Beyond Memorization: Testing LLM Reasoning on Unseen Theory of Computation Tasks
作者: Shlok Shelat, Jay Raval, Souvik Roy, Manas Gaur
分类: cs.CL, cs.AI, cs.FL
发布日期: 2026-01-19
备注: 30 pages, 11 figures, 6 tables, Work in Progress
💡 一句话要点
提出DFA构造基准测试,揭示LLM在形式语言推理中泛化能力不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式语言 确定性有限自动机 推理能力 基准测试
📋 核心要点
- 现有LLM在形式语言任务中表现出色,但缺乏对符号推理能力进行有效评估的基准。
- 论文提出新的DFA构造基准,包含已见和未见问题,旨在测试LLM的泛化推理能力。
- 实验表明,LLM在未见问题上性能显著下降,揭示了其在形式语言推理方面的局限性。
📝 摘要(中文)
大型语言模型(LLMs)在形式语言任务上表现出强大的性能,但这是否反映了真正的符号推理,还是仅仅是对熟悉结构的模式匹配,仍然不清楚。我们引入了一个确定性有限自动机(DFA)构造的基准,该基准来自正则语言,包括事实知识问题、来自公共来源的已见构造问题,以及两种类型的未见问题:具有多个交互约束的手工实例,以及通过Arden定理系统生成的问题。模型在事实问题上实现了完美的准确率,在已见任务上实现了84-90%的准确率。然而,在未见问题上,准确率急剧下降(下降30-64%),失败源于对语言约束的系统性误解、对Kleene星语义的错误处理以及未能保持全局一致性。我们评估了一个三阶段提示协议,该协议能够纠正浅层错误,但不能可靠地解决全局不一致或结构上有缺陷的自动机。我们对多种提示策略(直接提示、思维链、思维树)的分析表明,无论采用何种提示方法,错误仍然存在,这暴露了LLM生成语法上合理的DFA的能力与其进行语义上正确的形式推理的能力之间存在根本差距。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在形式语言推理方面的能力,特别是它们从正则语言构造确定性有限自动机(DFA)的能力。现有方法主要关注LLM在已见过的任务上的表现,无法有效评估其真正的推理和泛化能力。因此,论文关注的痛点是缺乏一个能够区分LLM的记忆能力和推理能力的基准测试。
核心思路:论文的核心思路是设计一个包含未见过的DFA构造问题的基准测试,这些问题需要LLM进行真正的符号推理,而不仅仅是模式匹配。通过分析LLM在这些未见问题上的表现,可以更准确地评估其形式语言推理能力。论文认为,如果LLM能够真正理解形式语言的语义,那么它应该能够在未见问题上表现良好。
技术框架:论文的技术框架主要包括以下几个阶段: 1. 基准测试设计:设计包含事实知识问题、已见构造问题和未见构造问题的DFA构造基准。 2. 问题生成:使用手工设计和Arden定理系统生成两种类型的未见问题,以测试LLM在不同约束条件下的推理能力。 3. 模型评估:使用不同的提示策略(直接提示、思维链、思维树)评估LLM在基准测试上的表现。 4. 错误分析:分析LLM在未见问题上的错误类型,例如对语言约束的误解、对Kleene星语义的错误处理等。 5. 提示优化:设计三阶段提示协议,尝试纠正LLM的错误。
关键创新:论文最重要的技术创新点在于提出了一个用于评估LLM形式语言推理能力的DFA构造基准,该基准包含未见问题,能够有效区分LLM的记忆能力和推理能力。与现有方法相比,该基准更具挑战性,能够更准确地评估LLM的泛化能力。
关键设计:论文的关键设计包括: 1. 未见问题设计:手工设计具有多个交互约束的DFA构造问题,以及使用Arden定理系统生成DFA构造问题,以增加问题的复杂性和多样性。 2. 提示策略:使用不同的提示策略(直接提示、思维链、思维树)来评估LLM的表现,并分析不同提示策略对结果的影响。 3. 三阶段提示协议:设计一个三阶段提示协议,包括错误检测、错误纠正和验证,以尝试纠正LLM的错误。
