Confidence over Time: Confidence Calibration with Temporal Logic for Large Language Model Reasoning
作者: Zhenjiang Mao, Anirudhh Venkat, Artem Bisliouk, Akshat Kothiyal, Sindhura Kumbakonam Subramanian, Saithej Singhu, Ivan Ruchkin
分类: cs.CL, cs.LG
发布日期: 2026-01-19
💡 一句话要点
利用时序逻辑校准LLM推理置信度,提升复杂任务表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 置信度校准 信号时序逻辑 多步推理 参数超网络
📋 核心要点
- 现有LLM置信度估计方法将推理过程简化为单一分数,忽略了推理过程中置信度的动态变化,导致校准不佳。
- 论文提出使用信号时序逻辑(STL)来建模推理过程中置信度的变化,并学习区分正确和错误推理的STL模式。
- 实验表明,该方法在多个推理任务上实现了更好的置信度校准,优于现有基线方法。
📝 摘要(中文)
大型语言模型(LLM)越来越多地依赖长程、多步骤推理来解决复杂的任务,例如数学问题求解和科学问题回答。尽管性能强大,但现有的置信度估计方法通常将整个推理过程简化为单个标量分数,忽略了置信度在生成过程中的演变。因此,这些方法通常对诸如响应长度或冗长等表面因素敏感,并且难以区分正确的推理和自信地陈述的错误。我们提出使用信号时序逻辑(STL)来表征逐步置信度信号。使用判别式STL挖掘程序,我们发现了区分正确和不正确响应的置信度信号的时序公式。我们的分析发现,STL模式可以跨任务泛化,数值参数对单个问题敏感。基于这些见解,我们开发了一种置信度估计方法,该方法使用参数超网络来告知STL块。在多个推理任务上的实验表明,我们的置信度分数比基线更校准。
🔬 方法详解
问题定义:现有的大型语言模型在解决复杂推理任务时,虽然表现出了强大的能力,但是其置信度估计方法存在缺陷。这些方法通常将整个推理过程的置信度压缩为一个单一的标量值,忽略了推理过程中置信度的动态变化。这导致模型难以区分正确的推理和自信的错误,并且容易受到诸如回复长度等表面因素的影响。因此,如何更准确地评估LLM在多步推理过程中的置信度是一个重要的挑战。
核心思路:论文的核心思路是利用信号时序逻辑(STL)来建模LLM在推理过程中置信度的变化。STL是一种用于描述信号随时间变化的逻辑语言,可以用来表达复杂的时序关系。通过学习区分正确和错误推理过程的STL模式,可以更准确地评估LLM的置信度。这种方法能够捕捉到推理过程中置信度的细微变化,从而提高置信度估计的准确性。
技术框架:该方法主要包含以下几个阶段:1) 使用LLM生成推理过程,并记录每一步的置信度得分。2) 使用判别式STL挖掘程序,从正确和错误的推理过程中学习STL公式。这些公式能够区分不同推理过程的置信度信号。3) 使用参数超网络来预测STL公式中的参数,从而使模型能够适应不同的任务和问题。4) 使用学习到的STL公式来评估LLM的置信度。
关键创新:该论文的关键创新在于使用信号时序逻辑(STL)来建模LLM推理过程中的置信度变化。与传统的将整个推理过程压缩为单一标量值的方法不同,该方法能够捕捉到推理过程中置信度的动态变化,从而更准确地评估LLM的置信度。此外,使用参数超网络来预测STL公式中的参数,使得模型能够适应不同的任务和问题。
关键设计:在STL挖掘过程中,使用了判别式方法来学习区分正确和错误推理过程的STL公式。参数超网络的设计允许模型根据不同的输入问题动态调整STL公式中的参数。损失函数的设计目标是最大化正确推理过程的置信度,同时最小化错误推理过程的置信度。具体的网络结构和参数设置在论文中有详细描述,但未在此处明确给出。
🖼️ 关键图片


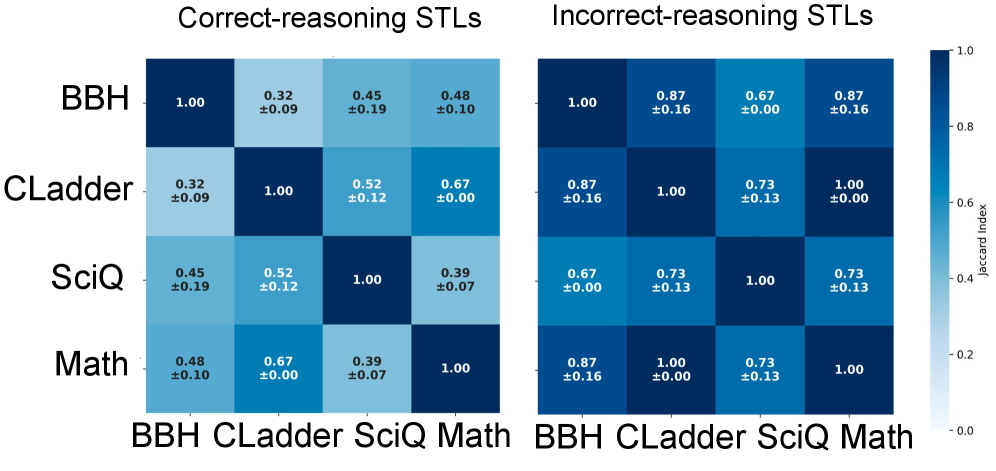
📊 实验亮点
实验结果表明,该方法在多个推理任务上实现了更好的置信度校准,优于现有的基线方法。具体而言,该方法能够更准确地区分正确和错误的推理过程,并且对诸如回复长度等表面因素的敏感性较低。虽然论文中没有给出具体的性能数据和提升幅度,但强调了其置信度校准优于基线。
🎯 应用场景
该研究成果可应用于各种需要LLM进行复杂推理的场景,例如数学问题求解、科学问题回答、代码生成等。通过提高LLM置信度估计的准确性,可以帮助用户更好地信任和使用LLM,并减少因LLM错误推理而导致的风险。此外,该方法还可以用于LLM的调试和优化,帮助开发者更好地理解LLM的推理过程。
📄 摘要(原文)
Large Language Models (LLMs) increasingly rely on long-form, multi-step reasoning to solve complex tasks such as mathematical problem solving and scientific question answering. Despite strong performance, existing confidence estimation methods typically reduce an entire reasoning process to a single scalar score, ignoring how confidence evolves throughout the generation. As a result, these methods are often sensitive to superficial factors such as response length or verbosity, and struggle to distinguish correct reasoning from confidently stated errors. We propose to characterize the stepwise confidence signal using Signal Temporal Logic (STL). Using a discriminative STL mining procedure, we discover temporal formulas that distinguish confidence signals of correct and incorrect responses. Our analysis found that the STL patterns generalize across tasks, and numeric parameters exhibit sensitivity to individual questions. Based on these insights, we develop a confidence estimation approach that informs STL blocks with parameter hypernetworks. Experiments on multiple reasoning tasks show our confidence scores are more calibrated than the baselines.