Aligning Agentic World Models via Knowledgeable Experience Learning
作者: Baochang Ren, Yunzhi Yao, Rui Sun, Shuofei Qiao, Ningyu Zhang, Huajun Chen
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.MM
发布日期: 2026-01-19
备注: Ongoing work
💡 一句话要点
提出WorldMind框架,通过知识经验学习对齐Agentic世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 世界模型 知识表示 经验学习 物理推理
📋 核心要点
- 大型语言模型缺乏对物理世界规则的理解,导致生成不切实际的计划,现有对齐方法依赖耗时训练难以适应。
- WorldMind框架通过整合环境反馈,构建符号世界知识库,利用过程经验和目标经验来提升模型对物理世界的理解。
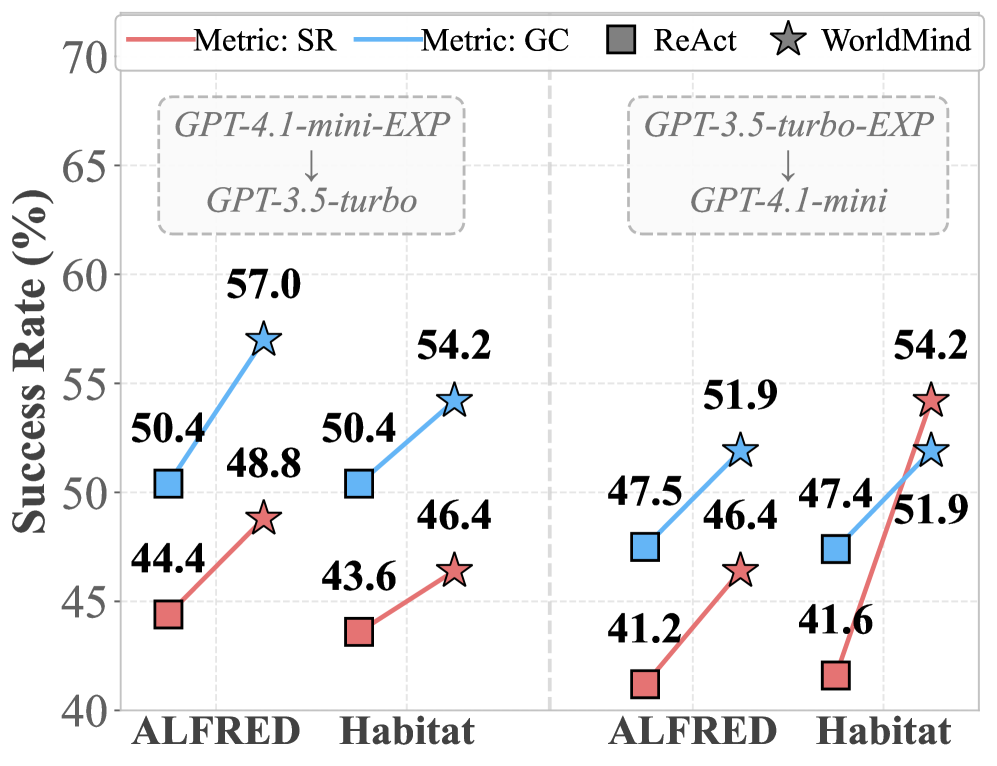
- 实验表明,WorldMind在EB-ALFRED和EB-Habitat上表现优于基线,并展现出良好的跨模型和跨环境迁移能力。
📝 摘要(中文)
当前的大型语言模型(LLMs)存在一个关键的模态断连:它们拥有广阔的语义知识,但缺乏程序性的基础来尊重物理世界的不可变法则。因此,虽然这些智能体隐式地作为世界模型发挥作用,但它们的模拟常常遭受物理幻觉——生成逻辑上合理但物理上不可执行的计划。现有的对齐策略主要依赖于资源密集型的训练或微调,试图将动态环境规则压缩到静态模型参数中。然而,这种参数化封装本质上是僵化的,难以适应物理动力学的开放式可变性,而无需持续的、昂贵的再训练。为了弥合这一差距,我们引入了WorldMind,一个通过综合环境反馈自主构建符号世界知识库的框架。具体来说,它统一了过程经验(Process Experience),通过预测误差来强制执行物理可行性,并统一了目标经验(Goal Experience),通过成功的轨迹来指导任务的最优性。在EB-ALFRED和EB-Habitat上的实验表明,与基线相比,WorldMind实现了卓越的性能,并具有显著的跨模型和跨环境可迁移性。
🔬 方法详解
问题定义:现有的大型语言模型虽然拥有丰富的知识,但缺乏对物理世界规则的理解,导致在生成计划时出现“物理幻觉”,即生成逻辑上可行但物理上不可执行的方案。现有的对齐方法,如训练或微调,试图将动态的环境规则压缩到静态的模型参数中,但这种方法难以适应开放环境的变化,需要持续的再训练,成本高昂。
