Recurrent Confidence Chain: Temporal-Aware Uncertainty Quantification in Large Language Models
作者: Zhenjiang Mao, Anirudhh Venkat
分类: cs.CL, cs.LG
发布日期: 2026-01-19
💡 一句话要点
提出循环置信链,解决大语言模型中时序感知的不确定性量化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性量化 置信度评估 时间建模 思维链
📋 核心要点
- 现有方法在分析LLM推理过程中的不确定性时,忽略了置信度随时间传播的特性,导致整体置信度评估不准确。
- 提出循环置信链方法,通过步间注意力和隐藏置信度机制,建模推理步骤之间的语义相关性和历史置信度信息。
- 在GAOKAO数学和CLadder因果推理数据集上的实验表明,该方法在预测质量和校准方面均优于现有技术。
📝 摘要(中文)
随着思维链等推理模块应用于大型语言模型,它们在常识问答和数学问题解决等任务上表现出色。目前的主要挑战是评估答案的不确定性,这有助于防止误导性或严重的幻觉。现有方法通过过滤不相关的token并检查附近token或句子之间的潜在联系来分析长推理序列,但通常忽略了置信度的时间传播。这种疏忽可能导致整体置信度膨胀,即使早期步骤表现出非常低的置信度。为了解决这个问题,我们提出了一种新方法,该方法结合了步间注意力来分析步骤之间的语义相关性。对于处理长程响应,我们引入了一种隐藏置信度机制来保留历史置信度信息,然后将其与逐步置信度相结合,以产生更准确的整体估计。我们在GAOKAO数学基准和CLadder因果推理数据集上使用主流开源大型语言模型评估了我们的方法。结果表明,我们的方法优于最先进的方法,在预测质量和校准之间取得了更好的平衡,在负对数似然和预期校准误差方面表现出色。
🔬 方法详解
问题定义:现有的大语言模型在进行复杂推理时,例如使用思维链方法,虽然在很多任务上取得了很好的效果,但是对于答案的不确定性评估仍然是一个挑战。现有的方法主要关注于过滤不相关的token或者分析相邻步骤之间的联系,忽略了置信度在整个推理过程中的时间依赖性,导致最终的置信度评估偏高,无法准确反映模型的真实不确定性。
核心思路:本文的核心思路是引入时间感知的置信度评估机制。通过建模推理步骤之间的语义相关性以及历史置信度信息,来更准确地评估整个推理过程的置信度。这样可以避免早期步骤的低置信度被后续步骤的高置信度所掩盖,从而提供更可靠的不确定性估计。
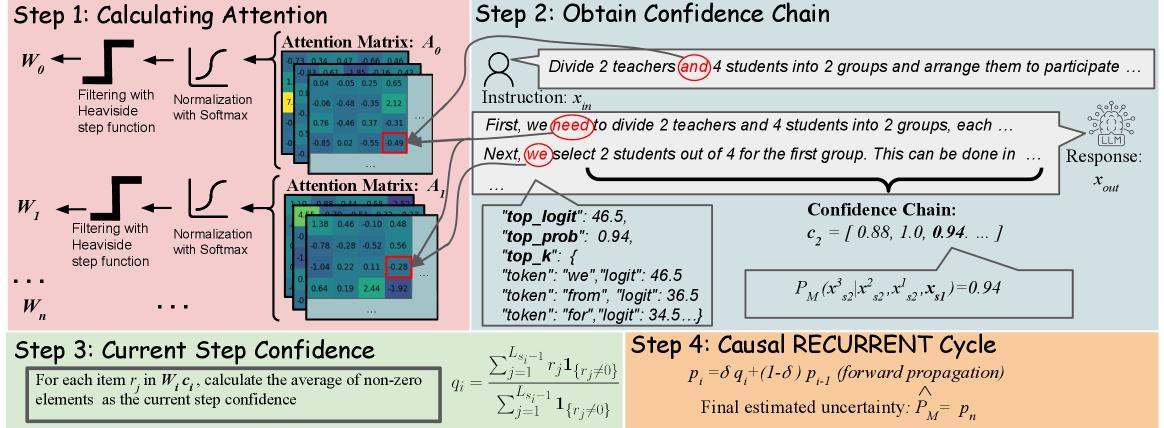
技术框架:整体框架包含两个主要模块:步间注意力模块和隐藏置信度模块。步间注意力模块用于分析推理步骤之间的语义相关性,捕捉步骤之间的依赖关系。隐藏置信度模块用于维护一个隐藏状态,存储历史置信度信息,并将其与当前步骤的置信度相结合,生成最终的置信度估计。整个流程可以概括为:输入推理序列 -> 步间注意力模块 -> 隐藏置信度模块 -> 输出置信度估计。
关键创新:最重要的创新点在于对置信度的时间建模。传统的置信度评估方法往往将每个步骤的置信度视为独立的,而忽略了它们之间的依赖关系。本文通过步间注意力和隐藏置信度机制,显式地建模了这种时间依赖性,从而提高了置信度评估的准确性。与现有方法的本质区别在于,本文的方法考虑了置信度在时间上的传播和积累,而不仅仅是关注单个步骤的置信度。
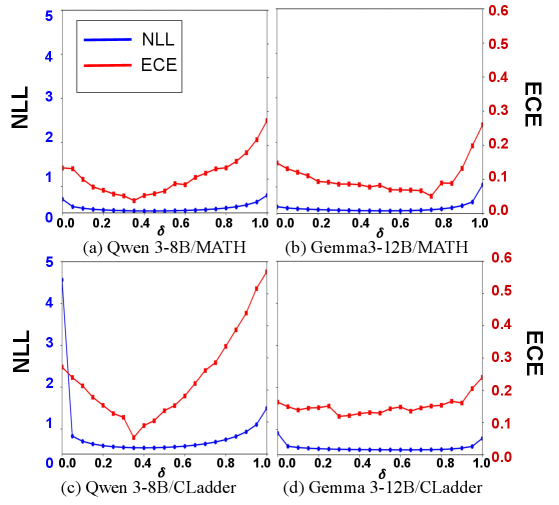
关键设计:步间注意力模块使用Transformer的注意力机制来计算不同步骤之间的语义相关性。隐藏置信度模块使用一个循环神经网络(RNN)来维护隐藏状态,并使用一个sigmoid函数将隐藏状态映射到置信度值。损失函数采用负对数似然(NLL)和预期校准误差(ECE)的加权和,以同时优化预测质量和校准性能。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
