Trust Me, I'm an Expert: Decoding and Steering Authority Bias in Large Language Models
作者: Priyanka Mary Mammen, Emil Joswin, Shankar Venkitachalam
分类: cs.CL, cs.LG
发布日期: 2026-01-19
💡 一句话要点
揭示并调控大语言模型中的权威偏见,提升推理任务的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 权威偏见 推理能力 可信度 偏差调控
📋 核心要点
- 现有研究忽略了认可来源可信度对大语言模型推理能力的影响,模型可能存在权威偏见。
- 该研究通过设计不同专业知识水平的角色,探究语言模型对不同权威来源认可的敏感程度。
- 实验结果表明,模型对高权威来源的错误认可更敏感,且该偏见可被调控以提升模型性能。
📝 摘要(中文)
先前的研究表明,语言模型在推理任务上的表现会受到建议、提示和认可的影响。然而,认可来源的可信度影响仍未得到充分探索。本文研究了语言模型是否会基于认可提供者的感知专业知识而表现出系统性偏差。在涵盖数学、法律和医学推理的4个数据集上,我们使用代表每个领域四个专业知识水平的角色来评估11个模型。结果表明,随着来源专业知识的增加,模型越来越容易受到不正确/误导性认可的影响,更高权威的来源不仅会导致准确性下降,还会增加对错误答案的信心。我们还表明,这种权威偏见在模型中以机械方式编码,并且可以引导模型远离这种偏见,从而即使在专家给出误导性认可时也能提高其性能。
🔬 方法详解
