Unlearning in LLMs: Methods, Evaluation, and Open Challenges
作者: Tyler Lizzo, Larry Heck
分类: cs.CL
发布日期: 2026-01-19
💡 一句话要点
综述LLM中的Unlearning方法:分类、评估与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器Unlearning 知识移除 隐私保护 模型安全
📋 核心要点
- 大型语言模型面临隐私、版权和偏见等问题,需要有效的Unlearning方法来选择性地移除模型中的知识。
- 本文对LLM的Unlearning方法进行了分类,包括数据中心、参数中心和架构中心等策略,并分析了各种方法的优缺点。
- 论文综述了Unlearning的评估体系,并指出了可扩展性、形式化保证和对抗性攻击等方面的关键挑战和未来研究方向。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理任务中取得了显著成功,但其广泛部署引发了关于隐私、版权、安全和偏见等紧迫问题。机器Unlearning已成为一种有前景的范例,用于选择性地从训练好的模型中移除知识或数据,而无需完全重新训练。本文对LLM的Unlearning方法进行了结构化概述,将现有方法分为数据中心、参数中心、架构中心、混合和其他策略。我们还回顾了评估生态系统,包括旨在衡量遗忘有效性、知识保留和鲁棒性的基准、指标和数据集。最后,我们概述了关键挑战和开放性问题,如可扩展的效率、形式化保证、跨语言和多模态Unlearning以及对抗性重学习的鲁棒性。通过综合当前进展并突出开放方向,本文旨在为开发大型语言模型中可靠和负责任的Unlearning技术提供路线图。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的隐私、版权、安全和偏见等问题。这些问题源于LLM在训练过程中学习并存储了大量敏感或不当信息。现有方法,如完全重新训练模型,成本高昂且效率低下。因此,需要一种更有效、更具选择性的方法来从LLM中移除特定的知识或数据。
核心思路:论文的核心思路是对现有的LLM Unlearning方法进行系统性的分类和评估,从而为研究人员和从业者提供一个全面的视角。通过分析不同方法的优缺点,并识别关键挑战和开放性问题,旨在推动LLM Unlearning领域的发展。
技术框架:论文的技术框架主要包括三个部分:首先,对现有的LLM Unlearning方法进行分类,将其划分为数据中心、参数中心、架构中心、混合和其他策略。其次,回顾用于评估Unlearning效果的评估生态系统,包括基准、指标和数据集。最后,概述LLM Unlearning领域面临的关键挑战和开放性问题,例如可扩展性、形式化保证和对抗性重学习的鲁棒性。
关键创新:论文的主要创新在于其对LLM Unlearning方法的系统性分类和评估。通过将现有方法划分为不同的类别,并分析其优缺点,论文为研究人员提供了一个更清晰的理解框架。此外,论文还强调了LLM Unlearning领域面临的关键挑战和开放性问题,为未来的研究方向提供了指导。
关键设计:论文没有提出新的Unlearning算法或技术细节,而是侧重于对现有方法的综述和分析。因此,没有具体的参数设置、损失函数或网络结构等技术细节需要描述。论文的关键设计在于其分类框架和对评估指标的讨论,这些设计旨在帮助读者更好地理解和评估不同的Unlearning方法。
🖼️ 关键图片