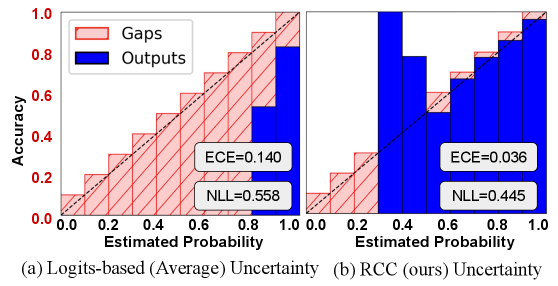
在GAOKAO数学和CLadder因果推理数据集上的实验结果表明,该方法在负对数似然(NLL)和预期校准误差(ECE)两个指标上均优于现有技术,实现了预测质量和校准之间的更好平衡。具体提升幅度未知,但实验结果表明该方法能够更准确地评估大语言模型的不确定性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性和可信度的大语言模型应用场景,例如医疗诊断、金融风控、法律咨询等。通过提供更准确的不确定性估计,可以帮助用户更好地理解模型的预测结果,并做出更明智的决策。未来,该方法可以进一步扩展到其他类型的推理任务和模型架构,提高大语言模型在实际应用中的安全性和可靠性。
📄 摘要(原文)
As reasoning modules, such as the chain-of-thought mechanism, are applied to large language models, they achieve strong performance on various tasks such as answering common-sense questions and solving math problems. The main challenge now is to assess the uncertainty of answers, which can help prevent misleading or serious hallucinations for users. Although current methods analyze long reasoning sequences by filtering unrelated tokens and examining potential connections between nearby tokens or sentences, the temporal spread of confidence is often overlooked. This oversight can lead to inflated overall confidence, even when earlier steps exhibit very low confidence. To address this issue, we propose a novel method that incorporates inter-step attention to analyze semantic correlations across steps. For handling long-horizon responses, we introduce a hidden confidence mechanism to retain historical confidence information, which is then combined with stepwise confidence to produce a more accurate overall estimate. We evaluate our method on the GAOKAO math benchmark and the CLadder causal reasoning dataset using mainstream open-source large language models. Our approach is shown to outperform state-of-the-art methods by achieving a superior balance between predictive quality and calibration, demonstrated by strong performance on both Negative Log-Likelihood and Expected Calibration Error.