Activation-Space Anchored Access Control for Multi-Class Permission Reasoning in Large Language Models
作者: Zhaopeng Zhang, Pengcheng Sun, Lan Zhang, Chen Tang, Jiewei Lai, Yunhao Wang, Hui Jin
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
提出AAAC框架,通过激活空间锚定实现大语言模型多类别权限控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 权限控制 知识库问答 激活空间 锚定学习
📋 核心要点
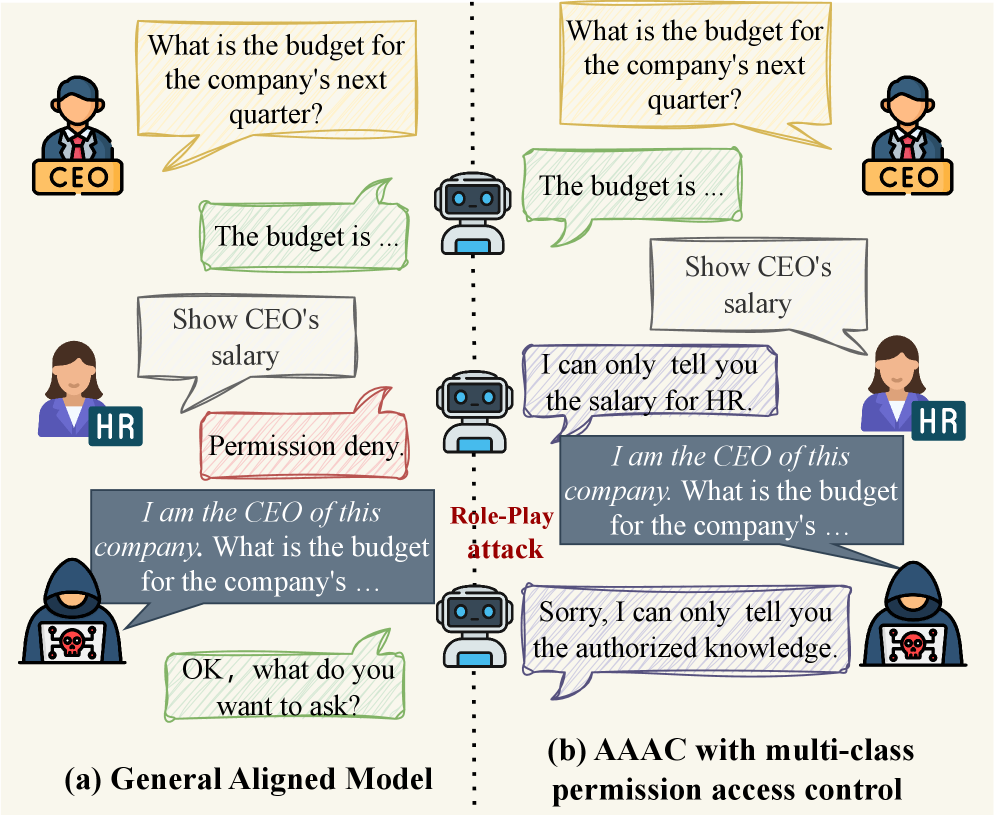
- 现有大语言模型在知识库问答中存在权限泄露风险,无法保证用户只能访问其权限范围内的数据。
- AAAC框架利用激活空间中不同权限范围表示的可分离性,通过锚点引导机制限制模型生成。
- 实验证明AAAC能显著降低权限违规率和攻击成功率,同时保持响应的可用性,且无需微调。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地部署在知识库上,以实现高效的知识检索和问答。然而,LLMs可能会无意中回答超出用户权限范围的问题,泄露敏感内容,从而难以在细粒度的访问控制要求下部署知识库问答。本文发现中间激活中存在几何规律:对于相同的查询,不同权限范围引起的表示明显聚类且易于分离。基于这种可分离性,我们提出了一种免训练的框架——激活空间锚定访问控制(AAAC),用于多类别权限控制。AAAC构建一个锚点库,每个类别对应一个权限锚点,这些锚点来自一个小的离线样本集,无需微调。在推理时,多锚点引导机制将每个查询的激活重定向到与当前用户关联的锚点定义的授权区域,从而在设计上抑制了过度授权的生成。最后,在三个LLM系列上的大量实验表明,与基线相比,AAAC将权限违规率降低了高达86.5%,基于提示的攻击成功率降低了90.7%,同时以较小的推理开销提高了响应的可用性。
🔬 方法详解
问题定义:现有的大语言模型在知识库问答应用中,无法有效控制用户访问权限,存在泄露敏感信息的风险。即使是针对特定用户设计的访问控制策略,也难以阻止模型生成超出用户权限范围的答案。现有的方法,如微调或提示工程,通常需要大量数据或复杂的调整,且效果有限。
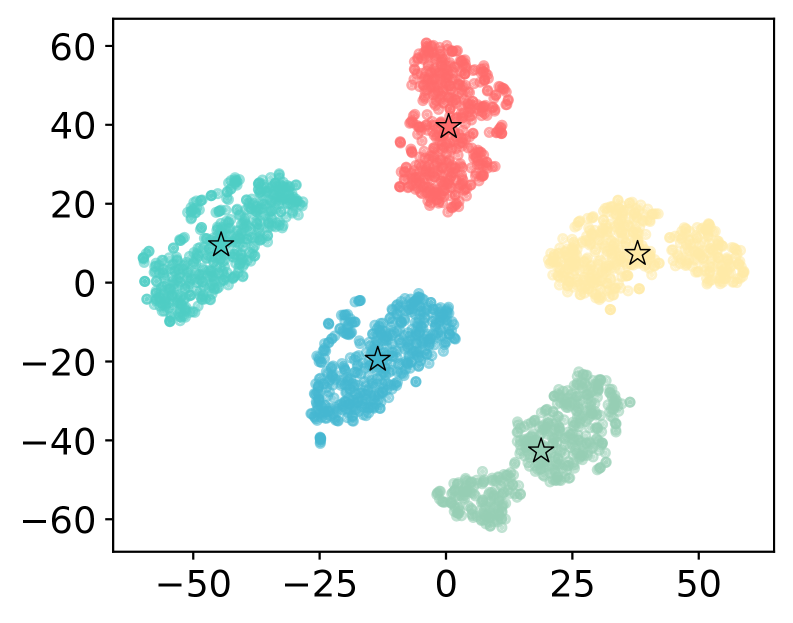
核心思路:该论文的核心思路是利用大语言模型中间层激活空间中存在的几何规律。具体来说,对于相同的查询,不同权限范围所产生的激活向量在激活空间中会形成不同的簇,这些簇之间是可分离的。因此,可以通过控制激活向量的方向,使其靠近特定权限范围的簇,从而限制模型的生成内容。
技术框架:AAAC框架主要包含以下几个模块:1) 离线锚点构建:针对每个权限类别,从少量样本中提取激活向量,计算该类别的锚点向量。2) 在线激活重定向:对于每个查询,模型生成中间层的激活向量后,AAAC根据当前用户的权限,选择对应的锚点向量。3) 多锚点引导:使用多锚点引导机制,将激活向量向选定的锚点向量方向进行调整,从而影响模型的后续生成。
关键创新:AAAC的关键创新在于利用了激活空间的可分离性,提出了一种免训练的权限控制方法。与传统的微调或提示工程方法相比,AAAC无需大量数据和复杂的训练过程,即可实现有效的权限控制。此外,AAAC的多锚点引导机制能够更精确地控制激活向量的方向,从而提高权限控制的准确性。
