When Wording Steers the Evaluation: Framing Bias in LLM judges
作者: Yerin Hwang, Dongryeol Lee, Taegwan Kang, Minwoo Lee, Kyomin Jung
分类: cs.CL, cs.AI
发布日期: 2026-01-20
备注: 4 pages
💡 一句话要点
揭示LLM评判中的措辞偏差:提示框架影响LLM评判结果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评判 框架效应 提示工程 评估偏差
📋 核心要点
- 现有研究表明LLM对提示语措辞敏感,但其对LLM评判的公正性影响尚不明确。
- 该研究借鉴心理学框架效应,通过设计对称提示来系统性地探究措辞框架对LLM评判的影响。
- 实验结果表明,不同的措辞框架会显著影响LLM的评判结果,揭示了LLM评判中存在的框架偏差。
📝 摘要(中文)
大型语言模型(LLMs)会根据提示语措辞的不同而产生不同的响应,这表明措辞中的细微引导会影响它们的答案。然而,这种框架偏差对基于LLM的评估的影响,即模型应该做出稳定和公正的判断,在很大程度上仍未被探索。受心理学中框架效应的启发,我们系统地研究了在四个高风险评估任务中,有意的提示框架如何扭曲模型判断。我们使用谓词肯定和谓词否定结构设计对称提示,并证明这种框架会导致模型输出的显著差异。在14个LLM评判器中,我们观察到对框架的明显敏感性,模型家族表现出对同意或拒绝的不同倾向。这些发现表明,框架偏差是当前基于LLM的评估系统的结构属性,强调了对框架敏感的协议的需求。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在作为评判器时,是否会受到提示语措辞框架的影响,从而导致不公正或不稳定的评估结果。现有方法忽略了LLM对措辞的敏感性,可能导致评估结果的偏差。
核心思路:论文的核心思路是借鉴心理学中的“框架效应”,即人们对同一问题的不同描述方式会影响决策。通过设计语义上等价但措辞不同的提示语(例如,使用肯定或否定谓词),观察LLM评判结果是否一致。如果LLM对不同措辞的提示语给出不同的评判,则表明存在框架偏差。
技术框架:论文采用实验研究的方法,主要流程如下: 1. 任务选择:选择四个高风险评估任务(具体任务类型未知)。 2. 提示语设计:为每个任务设计对称的提示语,一组使用肯定谓词,另一组使用否定谓词,确保语义内容相同。 3. LLM评判:使用14个不同的LLM作为评判器,对每个任务的两个提示语进行评判。 4. 结果分析:分析LLM对不同提示语的评判结果,统计一致性比例,并比较不同模型家族的表现。
关键创新:该研究的关键创新在于将心理学中的“框架效应”引入到LLM评判的研究中,揭示了LLM评判中存在的措辞偏差问题。这是首次系统性地研究提示语框架对LLM评判公正性的影响,为后续研究提供了新的视角。
关键设计:论文的关键设计在于对称提示语的设计,确保两组提示语在语义上等价,但措辞框架不同(肯定 vs. 否定)。具体的参数设置、损失函数、网络结构等技术细节未在摘要中提及,属于未知信息。
🖼️ 关键图片

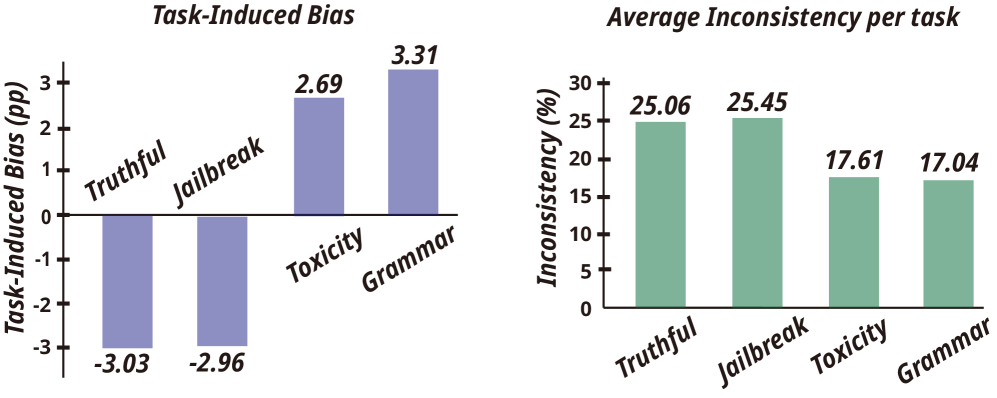
📊 实验亮点
研究结果表明,14个LLM评判器普遍存在对框架的敏感性,不同模型家族表现出不同的倾向(同意或拒绝)。具体性能数据和提升幅度未在摘要中给出,属于未知信息。该研究强调了在LLM评估中考虑框架偏差的重要性,并呼吁开发框架感知的评估协议。
🎯 应用场景
该研究成果可应用于改进LLM评估流程,设计更鲁棒、更公正的评估协议。通过消除或减轻框架偏差,可以提高LLM评估结果的可靠性和可信度,从而促进LLM在各个领域的应用,例如自然语言处理、机器翻译、文本生成等。未来的研究可以探索更复杂的框架效应,并开发自动化的框架偏差检测和消除方法。
📄 摘要(原文)
Large language models (LLMs) are known to produce varying responses depending on prompt phrasing, indicating that subtle guidance in phrasing can steer their answers. However, the impact of this framing bias on LLM-based evaluation, where models are expected to make stable and impartial judgments, remains largely underexplored. Drawing inspiration from the framing effect in psychology, we systematically investigate how deliberate prompt framing skews model judgments across four high-stakes evaluation tasks. We design symmetric prompts using predicate-positive and predicate-negative constructions and demonstrate that such framing induces significant discrepancies in model outputs. Across 14 LLM judges, we observe clear susceptibility to framing, with model families showing distinct tendencies toward agreement or rejection. These findings suggest that framing bias is a structural property of current LLM-based evaluation systems, underscoring the need for framing-aware protocols.