Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
作者: Fengran Mo, Yifan Gao, Sha Li, Hansi Zeng, Xin Liu, Zhaoxuan Tan, Xian Li, Jianshu Chen, Dakuo Wang, Meng Jiang
分类: cs.CL, cs.IR
发布日期: 2026-01-19
💡 一句话要点
提出基于强化学习的Agentic对话搜索模型,通过上下文推理解决多轮对话中的信息检索与生成问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 强化学习 上下文推理 多轮对话 信息检索 深度学习 Agent
📋 核心要点
- 现有对话系统在多轮交互中,难以有效捕捉和利用上下文信息,导致用户意图理解不准确。
- 论文提出一种基于强化学习的对话Agent,通过交错搜索和推理,动态适应用户目标。
- 实验结果表明,该方法在多个对话基准测试中超越了现有基线,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)已成为人机交互的热门界面,通过自然的、多轮对话支持信息检索和任务辅助。为了在多轮对话中响应用户,依赖于上下文的用户意图在交互过程中不断演变,需要上下文解释、查询重构以及检索和生成之间的动态协调。现有研究通常遵循静态的重写、检索和生成流程,分别优化不同的步骤,忽略了混合主动性动作的同步优化。虽然深度搜索代理的最新发展证明了通过推理联合优化检索和生成的有效性,但这些方法侧重于单轮场景,可能缺乏处理多轮交互的能力。我们引入了一种对话代理,它在多轮对话中交错进行搜索和推理,通过强化学习(RL)训练,并针对不断变化的用户目标定制奖励,从而实现探索性和适应性行为。在四个广泛使用的对话基准上的实验结果表明,我们的方法优于几个现有的强大基线,证明了其有效性。
🔬 方法详解
问题定义:现有对话系统通常采用静态的“重写-检索-生成”pipeline,各个模块独立优化,忽略了多轮对话中用户意图的动态变化和混合主动性动作的联合优化。此外,现有的深度搜索Agent主要集中在单轮场景,无法有效处理多轮交互。
