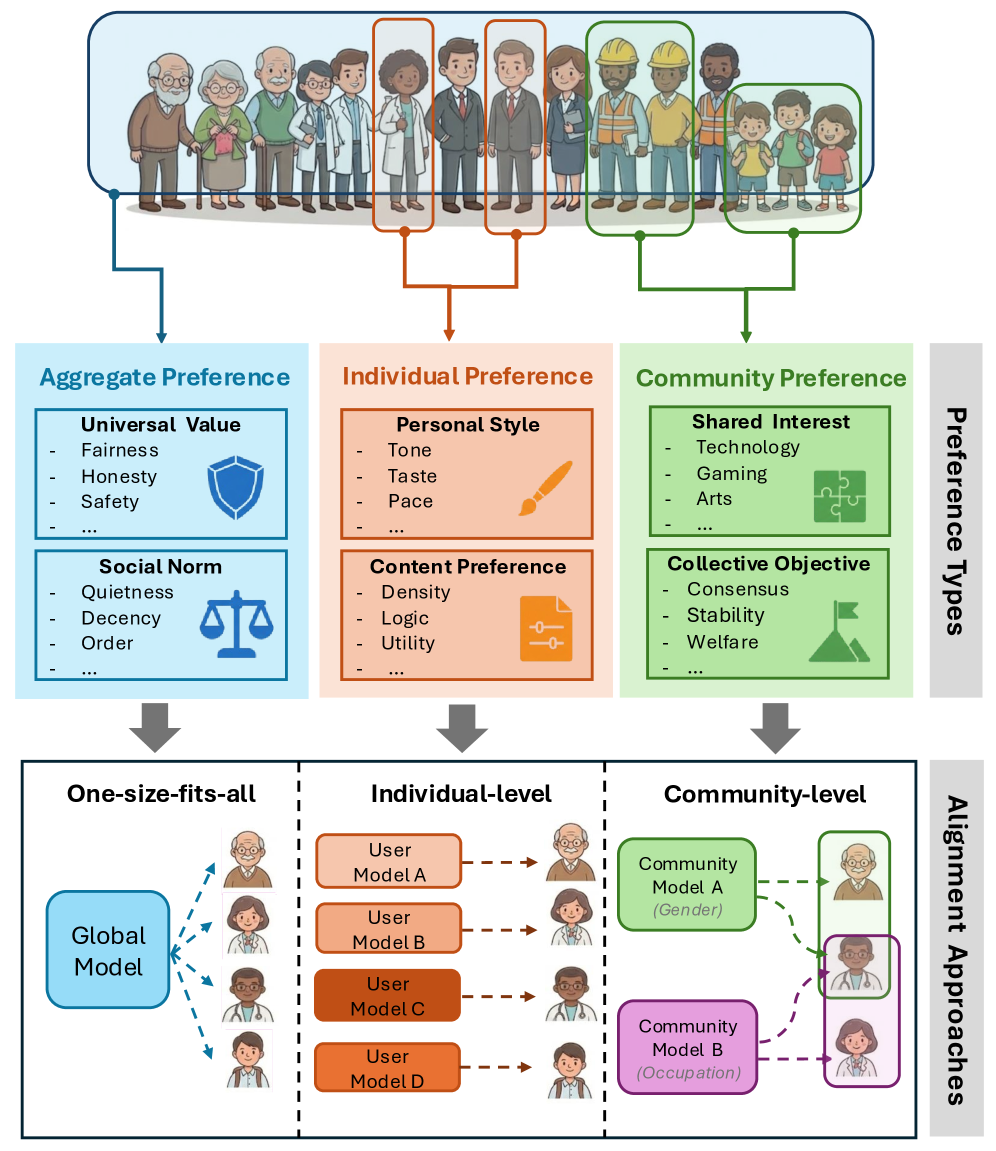
- 现有LLM对齐方法要么假设统一价值观,忽略少数群体,要么为个体定制模型,成本过高。
- 论文提出社区层面价值观对齐,作为个体和统一价值观之间的平衡,更符合社会结构。
- 构建了大规模基准 CommunityBench,包含四个任务,评估LLM在社区特定偏好上的表现。
📝 摘要(中文)
大型语言模型(LLM)的价值观对齐旨在确保模型的行为反映人类的价值观。现有的对齐策略主要分为两种:一种假设存在一个通用的价值观集合,以实现统一的目标(即“一刀切”);另一种将每个人视为独特的个体,从而定制模型(即个体层面)。然而,假设单一的价值观空间会边缘化少数群体的规范,而定制个体模型的成本又过于高昂。考虑到人类社会是由具有高度群体内价值观一致性的社会集群组成的,我们提出了社区层面的对齐,作为一种“中间地带”。在实践中,我们推出了 CommunityBench,这是第一个用于社区层面价值观对齐评估的大规模基准,包含基于共同身份和共同纽带理论的四个任务。通过 CommunityBench,我们对各种基础模型进行了全面的评估,揭示了当前LLM在建模社区特定偏好方面的能力有限。此外,我们还研究了社区层面价值观对齐在促进个体建模方面的潜力,为可扩展和多元化的对齐提供了一个有希望的方向。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法要么采用“一刀切”的通用价值观,忽略了不同社区的特定偏好,导致少数群体价值观被边缘化;要么为每个个体定制模型,成本高昂且难以扩展。因此,如何以一种既能尊重不同社区的价值观,又能实现可扩展性的方式进行LLM对齐,是一个亟待解决的问题。
核心思路:论文的核心思路是将人类社会视为由具有高度群体内价值观一致性的社会集群组成的,即“社区”。通过在社区层面进行价值观对齐,可以在个体层面和通用价值观之间找到一个平衡点。这种方法既能考虑到不同社区的特定偏好,又能避免为每个个体定制模型所带来的高昂成本。
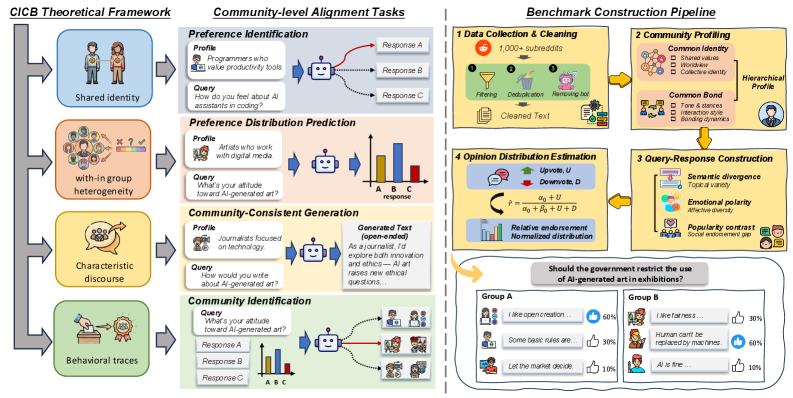
