LLM-as-RNN: A Recurrent Language Model for Memory Updates and Sequence Prediction
作者: Yuxing Lu, J. Ben Tamo, Weichen Zhao, Nan Sun, Yishan Zhong, Wenqi Shi, Jinzhuo Wang, May D. Wang
分类: cs.CL, cs.AI, cs.MA
发布日期: 2026-01-19
备注: 17 pages, 5 figures, 6 tables
💡 一句话要点
LLM-as-RNN:利用语言记忆更新的循环语言模型,提升序列预测能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 循环神经网络 序列预测 在线学习 自然语言记忆
📋 核心要点
- 现有LLM序列预测依赖不可变上下文,无法在生成错误后动态调整,影响后续预测。
- LLM-as-RNN将LLM隐藏状态表示为自然语言记忆,通过反馈驱动的文本重写进行更新,实现在线学习。
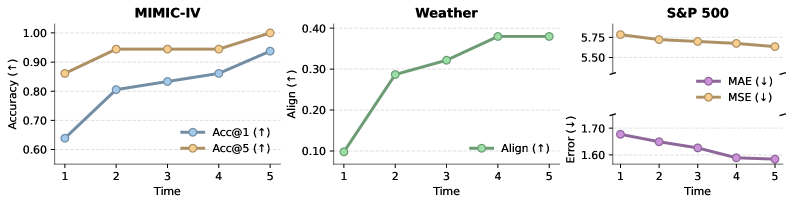
- 实验表明,LLM-as-RNN在医疗、气象、金融等序列预测任务中,显著优于现有基线方法,提升预测精度。
📝 摘要(中文)
大型语言模型(LLM)是强大的序列预测器,但标准推理依赖于不可变的历史上下文。当模型在生成步骤t犯错后,缺乏可更新的记忆机制来改进t+1步骤的预测。我们提出了LLM-as-RNN,一个仅用于推理的框架,通过将LLM的隐藏状态表示为自然语言记忆,将其转变为循环预测器。该状态以结构化的系统提示摘要实现,并在每个时间步通过反馈驱动的文本重写进行更新,从而在不更新参数的情况下实现学习。在固定的token预算下,LLM-as-RNN能够纠正错误并保留任务相关的模式,有效地通过语言执行在线学习。我们在医疗、气象和金融领域的三个序列基准上,针对Llama、Gemma和GPT模型家族评估了该方法。LLM-as-RNN显著优于零样本、完整历史和MemPrompt基线,平均提高了6.5%的预测准确率,同时产生了可解释的、人类可读的学习轨迹,而这是标准上下文累积所不具备的。
🔬 方法详解
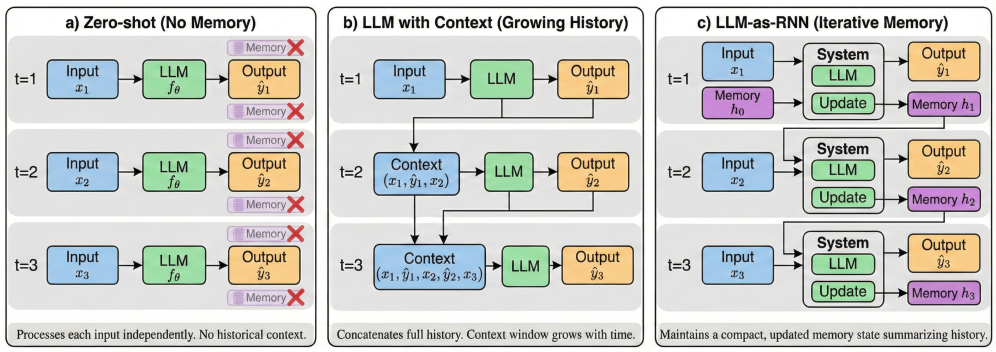
问题定义:现有的大型语言模型在进行序列预测时,通常依赖于固定的上下文历史。这意味着一旦模型在某个时间步犯了错误,这个错误信息会一直保留在上下文中,影响后续的预测。现有的方法缺乏一种有效的机制来动态更新模型的记忆,从而纠正错误并适应新的信息。这种固定的上下文历史限制了模型在动态环境中的表现,尤其是在需要持续学习和适应的任务中。
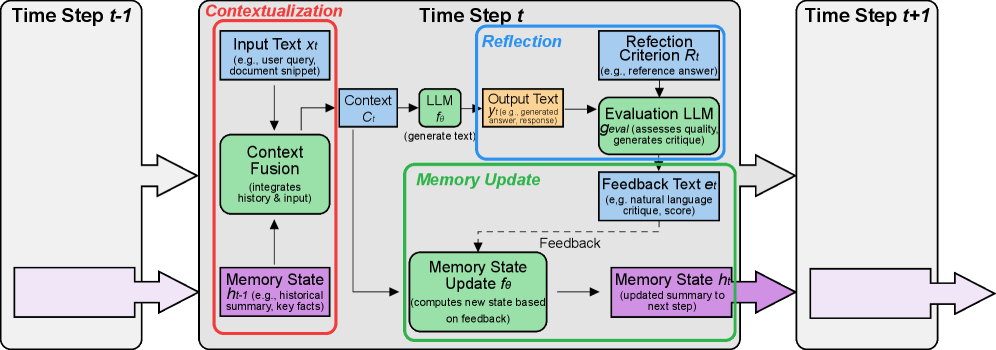
核心思路:LLM-as-RNN的核心思路是将LLM的隐藏状态表示为自然语言形式的记忆。这种记忆以结构化的系统提示摘要的形式存在,并且可以在每个时间步通过反馈驱动的文本重写进行更新。通过这种方式,模型可以在不更新参数的情况下,动态地调整其内部状态,从而纠正错误并学习新的模式。这种方法的核心在于利用LLM本身强大的文本生成能力来管理和更新其自身的记忆。
技术框架:LLM-as-RNN的整体框架包括以下几个主要阶段:1) 初始化:使用初始的系统提示来初始化LLM的记忆。2) 预测:LLM基于当前的记忆生成下一个token或序列。3) 反馈:根据实际情况或预定义的规则,生成反馈信息,例如指示模型是否犯错以及如何纠正。4) 记忆更新:使用反馈信息来重写LLM的记忆,从而更新其内部状态。这个过程会循环进行,直到序列生成完成。
关键创新:LLM-as-RNN最重要的技术创新点在于将LLM的隐藏状态表示为自然语言记忆,并通过反馈驱动的文本重写来实现记忆的动态更新。与传统的RNN不同,LLM-as-RNN不需要训练参数,而是利用LLM本身的文本生成能力来进行学习。与传统的上下文累积方法相比,LLM-as-RNN可以更有效地纠正错误并保留任务相关的模式。