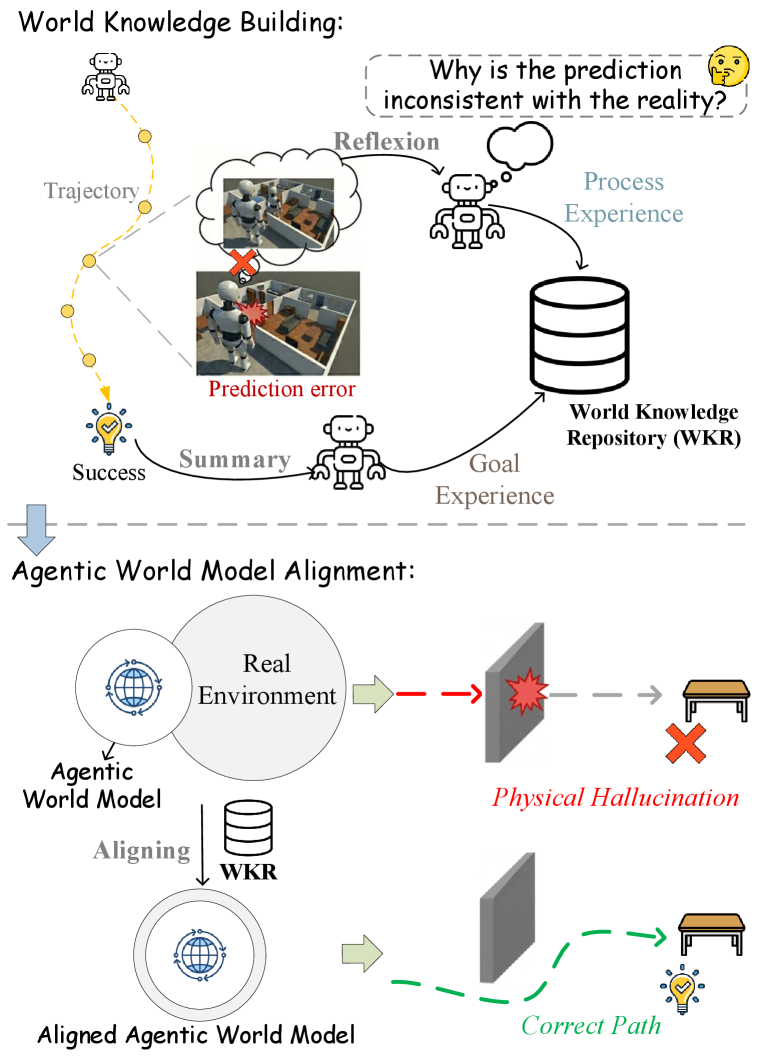
核心思路:WorldMind的核心思路是通过自主构建一个符号世界知识库,让智能体能够从环境反馈中学习物理世界的规则。它将环境反馈分为两类:过程经验(Process Experience)和目标经验(Goal Experience)。过程经验用于纠正模型对物理过程的错误预测,确保物理可行性;目标经验则用于指导模型生成最优的任务执行轨迹。
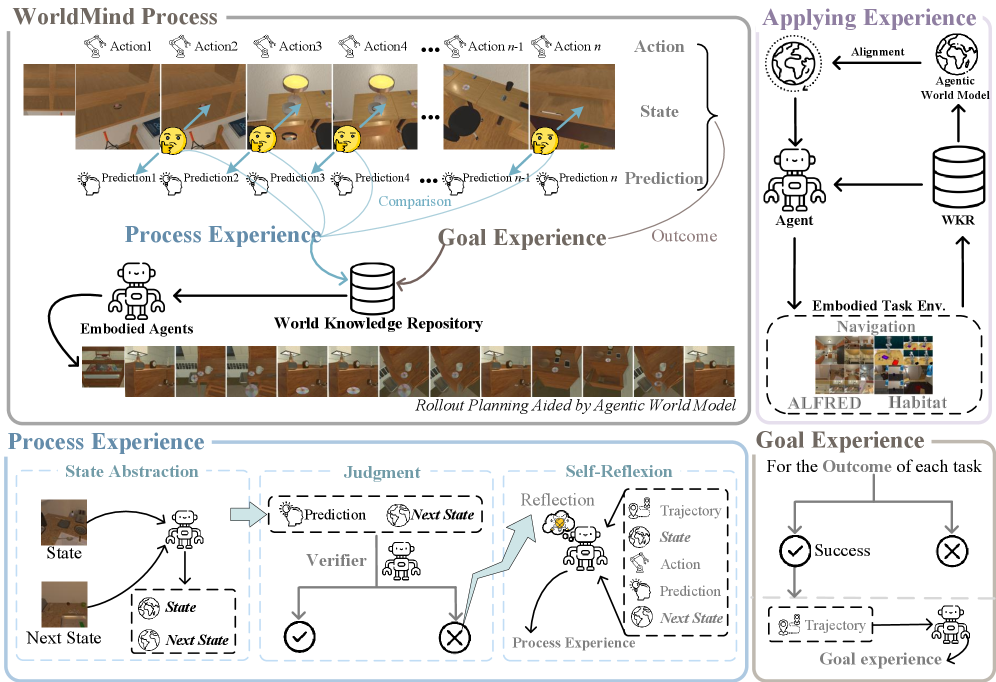
技术框架:WorldMind框架主要包含以下几个模块:1) 环境交互模块:负责与环境进行交互,获取环境反馈。2) 经验提取模块:从环境反馈中提取过程经验和目标经验。3) 知识库构建模块:利用提取的经验构建符号世界知识库。4) 规划模块:利用知识库进行规划,生成可执行的任务计划。整体流程是智能体与环境交互,提取经验,更新知识库,然后利用知识库进行规划。
关键创新:WorldMind的关键创新在于其自主构建符号世界知识库的方式。与传统的参数化方法不同,WorldMind将环境规则显式地存储在知识库中,使得模型能够更容易地理解和利用这些规则。此外,WorldMind通过区分过程经验和目标经验,实现了对物理可行性和任务最优性的双重约束。
关键设计:WorldMind的具体实现细节未知,论文中可能涉及以下关键设计:1) 知识库的表示形式:如何用符号化的方式表示物理世界的规则。2) 经验提取算法:如何从环境反馈中有效地提取过程经验和目标经验。3) 规划算法:如何利用知识库进行高效的规划。4) 损失函数的设计:如何利用预测误差和任务奖励来更新模型和知识库。
🖼️ 关键图片
📊 实验亮点
WorldMind在EB-ALFRED和EB-Habitat两个具有挑战性的具身智能任务上进行了评估,实验结果表明,WorldMind显著优于现有的基线方法。更重要的是,WorldMind展现出了良好的跨模型和跨环境迁移能力,这意味着它可以在不同的智能体和不同的环境中应用,而无需进行大量的重新训练。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、游戏AI等领域。通过让AI智能体更好地理解和遵循物理世界的规则,可以提高其在复杂环境中的决策能力和执行效率,例如,使机器人能够更安全地完成搬运、组装等任务,或使自动驾驶系统能够更准确地预测交通状况并做出合理的驾驶决策。
📄 摘要(原文)
Current Large Language Models (LLMs) exhibit a critical modal disconnect: they possess vast semantic knowledge but lack the procedural grounding to respect the immutable laws of the physical world. Consequently, while these agents implicitly function as world models, their simulations often suffer from physical hallucinations-generating plans that are logically sound but physically unexecutable. Existing alignment strategies predominantly rely on resource-intensive training or fine-tuning, which attempt to compress dynamic environmental rules into static model parameters. However, such parametric encapsulation is inherently rigid, struggling to adapt to the open-ended variability of physical dynamics without continuous, costly retraining. To bridge this gap, we introduce WorldMind, a framework that autonomously constructs a symbolic World Knowledge Repository by synthesizing environmental feedback. Specifically, it unifies Process Experience to enforce physical feasibility via prediction errors and Goal Experience to guide task optimality through successful trajectories. Experiments on EB-ALFRED and EB-Habitat demonstrate that WorldMind achieves superior performance compared to baselines with remarkable cross-model and cross-environment transferability.