SASA: Semantic-Aware Contrastive Learning Framework with Separated Attention for Triple Classification
作者: Xu Xiaodan, Hu Xiaolin
分类: cs.CL, cs.LG
发布日期: 2026-01-19
备注: in progress
💡 一句话要点
提出SASA框架,通过分离注意力机制和语义感知对比学习增强三元组分类。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识图谱 三元组分类 对比学习 注意力机制 语义表示学习
📋 核心要点
- 现有三元组分类方法忽略了知识图谱组件间的有效语义交互,且单一二元分类目标导致语义表示学习不足。
- SASA框架通过分离注意力机制解耦三元组上下文表示,并利用语义感知对比学习增强模型的判别能力。
- 实验结果表明,SASA在FB15k-237和YAGO3-10数据集上分别提升了5.9%和3.4%的准确率,显著优于现有方法。
📝 摘要(中文)
知识图谱(KGs)常常受到不可靠知识的困扰,限制了其效用。三元组分类(TC)旨在确定KG中三元组的有效性。最近,基于文本的方法从自然语言描述中学习实体和关系表示,显著提高了TC模型的泛化能力,并在性能上树立了新的基准。然而,仍然存在两个关键挑战。首先,现有方法通常忽略了不同KG组件之间有效的语义交互。其次,大多数方法采用单一的二元分类训练目标,导致语义表示学习不足。为了应对这些挑战,我们提出了SASA,一种新颖的框架,旨在通过分离注意力机制和语义感知对比学习(CL)来增强TC模型。具体来说,我们首先提出分离注意力机制,将三元组编码为解耦的上下文表示,然后通过更有效的交互方式融合它们。然后,我们引入语义感知分层CL作为辅助训练目标,以指导模型提高其判别能力并实现充分的语义学习,同时考虑局部和全局层面的CL。在两个基准数据集上的实验结果表明,SASA显著优于最先进的方法。在准确率方面,我们在FB15k-237上将最先进水平提高了+5.9%,在YAGO3-10上提高了+3.4%。
🔬 方法详解
问题定义:论文旨在解决知识图谱中三元组分类任务,即判断给定的三元组(头实体,关系,尾实体)是否有效。现有方法的痛点在于,它们无法充分捕捉知识图谱组件之间的语义交互,并且使用单一的二元分类目标导致模型学习到的语义表示不够充分。
核心思路:论文的核心思路是利用分离注意力机制来解耦三元组中各个成分的上下文表示,然后通过语义感知的对比学习来增强模型的判别能力。这种设计旨在更有效地捕捉三元组内部的语义关系,并促使模型学习到更具区分性的表示。
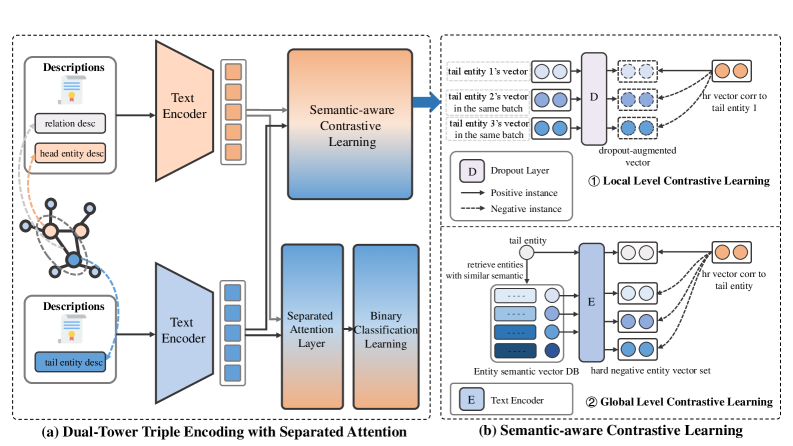
技术框架:SASA框架主要包含两个核心模块:分离注意力机制和语义感知对比学习。首先,分离注意力机制将三元组的头实体、关系和尾实体分别编码成独立的上下文表示。然后,这些表示通过交互方式进行融合。其次,语义感知对比学习模块利用分层对比学习,在局部和全局层面指导模型学习更具判别性的语义表示。整体流程是先通过分离注意力机制获得三元组的表示,再利用对比学习进行优化。
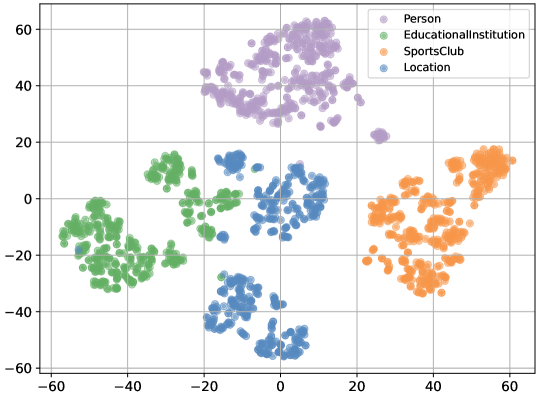
关键创新:SASA的关键创新在于分离注意力机制和语义感知对比学习的结合。分离注意力机制能够更精细地捕捉三元组中各个成分的语义信息,而语义感知对比学习则能够有效地提高模型的判别能力。与现有方法相比,SASA能够更好地利用知识图谱的语义信息,从而提高三元组分类的准确率。
关键设计:分离注意力机制的具体实现方式未知,论文中可能使用了Transformer或其他注意力机制来编码三元组的各个成分。语义感知对比学习可能采用了InfoNCE损失或其他对比学习损失函数,具体细节未知。此外,论文可能还涉及一些超参数的设置,例如对比学习的温度参数等,这些细节也需要参考原文。
🖼️ 关键图片
📊 实验亮点
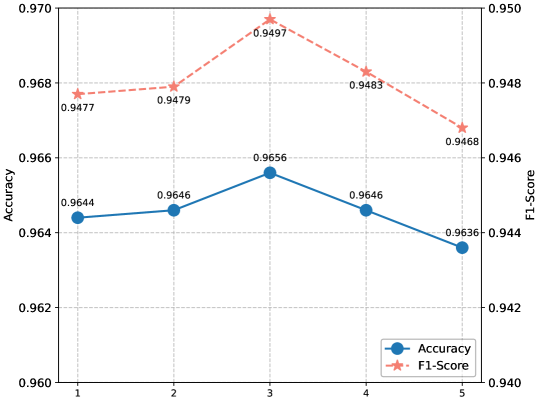