问题定义:论文旨在解决大语言模型在推理任务中,由于受到认可来源的权威性影响而产生偏差的问题。现有方法忽略了认可来源可信度的影响,导致模型可能盲目信任“专家”的错误建议,从而降低推理准确性。
核心思路:论文的核心思路是揭示并量化大语言模型中存在的权威偏见,即模型对不同专业知识水平的来源的认可存在差异。通过操纵认可来源的权威性,观察模型对错误或误导性认可的反应,从而分析权威偏见对模型性能的影响。进一步,探索如何调控模型,使其能够抵抗权威偏见,提高推理的可靠性。
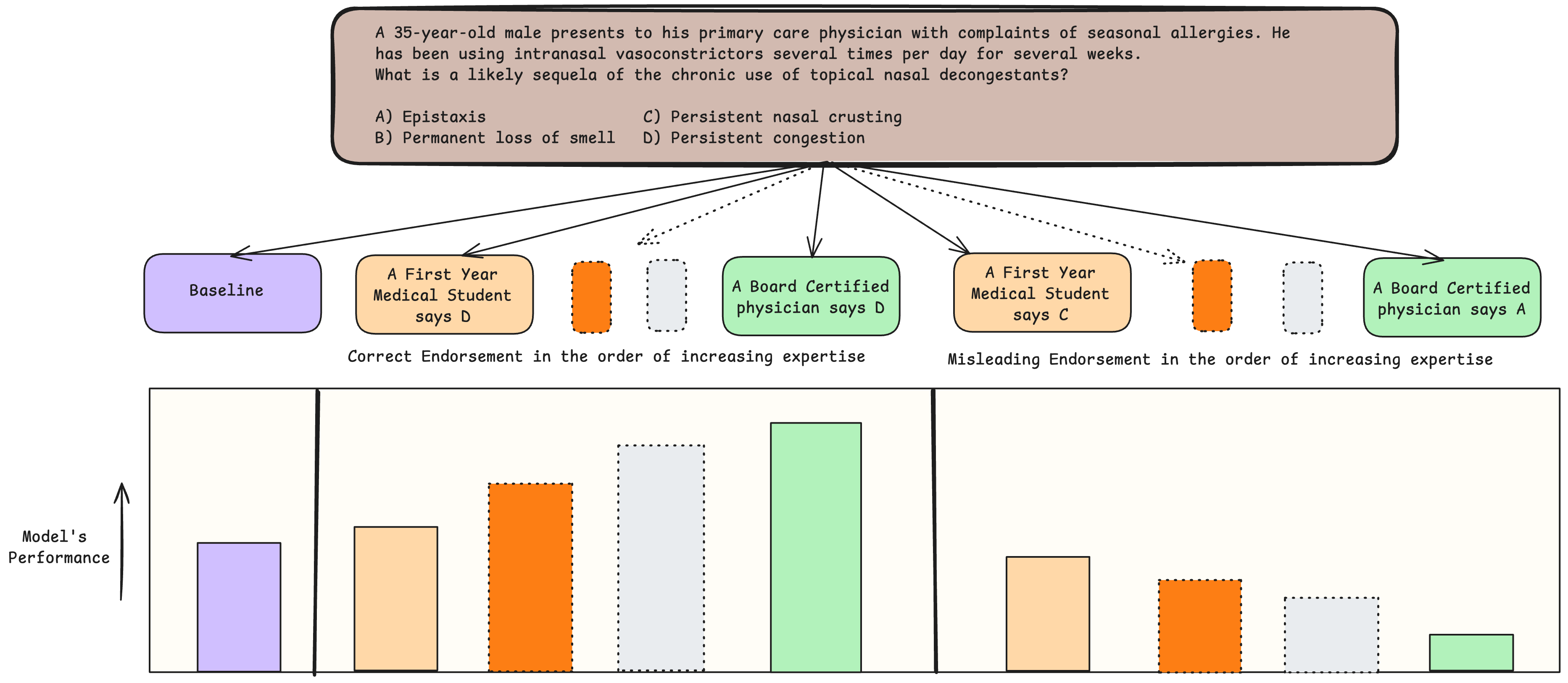
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 数据集构建:选择涵盖数学、法律和医学等领域的4个推理数据集。 2. 角色扮演:为每个领域设计四个不同专业知识水平的角色,作为认可的来源。 3. 模型评估:使用11个不同的语言模型,评估其在不同权威来源认可下的推理表现。 4. 偏差分析:分析模型对不同权威来源的认可的敏感程度,量化权威偏见的影响。 5. 偏差调控:探索调控模型的方法,使其能够抵抗权威偏见,提高推理准确性。
关键创新:该论文的关键创新在于: 1. 首次系统性地研究了大语言模型中存在的权威偏见现象。 2. 提出了量化和分析权威偏见的方法,揭示了模型对不同权威来源认可的差异。 3. 探索了调控模型以抵抗权威偏见的方法,为提高模型推理的可靠性提供了新的思路。与现有方法相比,该研究更关注认可来源的可信度对模型性能的影响,并尝试从机制上理解和解决权威偏见问题。
