Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
作者: Xiaolin Zhou, Zheng Luo, Yicheng Gao, Qixuan Chen, Xiyang Hu, Yue Zhao, Ruishan Liu
分类: cs.CL, cs.AI
发布日期: 2026-01-20
💡 一句话要点
研究发现成对LLM评判器存在显著的语言偏见,并分析了其与困惑度的关系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评判器 语言偏见 公平性 困惑度 多语言 自然语言处理 文本质量评估
📋 核心要点
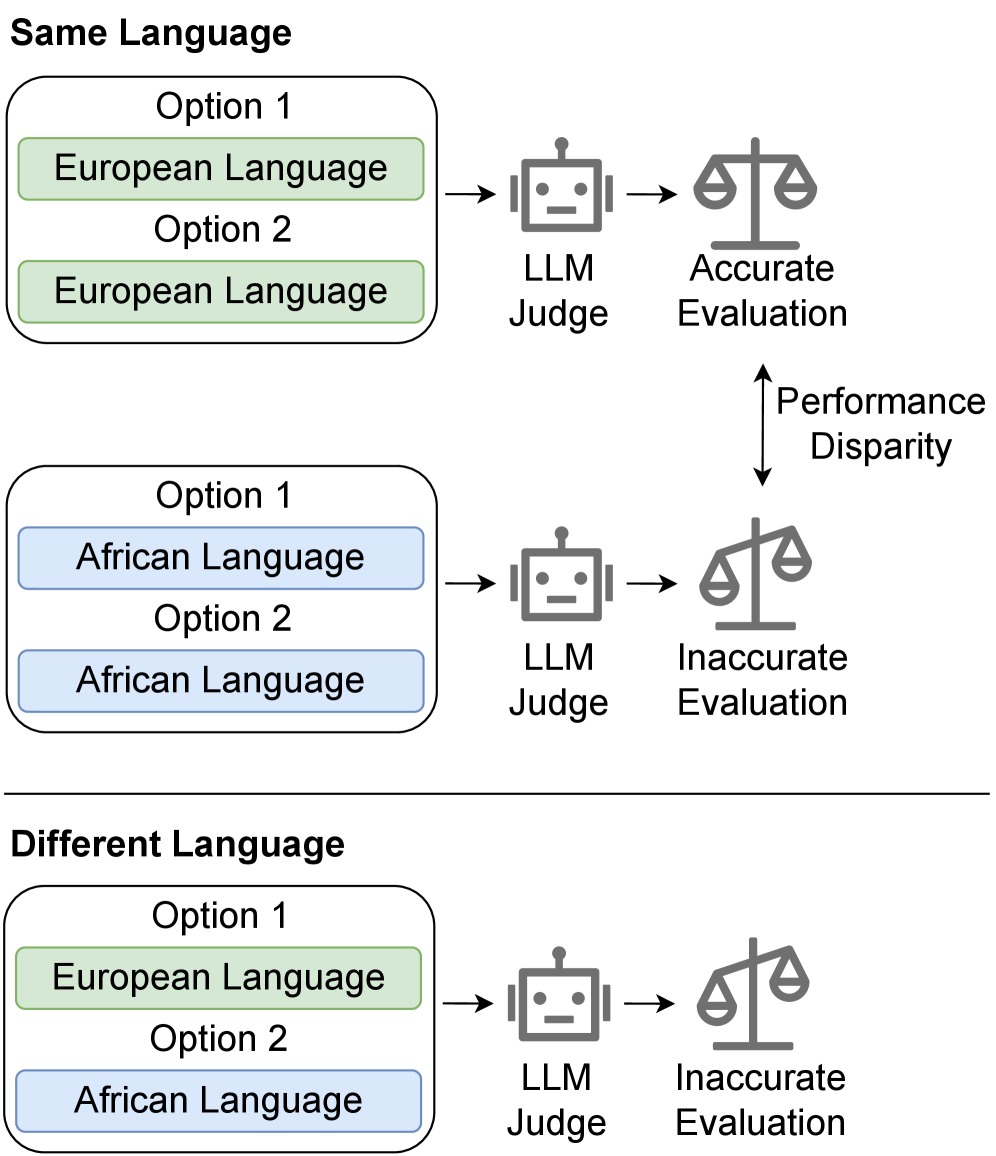
- 现有研究表明,LLM评判器存在语言偏见,影响其在不同语言文本质量评估中的准确性,与人类偏好不符。
- 该研究深入分析了同语言和跨语言两种场景下的语言偏见,探究了语言偏见与低困惑度偏见之间的关系。
- 实验结果表明,LLM评判器在同语言评判中对欧洲语言存在偏好,跨语言评判中偏好英语,且语言偏见不能完全由困惑度解释。
📝 摘要(中文)
大型语言模型(LLM)的最新进展推动了LLM评判器的发展,该应用将LLM用作评判者,以根据特定上下文判断文本的质量。然而,先前的研究表明,LLM评判器可能对被评判文本的不同方面存在偏见,这些偏见通常与人类偏好不一致。其中一种已知的偏见是语言偏见,这意味着LLM评判器的决策可能因被评判文本的语言而异。