Probe and Skip: Self-Predictive Token Skipping for Efficient Long-Context LLM Inference
作者: Zimeng Wu, Donghao Wang, Chaozhe Jin, Jiaxin Chen, Yunhong Wang
分类: cs.CL, cs.LG
发布日期: 2026-01-19
💡 一句话要点
提出SPTS框架,通过自预测token跳过加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 LLM加速 Token跳过 自预测 免训练 注意力机制 前馈网络 模型优化
📋 核心要点
- 现有token剪枝和跳过方法在长文本LLM推理中加速潜力有限,代理信号过时,且易受冗余信息干扰。
- SPTS框架通过部分注意力探测(PAP)和低秩变换探测(LTP)选择性跳过token,无需额外训练。
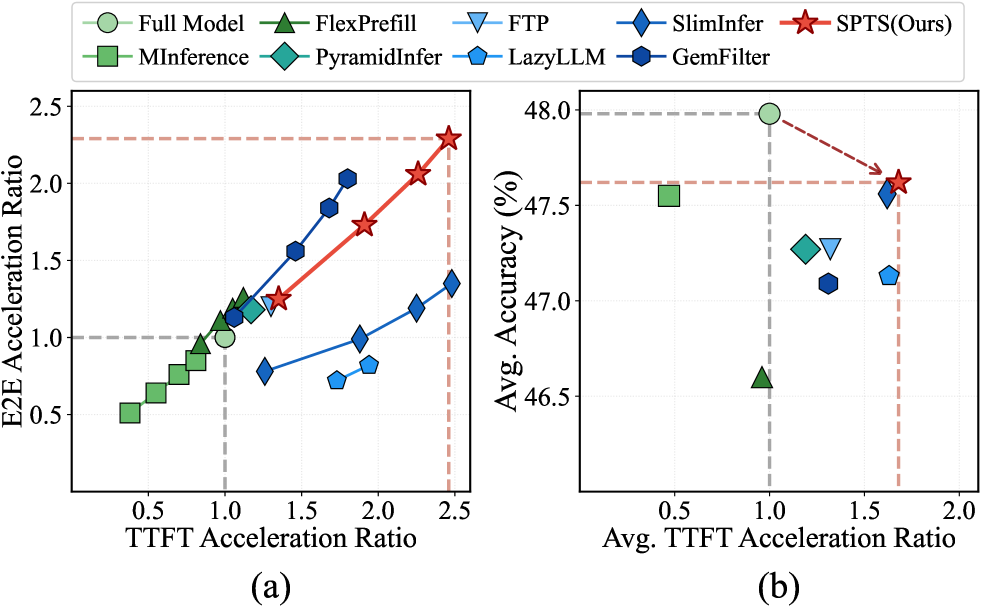
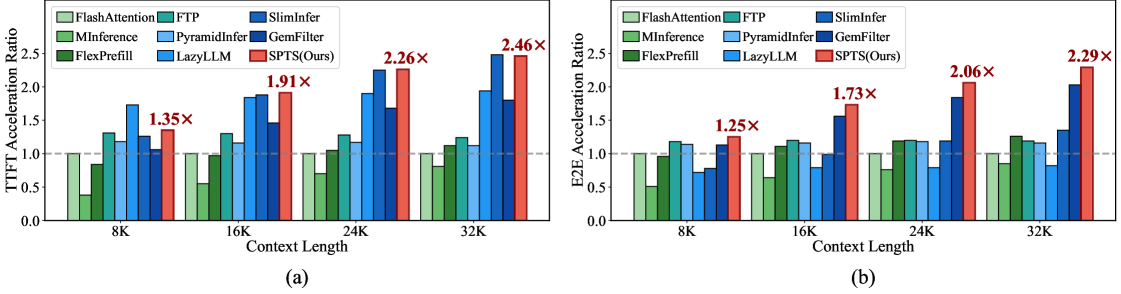
- 实验表明,SPTS在预填充和端到端生成中分别实现了高达2.46倍和2.29倍的加速,并保持了模型性能。
📝 摘要(中文)
长文本推理增强了大型语言模型(LLM)的推理能力,但也带来了显著的计算开销。Token级别的剪枝和跳过等方法在降低推理延迟方面显示出潜力,但仍然受到加速潜力有限、代理信号过时和冗余干扰等问题的限制,从而导致次优的速度-精度权衡。为了解决这些挑战,我们提出了SPTS(自预测Token跳过),这是一个用于高效长文本LLM推理的免训练框架。具体来说,受到探测目标跳过层影响的启发,我们为选择性token跳过设计了两个特定于组件的策略:用于多头注意力的部分注意力探测(PAP),通过执行部分前向注意力计算来选择信息丰富的token;以及用于前馈网络的低秩变换探测(LTP),它构建一个低秩代理网络来预测token变换。此外,多阶段延迟剪枝(MSDP)策略重新分配跳过预算,并逐步剪除跨层的冗余token。大量实验表明了我们方法的有效性,在预填充和端到端生成方面分别实现了高达2.46倍和2.29倍的加速,同时保持了最先进的模型性能。源代码将在论文被接受后公开。
🔬 方法详解
问题定义:论文旨在解决长文本LLM推理过程中计算开销大的问题。现有的token剪枝和跳过方法虽然能降低推理延迟,但存在加速潜力不足、使用的代理信号不够准确(例如直接使用attention score)、以及容易受到冗余信息干扰等痛点,导致速度和精度之间的平衡不佳。
核心思路:论文的核心思路是设计一种自预测的token跳过框架,即SPTS。该框架通过“探测”跳过某些层的影响,来决定哪些token可以安全地跳过,从而减少计算量。核心在于设计高效的探测方法,避免引入过多的额外计算,并保证跳过token后模型性能不受显著影响。
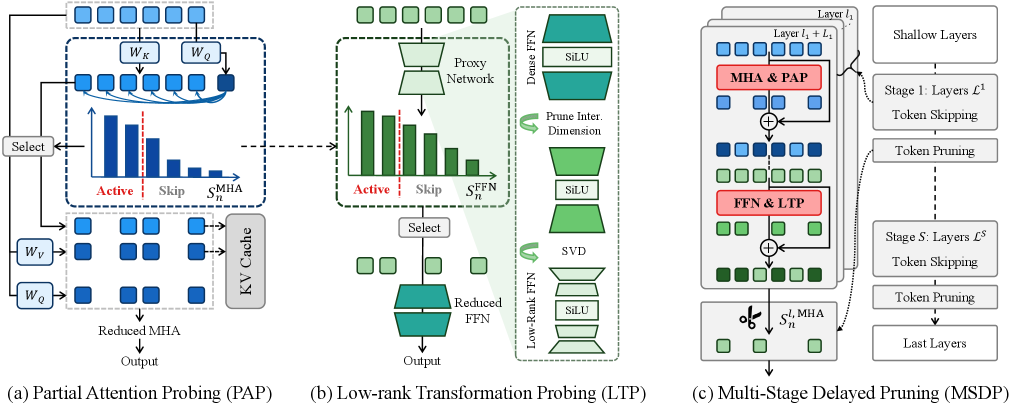
技术框架:SPTS框架包含以下几个主要模块: 1. Partial Attention Probing (PAP):针对多头注意力机制,通过部分前向计算来评估每个token的重要性,从而选择性地跳过不重要的token。 2. Low-rank Transformation Probing (LTP):针对前馈网络(FFN),构建一个低秩代理网络来预测token的变换,以此判断token的重要性。 3. Multi-Stage Delayed Pruning (MSDP):一种多阶段的剪枝策略,用于重新分配跳过预算,并逐步剪除跨层的冗余token。该策略延迟了剪枝决策,以便更好地利用全局信息。
关键创新:论文的关键创新在于提出了基于“探测”思想的token跳过方法,并设计了PAP和LTP两种高效的探测策略。与现有方法直接使用attention score等代理信号不同,SPTS通过实际计算部分网络的前向过程来更准确地评估token的重要性,从而减少了信息损失。MSDP策略进一步优化了跳过预算的分配,提升了整体性能。
