Stop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
作者: Sawsan Alqahtani, Mir Tafseer Nayeem, Md Tahmid Rahman Laskar, Tasnim Mohiuddin, M Saiful Bari
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-19
备注: Accepted to EACL 2026 (long, main). The first two authors contributed equally
💡 一句话要点
重新审视分词器:大型语言模型中的核心设计决策
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分词器 大型语言模型 自然语言处理 子词分词 字节对编码 模型设计 公平性
📋 核心要点
- 现有分词方法(如BPE)虽然可扩展,但与语言结构不一致,易放大偏差,浪费跨领域容量。
- 论文提出上下文感知的分词框架,强调分词器与模型协同设计,并考虑语言、领域和部署因素。
- 论文呼吁标准化分词评估和透明报告,以提高分词选择的责任性和可比性,促进公平高效的语言技术。
📝 摘要(中文)
分词是每个大型语言模型的基础,但它仍然是一个理论不足且设计不一致的组件。诸如字节对编码(BPE)等常见子词方法虽然具有可扩展性,但常常与语言结构不一致,会放大偏差,并浪费跨语言和领域的容量。本文将分词重新定义为核心建模决策,而非预处理步骤。我们主张采用一种上下文感知的框架,该框架整合了分词器和模型的协同设计,并以语言、领域和部署考虑为指导。标准化的评估和透明的报告对于使分词选择具有责任性和可比性至关重要。将分词视为核心设计问题,而非技术上的事后考虑,可以产生更公平、更高效和更具适应性的语言技术。
🔬 方法详解
问题定义:论文关注的是大型语言模型中分词器设计的重要性被低估的问题。现有的分词方法,特别是子词分词方法如BPE,虽然在计算上高效,但存在与语言学结构不匹配、引入偏差以及在不同语言和领域中效率低下的问题。这些问题导致模型性能受限,并且可能加剧社会偏见。
核心思路:论文的核心思路是将分词视为大型语言模型设计中的一个核心决策,而不是一个简单的预处理步骤。作者认为,分词器的设计应该与模型的整体设计紧密结合,并且需要充分考虑语言学、应用领域以及部署环境等因素。通过上下文感知的协同设计,可以构建更公平、更高效和更具适应性的语言模型。
技术框架:论文并没有提出一个具体的新的分词算法或模型架构,而是提出了一个概念框架。这个框架强调以下几个关键步骤:1) 明确分词的目标,例如提高特定语言或领域的性能,减少偏差等;2) 选择合适的分词方法,并根据目标进行调整;3) 将分词器与模型进行协同设计,例如通过调整模型的架构或训练方式来适应分词器的特点;4) 使用标准化的评估指标来评估分词器的性能,并进行透明的报告。
关键创新:论文的关键创新在于其视角上的转变,即将分词从一个技术细节提升到核心设计决策的高度。这种转变促使研究人员更加重视分词器的设计,并将其与模型的整体设计相结合。此外,论文还强调了标准化评估和透明报告的重要性,这有助于提高分词研究的可重复性和可比性。
关键设计:论文没有提供具体的参数设置或网络结构,而是强调了在设计分词器时需要考虑的因素。这些因素包括:1) 语言学知识,例如词根、词缀等;2) 应用领域的特点,例如特定领域的术语和表达方式;3) 部署环境的限制,例如计算资源和延迟要求。论文建议根据这些因素来选择合适的分词方法,并进行相应的调整。
🖼️ 关键图片
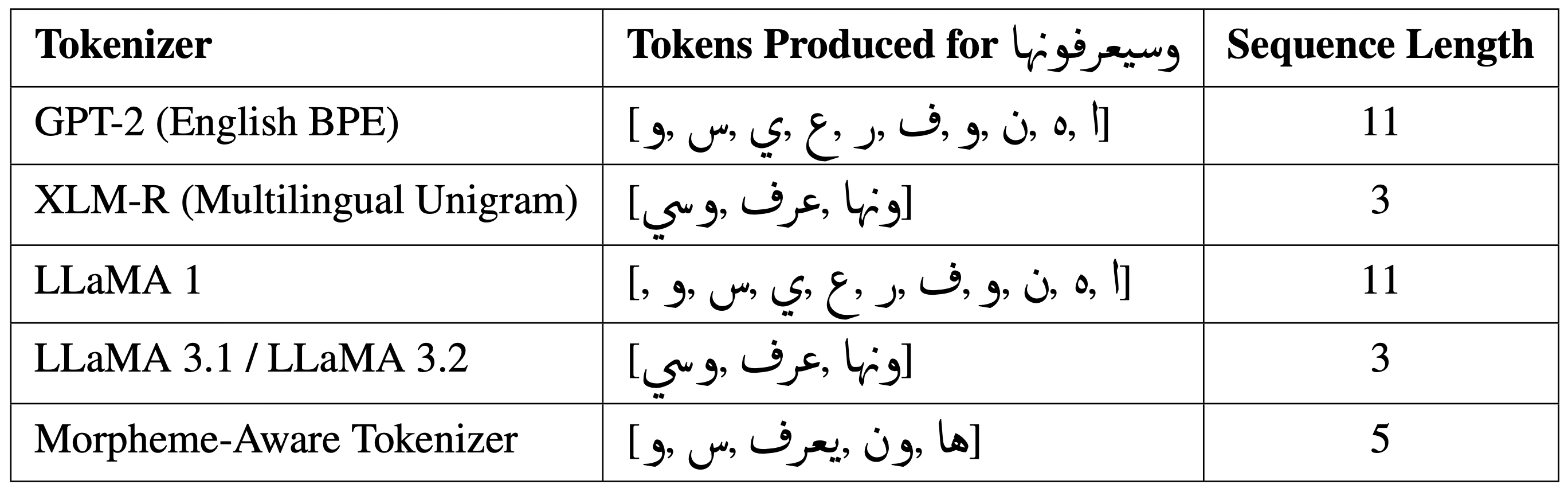
📊 实验亮点
本文主要贡献在于对分词器在大型语言模型中作用的重新评估和定位,并提出了上下文感知的协同设计框架。虽然没有提供具体的实验数据,但强调了标准化评估和透明报告的重要性,为未来的研究方向提供了指导,并有望提升现有语言模型的性能和公平性。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务,尤其是在需要处理多语言、特定领域或存在偏见问题的场景下。通过更合理的分词器设计,可以提升机器翻译、文本生成、情感分析等任务的性能,并减少模型中的偏见,从而构建更公平、更可靠的AI系统。未来的影响在于推动语言模型更加智能化和人性化。
📄 摘要(原文)
Tokenization underlies every large language model, yet it remains an under-theorized and inconsistently designed component. Common subword approaches such as Byte Pair Encoding (BPE) offer scalability but often misalign with linguistic structure, amplify bias, and waste capacity across languages and domains. This paper reframes tokenization as a core modeling decision rather than a preprocessing step. We argue for a context-aware framework that integrates tokenizer and model co-design, guided by linguistic, domain, and deployment considerations. Standardized evaluation and transparent reporting are essential to make tokenization choices accountable and comparable. Treating tokenization as a core design problem, not a technical afterthought, can yield language technologies that are fairer, more efficient, and more adaptable.