SASA框架在两个基准数据集上取得了显著的性能提升。在FB15k-237数据集上,SASA的准确率比现有最佳方法提高了5.9%。在YAGO3-10数据集上,SASA的准确率提高了3.4%。这些结果表明,SASA能够有效地提高三元组分类的准确率,并为知识图谱相关任务的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于知识图谱补全、知识图谱质量评估、问答系统、推荐系统等领域。通过提高三元组分类的准确率,可以构建更可靠的知识图谱,从而提升下游应用的性能和用户体验。未来,该方法可以扩展到其他知识图谱相关的任务中,例如实体链接、关系抽取等。
📄 摘要(原文)
Knowledge Graphs~(KGs) often suffer from unreliable knowledge, which restricts their utility. Triple Classification~(TC) aims to determine the validity of triples from KGs. Recently, text-based methods learn entity and relation representations from natural language descriptions, significantly improving the generalization capabilities of TC models and setting new benchmarks in performance. However, there are still two critical challenges. First, existing methods often ignore the effective semantic interaction among different KG components. Second, most approaches adopt single binary classification training objective, leading to insufficient semantic representation learning. To address these challenges, we propose \textbf{SASA}, a novel framework designed to enhance TC models via separated attention mechanism and semantic-aware contrastive learning~(CL). Specifically, we first propose separated attention mechanism to encode triples into decoupled contextual representations and then fuse them through a more effective interactive way. Then, we introduce semantic-aware hierarchical CL as auxiliary training objective to guide models in improving their discriminative capabilities and achieving sufficient semantic learning, considering both local level and global level CL. Experimental results across two benchmark datasets demonstrate that SASA significantly outperforms state-of-the-art methods. In terms of accuracy, we advance the state-of-the-art by +5.9\% on FB15k-237 and +3.4\% on YAGO3-10.