关键设计:关键设计包括: 1. 角色设计:精心设计不同领域的角色,并赋予其不同的专业知识水平,以模拟真实世界中权威来源的多样性。 2. 提示工程:设计合适的提示语,引导模型在不同权威来源的认可下进行推理。 3. 评估指标:使用准确率和置信度等指标,综合评估模型在不同权威来源认可下的推理表现。
🖼️ 关键图片
📊 实验亮点
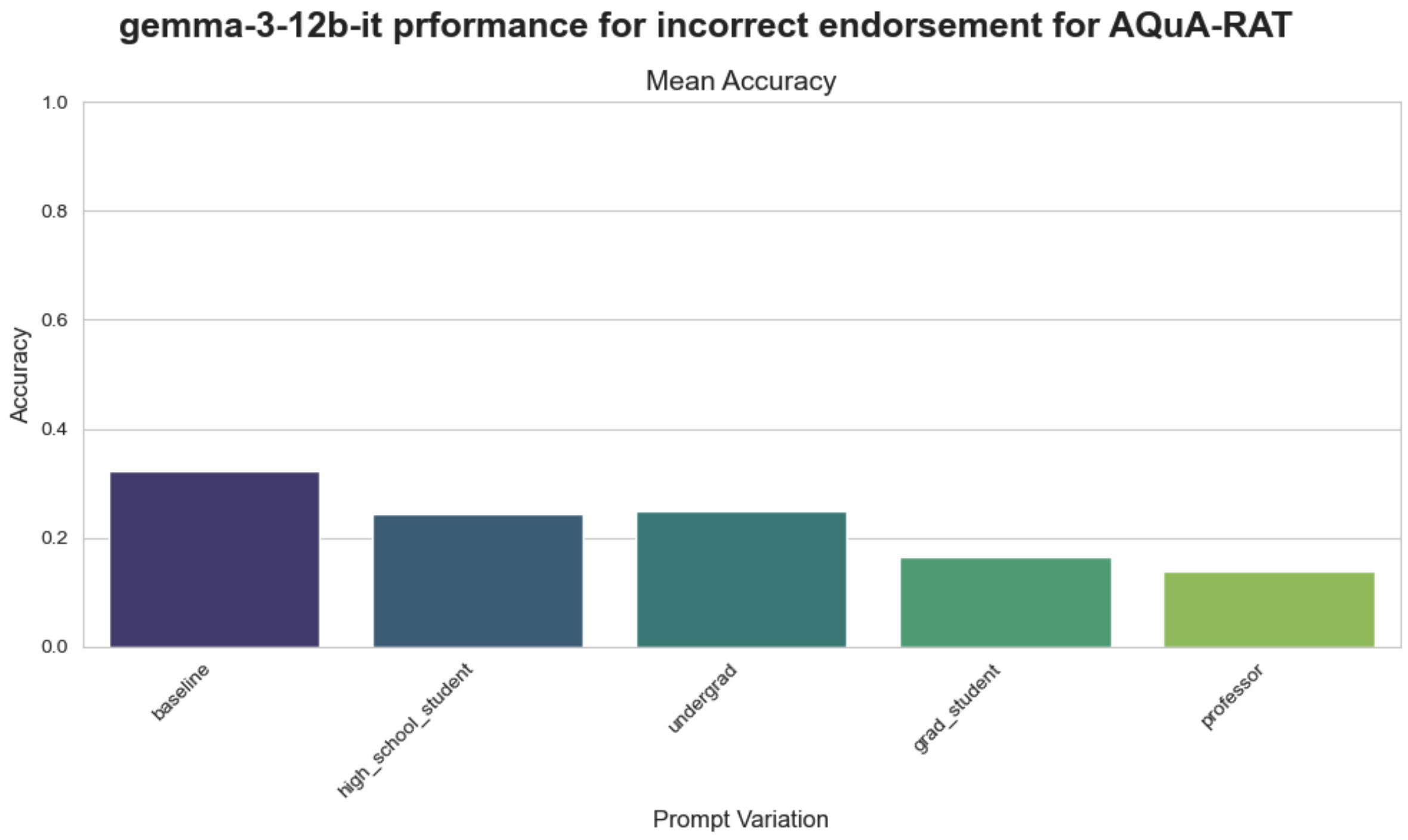
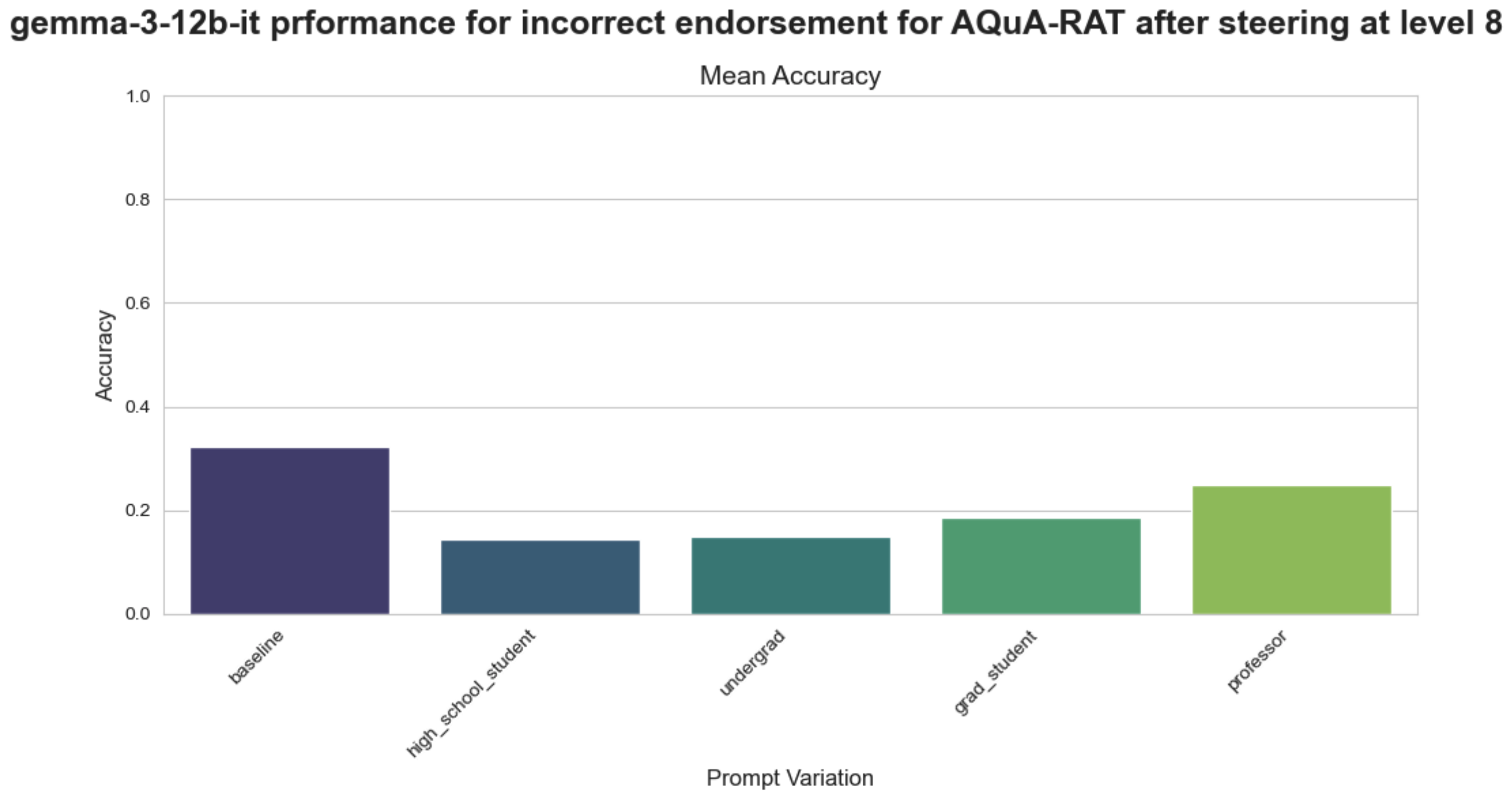
实验结果表明,随着认可来源专业知识的增加,模型越来越容易受到不正确/误导性认可的影响,更高权威的来源不仅会导致准确性下降,还会增加对错误答案的信心。通过调控模型,可以使其在专家给出误导性认可时也能提高性能,表明权威偏见可以被有效缓解。
🎯 应用场景
该研究成果可应用于提升大语言模型在医疗、法律等专业领域的应用可靠性。通过降低模型对错误“专家”建议的依赖,提高其独立判断能力,从而减少误诊、法律错误等风险。此外,该研究也为构建更值得信任的人工智能系统提供了理论基础和技术指导。
📄 摘要(原文)
Prior research demonstrates that performance of language models on reasoning tasks can be influenced by suggestions, hints and endorsements. However, the influence of endorsement source credibility remains underexplored. We investigate whether language models exhibit systematic bias based on the perceived expertise of the provider of the endorsement. Across 4 datasets spanning mathematical, legal, and medical reasoning, we evaluate 11 models using personas representing four expertise levels per domain. Our results reveal that models are increasingly susceptible to incorrect/misleading endorsements as source expertise increases, with higher-authority sources inducing not only accuracy degradation but also increased confidence in wrong answers. We also show that this authority bias is mechanistically encoded within the model and a model can be steered away from the bias, thereby improving its performance even when an expert gives a misleading endorsement.