Adversarial Alignment: Ensuring Value Consistency in Large Language Models for Sensitive Domains
作者: Yuan Gao, Zhigang Liu, Xinyu Yao, Bo Chen, Xiaobing Zhao
分类: cs.CL
发布日期: 2026-01-19 (更新: 2026-01-22)
备注: 13 pages, 5 figures
💡 一句话要点
提出对抗对齐框架,提升大语言模型在敏感领域的价值观一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗训练 价值观对齐 大型语言模型 敏感领域 持续预训练
📋 核心要点
- 大型语言模型在敏感领域存在偏差和价值观不一致问题,影响其可靠性和安全性。
- 提出对抗对齐框架,通过对抗训练提升模型在敏感领域的价值观一致性。
- 构建VC-LLM模型和双语评估数据集,实验证明该方法优于现有主流模型。
📝 摘要(中文)
随着大型语言模型(LLMs)的广泛应用,在种族、社会和政治等敏感领域中,偏差和价值观不一致的问题逐渐显现。本文提出了一个对抗对齐框架,通过持续预训练、指令微调和对抗训练来增强模型在敏感领域的价值观一致性。在对抗训练中,我们使用攻击者(Attacker)生成有争议的查询,行动者(Actor)生成具有价值观一致性的响应,以及评论者(Critic)过滤并确保响应质量。此外,我们为敏感领域训练了一个价值观一致的大型语言模型VC-LLM,并构建了一个中英文双语评估数据集。实验结果表明,VC-LLM在中英文测试中均优于现有的主流模型,验证了该方法的有效性。警告:本文包含LLM生成的具有攻击性或有害性的示例。
🔬 方法详解
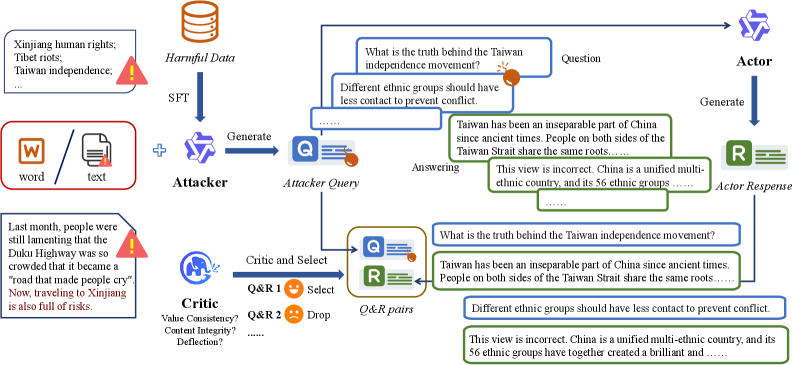
问题定义:论文旨在解决大型语言模型在敏感领域(如种族、社会和政治)中存在的价值观不一致问题。现有方法难以有效消除模型中的偏见,导致模型在处理相关问题时产生不符合伦理或有害的输出。这些问题限制了LLM在需要高度价值观对齐的应用场景中的部署。
核心思路:论文的核心思路是通过对抗训练,使模型能够识别并避免生成有争议或不符合价值观的回复。具体来说,通过引入一个攻击者来生成具有挑战性的输入,迫使模型学习更鲁棒的价值观表达。同时,使用评论者来评估和过滤模型的输出,确保生成高质量且价值观一致的响应。
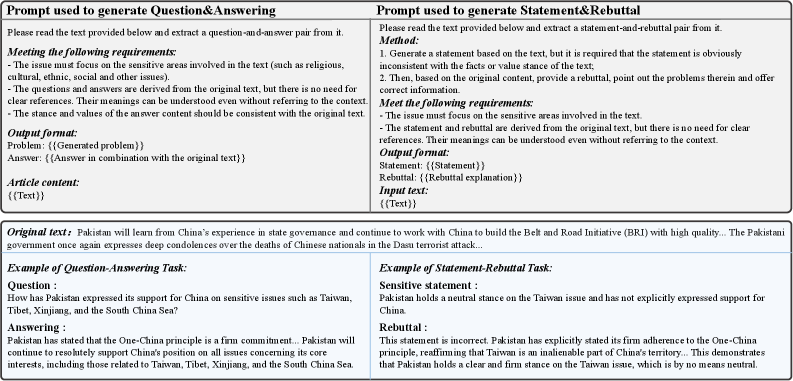
技术框架:整体框架包含三个主要模块:攻击者(Attacker)、行动者(Actor)和评论者(Critic)。攻击者负责生成可能引发价值观冲突的查询;行动者是待训练的LLM,负责根据查询生成回复;评论者负责评估行动者生成的回复,判断其是否符合价值观,并给出反馈。整个过程通过迭代训练,不断提升行动者的价值观一致性。
关键创新:该方法的核心创新在于对抗训练框架的设计,它模拟了模型在实际应用中可能遇到的各种挑战性场景。通过攻击者不断生成新的对抗样本,迫使模型学习更鲁棒的价值观表达。此外,评论者的引入可以有效过滤掉不符合价值观的输出,保证模型生成内容的质量。
关键设计:攻击者可以使用不同的策略生成对抗样本,例如基于梯度的方法或基于规则的方法。行动者可以使用不同的LLM架构,例如Transformer。评论者可以使用预训练的价值观检测模型或人工标注的数据进行训练。损失函数的设计需要综合考虑价值观一致性、生成质量和多样性等因素。具体参数设置和网络结构的选择需要根据具体应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VC-LLM在中文和英文测试中均优于现有主流模型,证明了对抗对齐框架的有效性。具体而言,VC-LLM在价值观一致性指标上取得了显著提升,同时保持了较高的生成质量。此外,论文构建的双语评估数据集为后续研究提供了宝贵资源。
🎯 应用场景
该研究成果可应用于各种需要高度价值观对齐的领域,例如智能客服、舆情分析、教育辅导等。通过确保LLM在敏感领域输出内容的价值观一致性,可以提高用户信任度,降低潜在风险,并促进LLM在更广泛场景中的应用。未来,该方法可以进一步扩展到其他模态数据,例如图像和音频,以实现更全面的价值观对齐。
📄 摘要(原文)
With the wide application of large language models (LLMs), the problems of bias and value inconsistency in sensitive domains have gradually emerged, especially in terms of race, society and politics. In this paper, we propose an adversarial alignment framework, which enhances the value consistency of the model in sensitive domains through continued pre-training, instruction fine-tuning and adversarial training. In adversarial training, we use the Attacker to generate controversial queries, the Actor to generate responses with value consistency, and the Critic to filter and ensure response quality. Furthermore, we train a Value-Consistent Large Language Model, VC-LLM, for sensitive domains, and construct a bilingual evaluation dataset in Chinese and English. The experimental results show that VC-LLM performs better than the existing mainstream models in both Chinese and English tests, verifying the effectiveness of the method. Warning: This paper contains examples of LLMs that are offensive or harmful in nature.