Structured Insight from Unstructured Data: Large Language Models for SDOH-Driven Diabetes Risk Prediction
作者: Sasha Ronaghi, Prerit Choudhary, David H Rehkopf, Bryant Lin
分类: cs.CL
发布日期: 2026-01-19
备注: 7 pages, 5 figures
期刊: Annu Int Conf IEEE Eng Med Biol Soc. 2025 Jul;2025:1-7
DOI: 10.1109/EMBC58623.2025.11254798
💡 一句话要点
利用大语言模型从非结构化SDOH数据中提取信息,用于糖尿病风险预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 健康社会决定因素 大型语言模型 糖尿病风险预测 非结构化数据 检索增强生成
📋 核心要点
- 电子健康记录中缺乏健康社会决定因素(SDOH)信息,限制了糖尿病风险预测模型的准确性。
- 利用大型语言模型(LLM)从患者访谈中提取结构化SDOH信息,并评估其预测糖尿病控制水平的能力。
- 实验表明,LLM能够从访谈文本中以60%的准确率预测糖尿病控制水平,具有实际应用潜力。
📝 摘要(中文)
本研究探索了使用大型语言模型(LLM)从非结构化的患者生活故事中提取结构化的健康社会决定因素(SDOH)信息,并评估提取的特征和叙述本身在评估糖尿病控制方面的预测价值。研究收集了65名65岁及以上的2型糖尿病患者的非结构化访谈,重点关注他们的生活经历、社会背景和糖尿病管理。使用带有检索增强生成(RAG)的LLM分析这些叙述,以生成简洁、可操作的定性摘要用于临床解释,以及结构化的定量SDOH评级用于风险预测建模。结构化的SDOH评级独立使用,并与传统的实验室生物标志物结合使用,作为线性模型和基于树的机器学习模型(Ridge、Lasso、Random Forest和XGBoost)的输入,以展示非结构化叙述数据如何在传统的风险预测工作流程中应用。最后,评估了几个LLM直接从访谈文本(A1C值已编辑)预测患者的糖尿病控制水平(低、中、高)的能力。LLM在从访谈文本预测糖尿病控制水平方面达到了60%的准确率。这项工作展示了LLM如何将非结构化的SDOH相关数据转化为结构化的见解,从而提供了一种可扩展的方法来增强临床风险模型和决策。
🔬 方法详解
问题定义:论文旨在解决电子健康记录中SDOH数据缺失的问题,现有方法依赖结构化筛查工具,无法捕捉患者经历的复杂性和诊所人群的独特需求,导致糖尿病风险预测模型不够准确。
核心思路:利用大型语言模型(LLM)处理非结构化的患者访谈数据,从中提取结构化的SDOH信息,并将其用于糖尿病风险预测。核心在于将LLM作为桥梁,连接非结构化数据和结构化风险预测模型。
技术框架:整体流程包括:1) 收集患者访谈数据;2) 使用带有检索增强生成(RAG)的LLM分析访谈数据,生成定性摘要和结构化SDOH评级;3) 将SDOH评级与生物标志物结合,输入线性模型和树模型进行风险预测;4) 直接使用LLM从访谈文本预测糖尿病控制水平。
关键创新:创新点在于将LLM应用于SDOH数据的提取和结构化,并将其整合到传统的风险预测工作流程中。与传统方法相比,该方法能够处理非结构化数据,捕捉更丰富的患者信息。
关键设计:研究使用了多种LLM模型,并评估了它们在预测糖尿病控制水平方面的性能。采用了检索增强生成(RAG)技术来提高LLM生成摘要和评级的质量。使用了Ridge、Lasso、Random Forest和XGBoost等机器学习模型进行风险预测,并比较了不同模型的性能。
🖼️ 关键图片
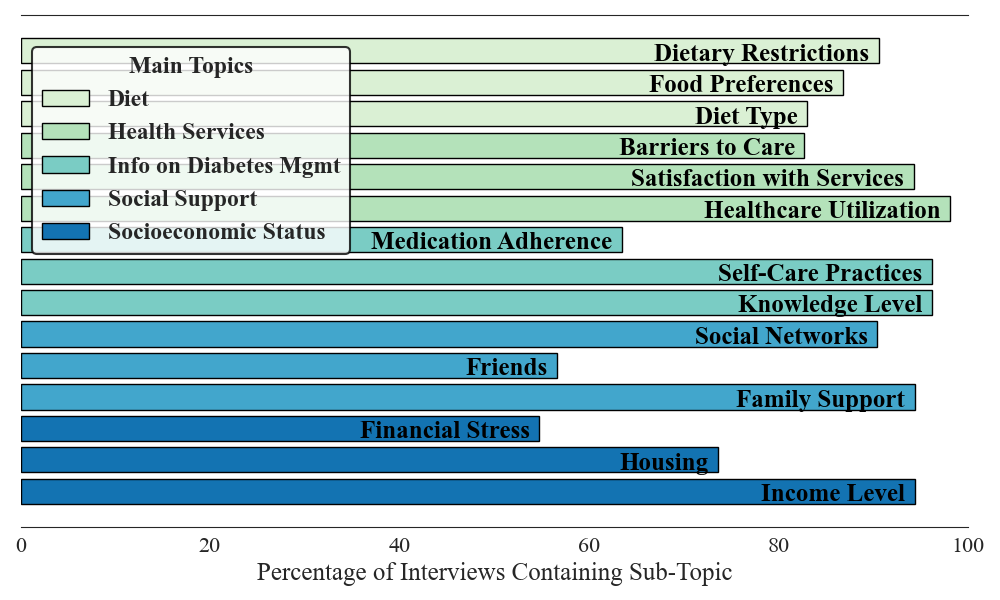
📊 实验亮点
研究表明,LLM能够以60%的准确率从患者访谈文本中预测糖尿病控制水平。此外,将LLM提取的SDOH信息与传统生物标志物结合使用,可以提高糖尿病风险预测模型的准确性。这些结果表明,LLM在SDOH数据分析和风险预测方面具有巨大的潜力。
🎯 应用场景
该研究成果可应用于临床决策支持系统,帮助医生更好地了解患者的社会环境因素,从而制定更个性化的治疗方案。通过自动提取和结构化SDOH信息,可以减轻医生的工作负担,提高工作效率。此外,该方法还可以用于公共卫生监测和干预,识别高风险人群,并制定有针对性的干预措施。