关键设计:LLM-as-RNN的关键设计包括:1) 系统提示的设计:系统提示需要包含足够的信息来指导LLM进行预测,并且需要易于更新。2) 反馈机制的设计:反馈机制需要能够准确地指示模型是否犯错以及如何纠正。3) 文本重写的策略:文本重写的策略需要能够有效地更新LLM的记忆,同时避免引入噪声或错误信息。论文中使用了固定的token预算来限制记忆的长度,并使用特定的prompt工程技术来指导LLM进行文本重写。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM-as-RNN在医疗、气象和金融领域的三个序列基准上,显著优于零样本、完整历史和MemPrompt基线。具体来说,LLM-as-RNN平均提高了6.5%的预测准确率。此外,LLM-as-RNN还能够产生可解释的、人类可读的学习轨迹,这有助于理解模型的决策过程。
🎯 应用场景
LLM-as-RNN具有广泛的应用前景,尤其是在需要持续学习和适应的序列预测任务中。例如,在医疗领域,可以用于预测患者的病情发展;在气象领域,可以用于预测天气变化;在金融领域,可以用于预测股票价格。此外,该方法还可以应用于自然语言处理、机器人控制等领域,提高模型的预测准确性和适应性。
📄 摘要(原文)
Large language models are strong sequence predictors, yet standard inference relies on immutable context histories. After making an error at generation step t, the model lacks an updatable memory mechanism that improves predictions for step t+1. We propose LLM-as-RNN, an inference-only framework that turns a frozen LLM into a recurrent predictor by representing its hidden state as natural-language memory. This state, implemented as a structured system-prompt summary, is updated at each timestep via feedback-driven text rewrites, enabling learning without parameter updates. Under a fixed token budget, LLM-as-RNN corrects errors and retains task-relevant patterns, effectively performing online learning through language. We evaluate the method on three sequential benchmarks in healthcare, meteorology, and finance across Llama, Gemma, and GPT model families. LLM-as-RNN significantly outperforms zero-shot, full-history, and MemPrompt baselines, improving predictive accuracy by 6.5% on average, while producing interpretable, human-readable learning traces absent in standard context accumulation.