本文研究了成对LLM评判器中的两种语言偏见:(1)当提示评判器比较来自同一种语言的选项时,不同语言之间的性能差异;(2)当提示评判器比较两种不同语言的选项时,对主要语言编写的选项的偏好。我们发现,对于同语言评判,不同语系之间存在显著的性能差异,欧洲语言始终优于非洲语言,并且这种偏见在文化相关主题中更为明显。对于跨语言评判,我们观察到大多数模型偏爱英语答案,并且这种偏好更多地受到答案语言的影响,而不是问题语言的影响。最后,我们研究了语言偏见是否实际上是由低困惑度偏见引起的,这是先前已知的LLM评判器的一种偏见,我们发现虽然困惑度与语言偏见略有相关,但语言偏见不能完全用困惑度来解释。
🔬 方法详解
问题定义:论文旨在解决LLM作为评判器时存在的语言偏见问题。现有方法在评估不同语言文本质量时,由于语言本身的影响,导致评判结果与人类认知存在偏差,影响了LLM评判器的公平性和可靠性。
核心思路:论文的核心思路是系统性地研究LLM评判器在同语言和跨语言场景下的语言偏见,并探究语言偏见与低困惑度偏见之间的关系。通过控制变量,分析不同语言、语系以及问题和答案语言对评判结果的影响,从而揭示语言偏见的内在机制。
技术框架:该研究主要分为三个阶段:1) 同语言评判:评估LLM在比较同一语言的不同文本时的性能差异,重点关注不同语系之间的差异。2) 跨语言评判:评估LLM在比较不同语言的文本时的偏好,分析问题和答案语言对评判结果的影响。3) 困惑度分析:研究语言偏见与低困惑度偏见之间的关系,通过计算文本的困惑度,分析其与LLM评判结果的相关性。