关键设计:PAP的关键设计在于如何选择进行部分前向计算的head数量,需要在计算量和准确性之间进行权衡。LTP的关键设计在于低秩代理网络的结构和训练方式,需要保证代理网络能够准确预测token的变换,同时计算开销要足够小。MSDP的关键设计在于如何确定每个阶段的剪枝比例,以及如何平衡不同层之间的跳过预算。
🖼️ 关键图片
📊 实验亮点
SPTS框架在长文本LLM推理中取得了显著的加速效果,在预填充阶段实现了高达2.46倍的加速,在端到端生成阶段实现了高达2.29倍的加速,同时保持了最先进的模型性能。这些结果表明,SPTS是一种高效且实用的长文本LLM推理加速方法。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的LLM应用场景,例如长篇文档摘要、长对话生成、代码生成、以及需要理解长上下文的问答系统等。通过降低推理延迟,可以提升用户体验,并降低部署成本,加速LLM在各行业的落地。
📄 摘要(原文)
Long-context inference enhances the reasoning capability of Large Language Models (LLMs) while incurring significant computational overhead. Token-oriented methods, such as pruning and skipping, have shown promise in reducing inference latency, but still suffer from inherently limited acceleration potential, outdated proxy signals, and redundancy interference, thus yielding suboptimal speed-accuracy trade-offs. To address these challenges, we propose SPTS (Self-Predictive Token Skipping), a training-free framework for efficient long-context LLM inference. Specifically, motivated by the thought of probing the influence of targeted skipping layers, we design two component-specific strategies for selective token skipping: Partial Attention Probing (PAP) for multi-head attention, which selects informative tokens by performing partial forward attention computation, and Low-rank Transformation Probing (LTP) for feed forward network, which constructs a low-rank proxy network to predict token transformations. Furthermore, a Multi-Stage Delayed Pruning (MSDP) strategy reallocates the skipping budget and progressively prunes redundant tokens across layers. Extensive experiments demonstrate the effectiveness of our method, achieving up to 2.46$\times$ and 2.29$\times$ speedups for prefilling and end-to-end generation, respectively, while maintaining state-of-the-art model performance. The source code will be publicly available upon paper acceptance.