📄 摘要(原文)
Social determinants of health (SDOH) play a critical role in Type 2 Diabetes (T2D) management but are often absent from electronic health records and risk prediction models. Most individual-level SDOH data is collected through structured screening tools, which lack the flexibility to capture the complexity of patient experiences and unique needs of a clinic's population. This study explores the use of large language models (LLMs) to extract structured SDOH information from unstructured patient life stories and evaluate the predictive value of both the extracted features and the narratives themselves for assessing diabetes control. We collected unstructured interviews from 65 T2D patients aged 65 and older, focused on their lived experiences, social context, and diabetes management. These narratives were analyzed using LLMs with retrieval-augmented generation to produce concise, actionable qualitative summaries for clinical interpretation and structured quantitative SDOH ratings for risk prediction modeling. The structured SDOH ratings were used independently and in combination with traditional laboratory biomarkers as inputs to linear and tree-based machine learning models (Ridge, Lasso, Random Forest, and XGBoost) to demonstrate how unstructured narrative data can be applied in conventional risk prediction workflows. Finally, we evaluated several LLMs on their ability to predict a patient's level of diabetes control (low, medium, high) directly from interview text with A1C values redacted. LLMs achieved 60% accuracy in predicting diabetes control levels from interview text. This work demonstrates how LLMs can translate unstructured SDOH-related data into structured insights, offering a scalable approach to augment clinical risk models and decision-making.