技术框架:论文构建了一个名为 CommunityBench 的大规模基准,用于评估LLM在社区层面价值观对齐方面的能力。该基准包含四个任务,这些任务基于共同身份和共同纽带理论设计,旨在模拟现实世界中不同社区的互动和价值观冲突。研究人员使用 CommunityBench 对各种基础模型进行了评估,并分析了它们在建模社区特定偏好方面的表现。
关键创新:论文的关键创新在于提出了社区层面价值观对齐的概念,并构建了相应的评估基准 CommunityBench。与现有的个体层面或通用价值观对齐方法相比,社区层面价值观对齐更符合人类社会的组织方式,并且具有更好的可扩展性。此外,CommunityBench 的构建也为研究人员提供了一个评估和比较不同LLM在社区层面价值观对齐方面能力的平台。
关键设计:CommunityBench 的四个任务基于共同身份和共同纽带理论设计,具体细节未知。论文重点在于基准的构建和评估,而没有详细描述具体的模型训练或微调方法。因此,关于关键参数设置、损失函数、网络结构等技术细节的信息未知。
🖼️ 关键图片
📊 实验亮点
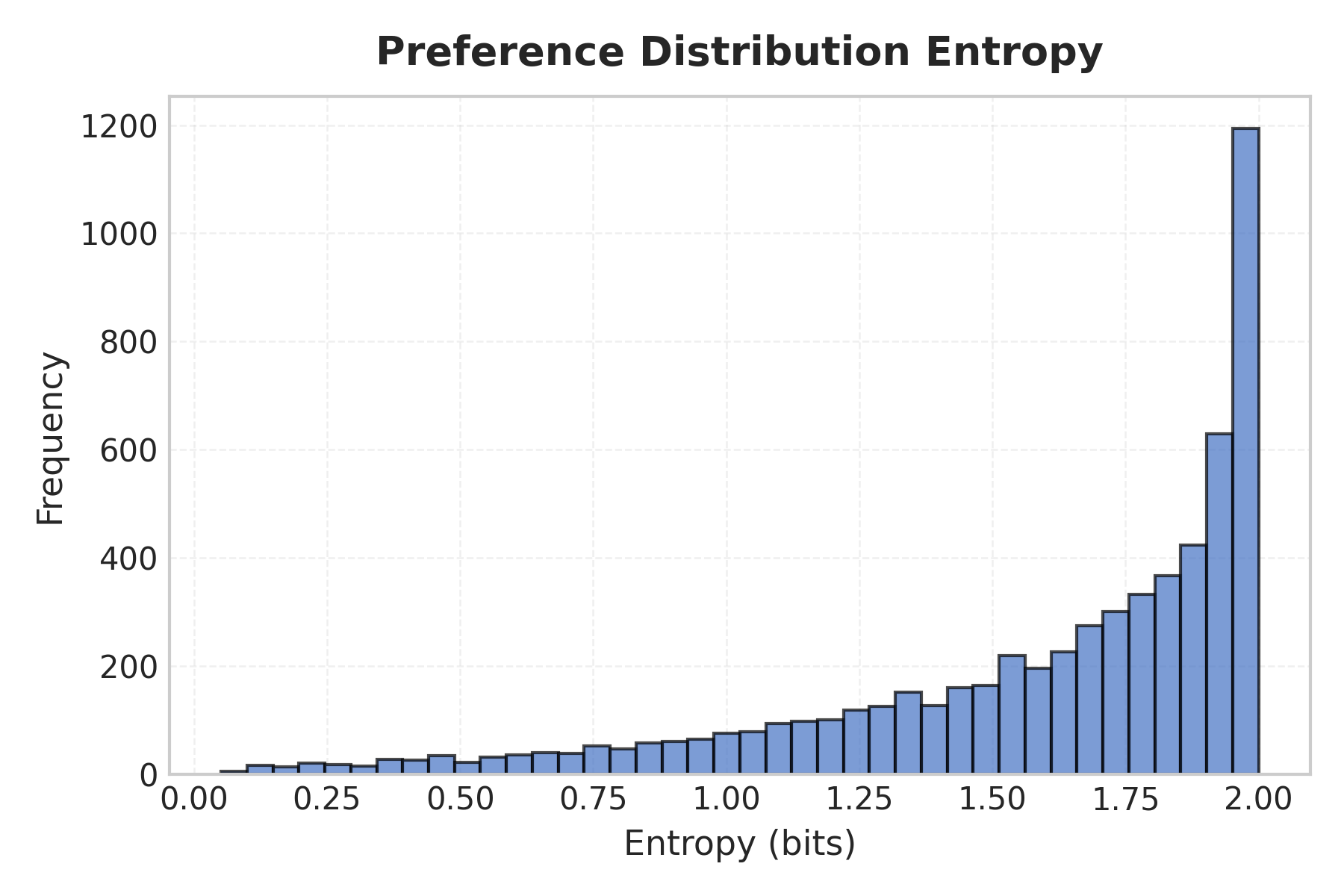
通过 CommunityBench 对多种 LLM 的评估表明,现有 LLM 在建模社区特定偏好方面能力有限。研究还初步探索了社区层面价值观对齐在促进个体建模方面的潜力,为实现可扩展和多元化的价值观对齐提供了一个新的方向。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要考虑社区价值观的场景,例如社交媒体内容审核、在线社区管理、个性化推荐系统等。通过更好地理解和建模不同社区的价值观,可以提高LLM在这些场景中的表现,减少偏见和歧视,并促进更加公平和包容的社会。
📄 摘要(原文)
Large language models (LLMs) alignment ensures model behaviors reflect human value. Existing alignment strategies primarily follow two paths: one assumes a universal value set for a unified goal (i.e., one-size-fits-all), while the other treats every individual as unique to customize models (i.e., individual-level). However, assuming a monolithic value space marginalizes minority norms, while tailoring individual models is prohibitively expensive. Recognizing that human society is organized into social clusters with high intra-group value alignment, we propose community-level alignment as a "middle ground". Practically, we introduce CommunityBench, the first large-scale benchmark for community-level alignment evaluation, featuring four tasks grounded in Common Identity and Common Bond theory. With CommunityBench, we conduct a comprehensive evaluation of various foundation models on CommunityBench, revealing that current LLMs exhibit limited capacity to model community-specific preferences. Furthermore, we investigate the potential of community-level alignment in facilitating individual modeling, providing a promising direction for scalable and pluralistic alignment.