核心思路:论文的核心思路是构建一个能够进行上下文推理的对话Agent,该Agent能够在多轮对话中交错进行搜索和推理,并利用强化学习来学习适应用户目标的策略。通过强化学习,Agent可以根据用户反馈和对话历史,动态调整检索和生成策略,从而更好地满足用户的信息需求。
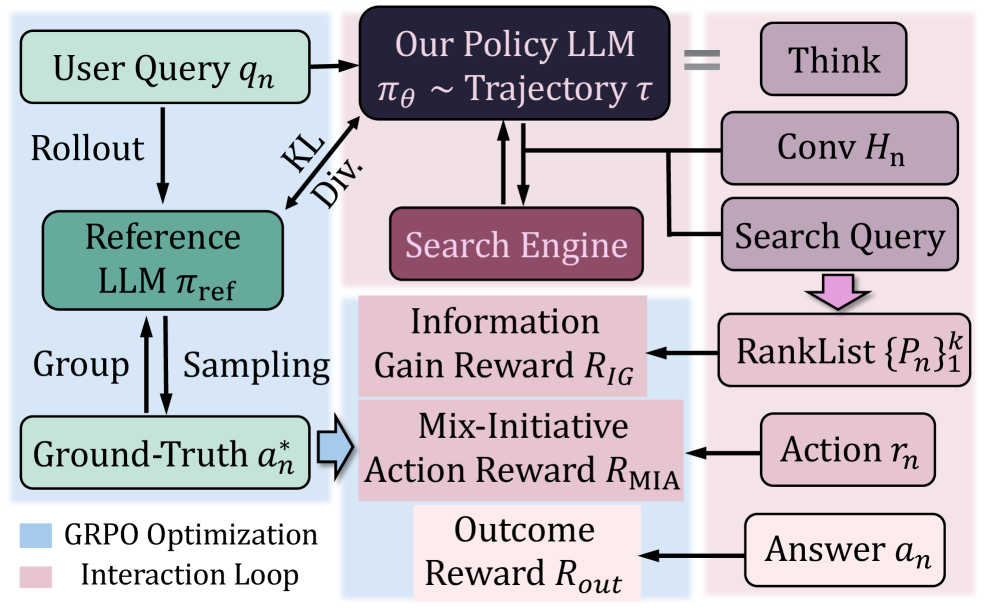
技术框架:该对话Agent的整体框架包含以下几个主要模块:1) 上下文编码器:用于编码对话历史和当前用户query,提取上下文信息。2) 动作选择器:基于上下文信息,选择合适的动作,例如检索相关文档或生成回复。3) 检索模块:根据选择的动作,从知识库中检索相关文档。4) 生成模块:根据检索到的文档和上下文信息,生成回复。5) 奖励函数:根据用户反馈和对话目标,设计奖励函数,用于指导Agent的学习。
关键创新:该论文的关键创新在于:1) 提出了一个能够进行上下文推理的对话Agent,能够更好地理解用户意图。2) 利用强化学习来联合优化检索和生成策略,从而实现更有效的对话。3) 提出了针对多轮对话场景的奖励函数,能够更好地指导Agent的学习。
关键设计:在技术细节方面,论文可能采用了以下设计:1) 使用Transformer等模型作为上下文编码器,以捕捉长距离依赖关系。2) 使用深度Q网络(DQN)或策略梯度等强化学习算法来训练Agent。3) 设计了多目标奖励函数,例如信息检索的准确性和对话的流畅性。4) 探索了不同的动作空间,例如检索不同类型的文档或生成不同风格的回复。
🖼️ 关键图片
📊 实验亮点
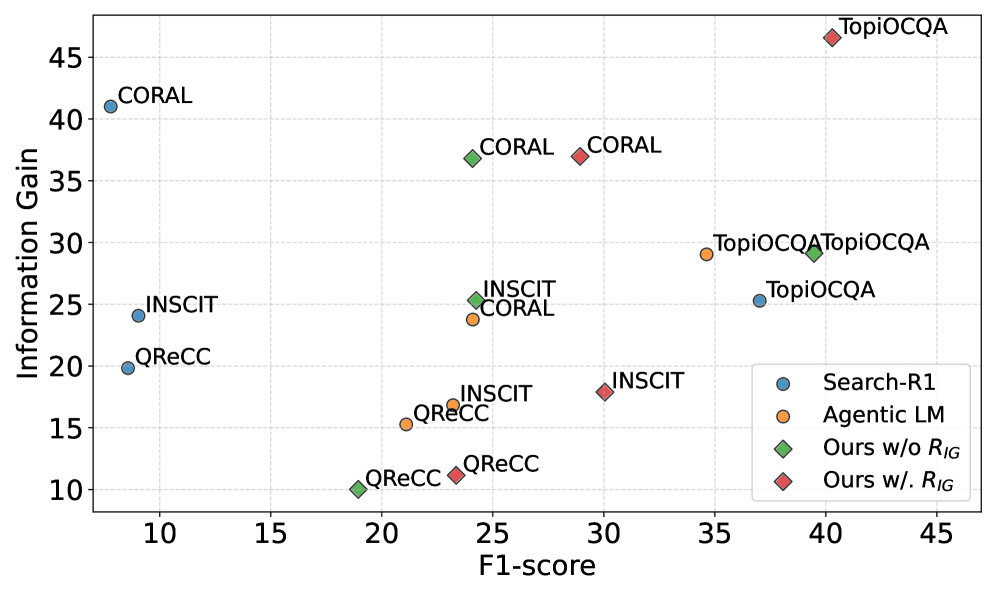
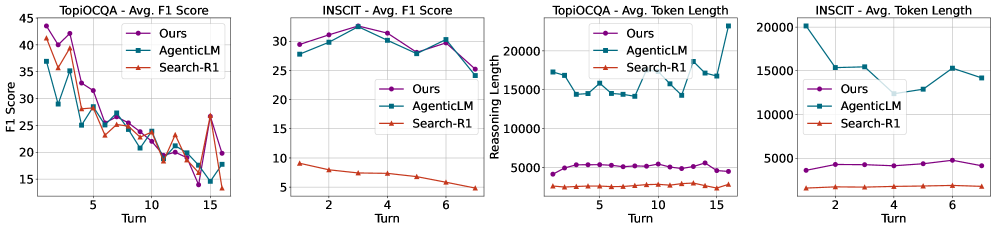
该论文在四个广泛使用的对话基准测试中进行了实验,结果表明,所提出的方法显著优于现有的基线方法。具体的性能提升数据未知,但摘要中明确指出超越了多个“strong baselines”,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于智能客服、虚拟助手、教育机器人等领域,提升对话系统的智能化水平和用户体验。通过更精准的上下文理解和动态的策略调整,对话系统能够更好地满足用户的信息需求,提供更个性化和高效的服务。未来,该技术有望在更复杂的任务型对话场景中发挥重要作用。
📄 摘要(原文)
Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.