🖼️ 关键图片
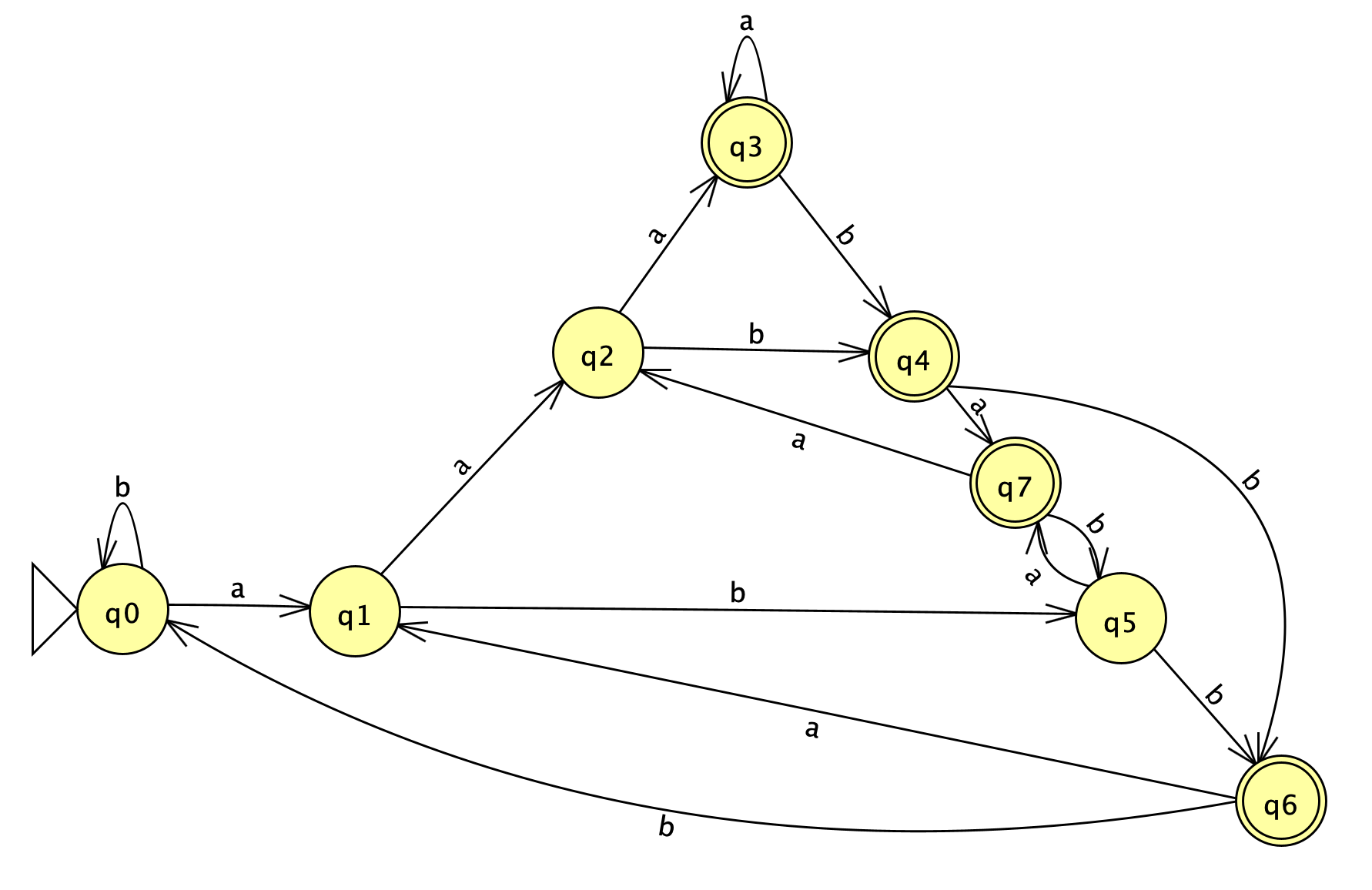
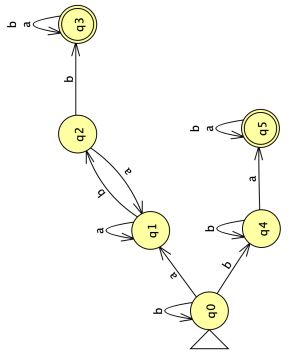

📊 实验亮点
实验结果表明,LLM在事实问题上实现了完美的准确率,在已见任务上实现了84-90%的准确率。然而,在未见问题上,准确率急剧下降(下降30-64%)。即使使用不同的提示策略(直接提示、思维链、思维树)和三阶段提示协议,LLM在未见问题上的性能仍然显著低于已见问题,这表明LLM在形式语言推理方面存在根本性的局限性。
🎯 应用场景
该研究成果可应用于评估和改进LLM在形式语言处理、程序合成、自然语言理解等领域的性能。通过更准确地评估LLM的推理能力,可以推动LLM在需要精确逻辑和符号推理的任务中的应用,例如软件验证、智能合约开发等。未来的研究可以基于此基准,探索更有效的提示策略和模型架构,以提高LLM的形式语言推理能力。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong performance on formal language tasks, yet whether this reflects genuine symbolic reasoning or pattern matching on familiar constructions remains unclear. We introduce a benchmark for deterministic finite automata (DFA) construction from regular languages, comprising factual knowledge questions, seen construction problems from public sources, and two types of unseen problems: hand-crafted instances with multiple interacting constraints and systematically generated problems via Arden's theorem. Models achieve perfect accuracy on factual questions and 84-90% on seen tasks. However, accuracy drops sharply on unseen problems (by 30-64%), with failures stemming from systematic misinterpretation of language constraints, incorrect handling of Kleene-star semantics, and a failure to preserve global consistency. We evaluate a three-stage hint protocol that enables correction of shallow errors but does not reliably resolve globally inconsistent or structurally flawed automata. Our analysis across multiple prompting strategies (direct, Chain-of-Thought, Tree-of-Thought) reveals that errors persist regardless of prompting approach, exposing a fundamental gap between LLMs' ability to generate syntactically plausible DFAs and their capacity for semantically correct formal reasoning.