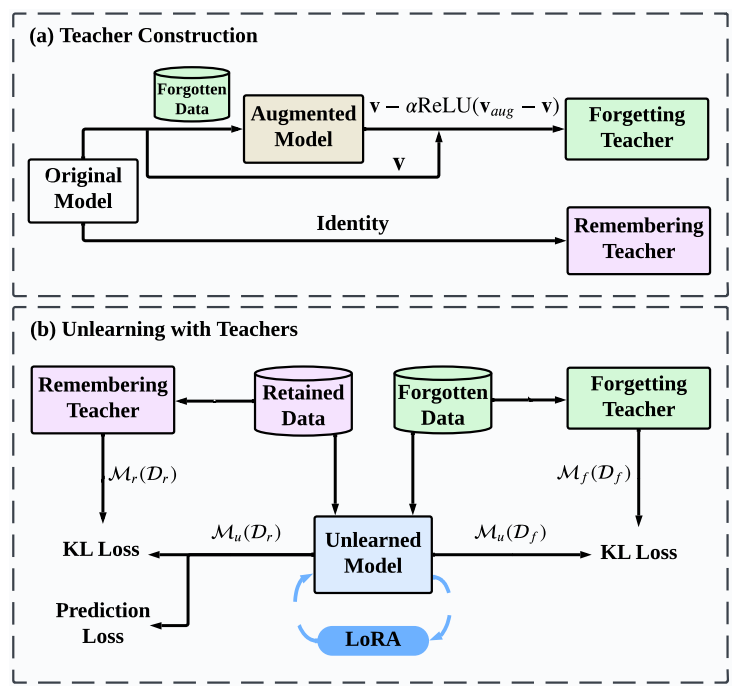
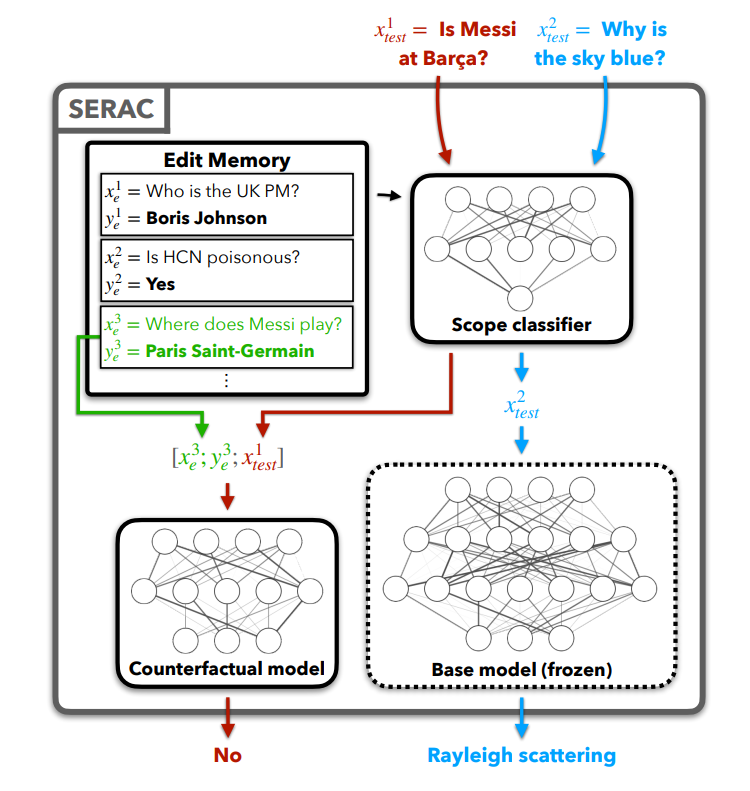
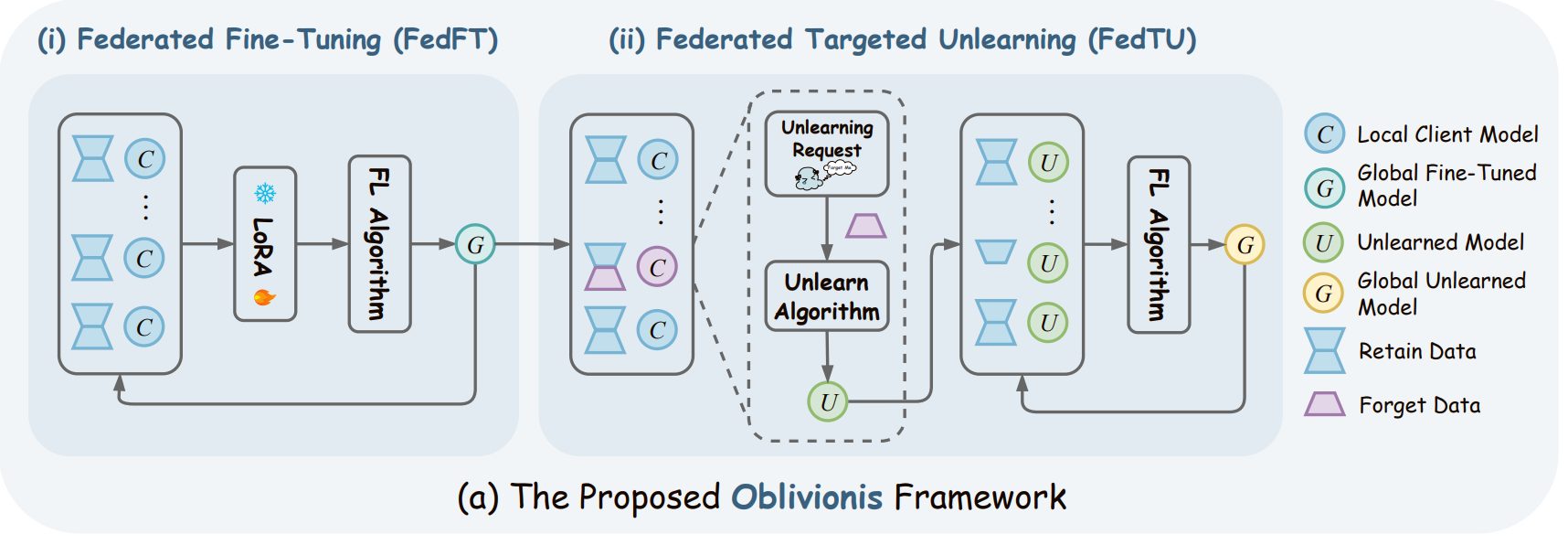
📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。其亮点在于对现有LLM Unlearning方法的系统性分类和评估,以及对未来研究方向的展望。通过总结当前进展并突出开放方向,为开发大型语言模型中可靠和负责任的Unlearning技术提供路线图。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私、遵守版权法规或消除模型偏见的场景。例如,在医疗、金融等敏感数据领域,可以使用Unlearning技术来移除模型中不应保留的个人信息。此外,Unlearning还可以用于修复模型中的错误知识或偏见,提高模型的可靠性和公平性。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable success across natural language processing tasks, yet their widespread deployment raises pressing concerns around privacy, copyright, security, and bias. Machine unlearning has emerged as a promising paradigm for selectively removing knowledge or data from trained models without full retraining. In this survey, we provide a structured overview of unlearning methods for LLMs, categorizing existing approaches into data-centric, parameter-centric, architecture-centric, hybrid, and other strategies. We also review the evaluation ecosystem, including benchmarks, metrics, and datasets designed to measure forgetting effectiveness, knowledge retention, and robustness. Finally, we outline key challenges and open problems, such as scalable efficiency, formal guarantees, cross-language and multimodal unlearning, and robustness against adversarial relearning. By synthesizing current progress and highlighting open directions, this paper aims to serve as a roadmap for developing reliable and responsible unlearning techniques in large language models.