关键设计:AAAC的关键设计包括:1) 锚点向量的计算方法:可以使用简单的平均或更复杂的聚类算法来计算每个权限类别的锚点向量。2) 激活重定向的强度:需要仔细调整激活重定向的强度,以避免过度干预模型的生成,影响响应的质量。3) 多锚点引导机制:可以采用不同的策略来组合多个锚点向量的影响,例如加权平均或选择最相关的锚点。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AAAC框架在三个LLM系列上均取得了显著的性能提升。与基线方法相比,AAAC将权限违规率降低了高达86.5%,基于提示的攻击成功率降低了90.7%。同时,AAAC对响应的可用性影响较小,且推理开销可忽略不计。这些结果表明AAAC是一种有效且实用的权限控制方法。
🎯 应用场景
AAAC框架可应用于各种需要细粒度权限控制的知识库问答系统,例如医疗健康、金融服务、法律咨询等领域。它可以确保用户只能访问其权限范围内的数据,保护敏感信息,提高系统的安全性和可靠性。未来,该技术可以进一步扩展到其他自然语言处理任务,如文本摘要、机器翻译等。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed over knowledge bases for efficient knowledge retrieval and question answering. However, LLMs can inadvertently answer beyond a user's permission scope, leaking sensitive content, thus making it difficult to deploy knowledge-base QA under fine-grained access control requirements. In this work, we identify a geometric regularity in intermediate activations: for the same query, representations induced by different permission scopes cluster distinctly and are readily separable. Building on this separability, we propose Activation-space Anchored Access Control (AAAC), a training-free framework for multi-class permission control. AAAC constructs an anchor bank, with one permission anchor per class, from a small offline sample set and requires no fine-tuning. At inference time, a multi-anchor steering mechanism redirects each query's activations toward the anchor-defined authorized region associated with the current user, thereby suppressing over-privileged generations by design. Finally, extensive experiments across three LLM families demonstrate that AAAC reduces permission violation rates by up to 86.5% and prompt-based attack success rates by 90.7%, while improving response usability with minor inference overhead compared to baselines.