关键创新:该研究的创新点在于:1) 系统性地研究了LLM评判器在同语言和跨语言场景下的语言偏见,揭示了不同语言和语系对评判结果的影响。2) 探究了语言偏见与低困惑度偏见之间的关系,发现语言偏见不能完全由困惑度解释,表明其背后可能存在更复杂的机制。
关键设计:在实验设计方面,论文采用了成对比较的方式,让LLM评判器在两个文本中选择更优的一个。针对同语言评判,选择了不同语系的语言进行对比,并控制了文本的主题。针对跨语言评判,分别测试了不同问题和答案语言的组合。在困惑度分析方面,使用了预训练语言模型计算文本的困惑度,并分析其与LLM评判结果的相关性。
🖼️ 关键图片

📊 实验亮点
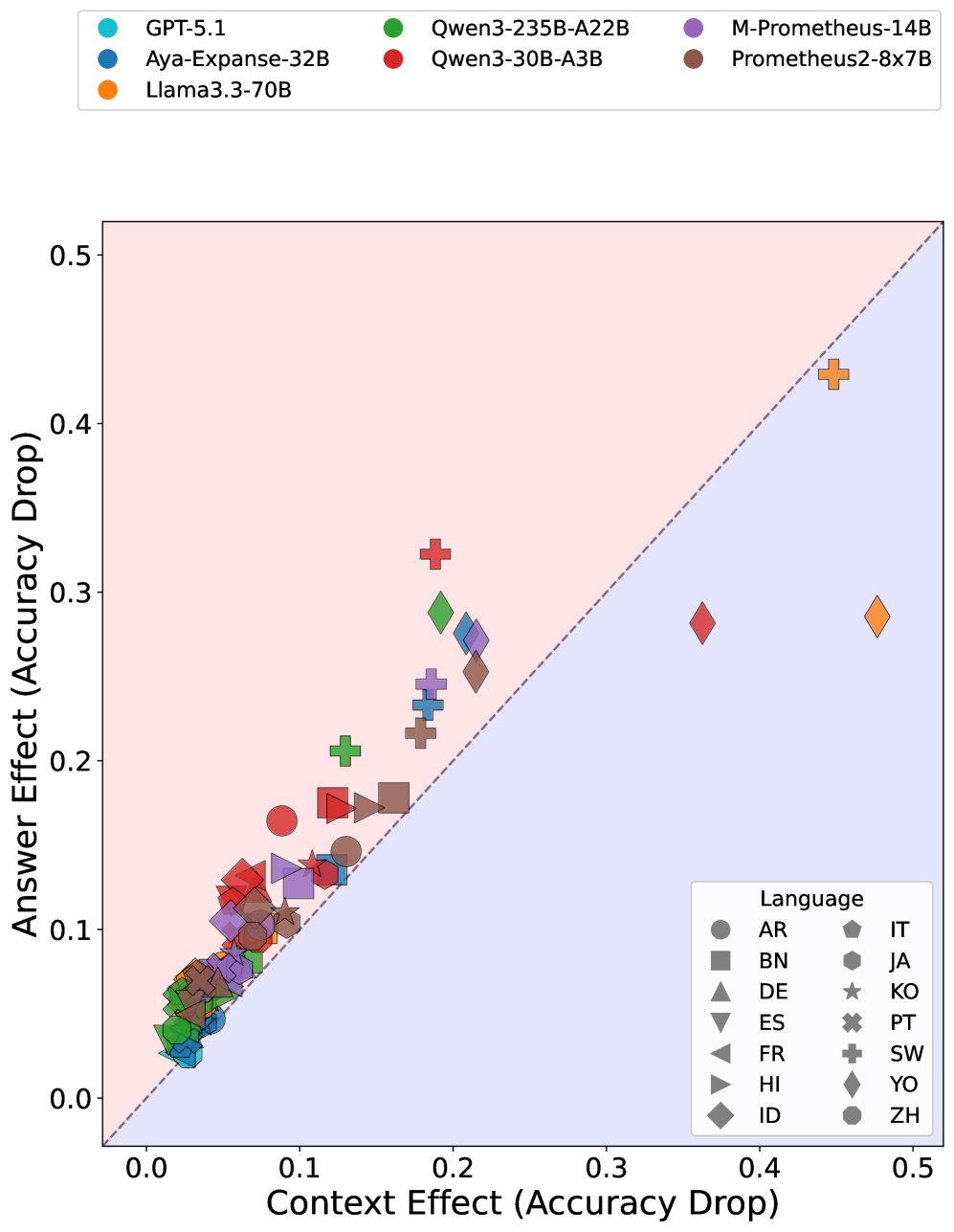
实验结果表明,在同语言评判中,LLM评判器对欧洲语言存在显著偏好,性能优于非洲语言。在跨语言评判中,大多数模型偏爱英语答案,且答案语言的影响大于问题语言。困惑度分析表明,语言偏见与困惑度存在一定相关性,但不能完全解释语言偏见。
🎯 应用场景
该研究成果可应用于提升LLM评判器在多语言环境下的公平性和可靠性,例如在多语言机器翻译评估、跨语言文本生成质量评估等领域。通过消除或减轻语言偏见,可以提高LLM评判器在不同语言场景下的实用价值,并促进更公平、更可靠的AI系统发展。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.