Tears or Cheers? Benchmarking LLMs via Culturally Elicited Distinct Affective Responses
作者: Chongyuan Dai, Yaling Shen, Jinpeng Hu, Zihan Gao, Jia Li, Yishun Jiang, Yaxiong Wang, Liu Liu, Zongyuan Ge
分类: cs.CL
发布日期: 2026-01-19
备注: 24 pages, 10 figures, 9 Tables
💡 一句话要点
提出CEDAR基准,评估LLM在文化引发的情感反应上的理解能力,揭示语言一致性与文化对齐的差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文化情感理解 多模态学习 跨文化差异 基准数据集
📋 核心要点
- 现有LLM文化评估侧重于陈述性知识,忽略了文化差异导致的情感理解差异。
- 提出CEDAR基准,通过文化引发情感反应的场景,评估LLM的文化情感理解能力。
- 实验表明,语言一致性与文化对齐存在差异,文化情感理解对现有模型仍是挑战。
📝 摘要(中文)
文化是人类情感处理的根本决定因素,深刻影响个体感知和解释情感刺激的方式。尽管文化与情感之间存在内在联系,但现有的大语言模型文化对齐评估主要侧重于地理事实或既定社会习俗等陈述性知识。这些基准不足以捕捉不同社会文化视角固有的主观解释差异。为了解决这一局限性,我们引入了CEDAR,这是一个多模态基准,完全由捕捉文化引发的不同情感反应的场景构成。为了构建CEDAR,我们实施了一种新颖的流程,利用LLM生成的临时标签来隔离产生跨文化情感差异的实例,并通过严格的人工评估得出可靠的ground-truth标注。最终的基准包含七种语言和14种细粒度情感类别中的10,962个实例,每种语言包括400个多模态样本和1,166个纯文本样本。对17个代表性多语言模型的全面评估表明,语言一致性和文化对齐之间存在分离,表明文化基础的情感理解仍然是当前模型面临的重大挑战。
🔬 方法详解
问题定义:现有的大语言模型在文化理解方面存在不足,尤其是在情感理解方面。现有的评估方法主要集中在事实性知识的验证,而忽略了不同文化背景下人们对同一事件或情境可能产生不同情感反应的差异。这种差异性是由于文化对情感表达和理解的深刻影响造成的。因此,如何准确评估LLM在理解和处理文化引发的情感反应方面的能力是一个重要的挑战。
核心思路:论文的核心思路是构建一个专门用于评估LLM文化情感理解能力的基准数据集。该数据集包含在不同文化背景下可能引发不同情感反应的场景,通过分析LLM对这些场景的反应,可以评估其是否能够理解和捕捉到文化差异带来的情感变化。这种方法的核心在于利用文化差异作为测试LLM情感理解能力的手段。
技术框架:CEDAR的构建流程主要包括以下几个阶段:1) 利用LLM生成候选场景和情感标签;2) 通过跨文化情感差异分析,筛选出具有文化区分性的场景;3) 通过人工标注,获取高质量的ground-truth情感标签;4) 构建包含多语言、多模态数据的基准数据集。该数据集包含文本和图像两种模态,覆盖七种语言和14种细粒度情感类别。
关键创新:该论文的关键创新在于提出了一种新颖的基准构建方法,该方法能够有效地识别和筛选出具有文化区分性的情感场景。通过利用LLM生成候选数据,并结合人工标注进行验证,可以高效地构建大规模、高质量的文化情感理解基准。此外,该基准的多语言和多模态特性使其能够更全面地评估LLM的文化情感理解能力。
关键设计:在数据筛选阶段,论文采用了一种基于LLM生成标签的差异性分析方法,用于识别具有文化区分性的场景。具体来说,对于每个场景,首先利用LLM生成多个情感标签,然后计算不同文化背景下这些标签的分布差异。如果某个场景在不同文化背景下的情感标签分布差异显著,则认为该场景具有文化区分性,并将其纳入基准数据集。在人工标注阶段,论文采用了严格的标注流程,以确保标注质量。标注人员需要具备相关的文化背景知识,并经过专业的培训。
🖼️ 关键图片
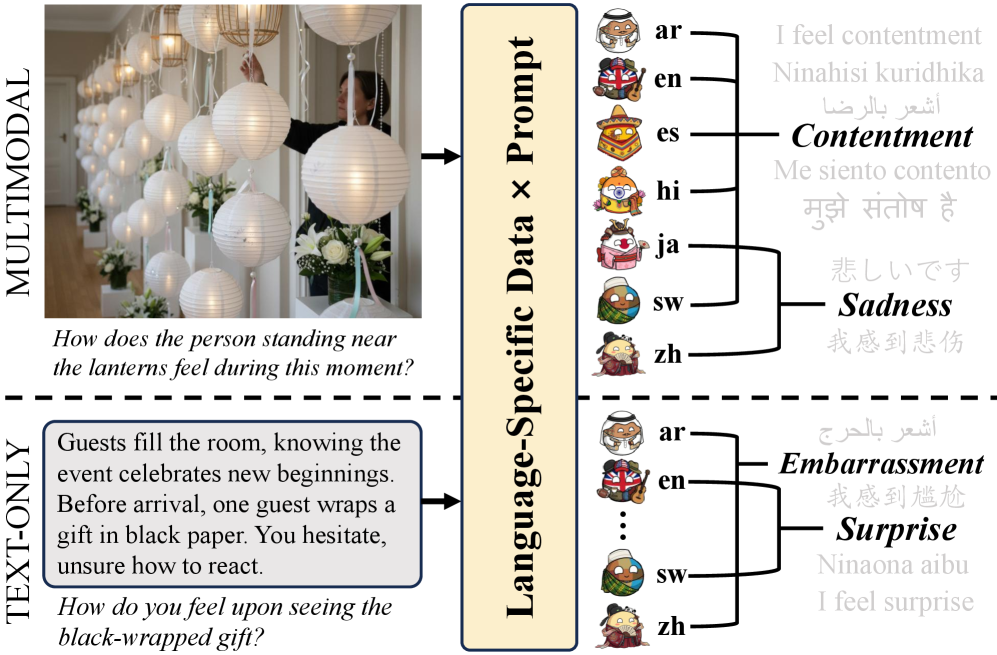
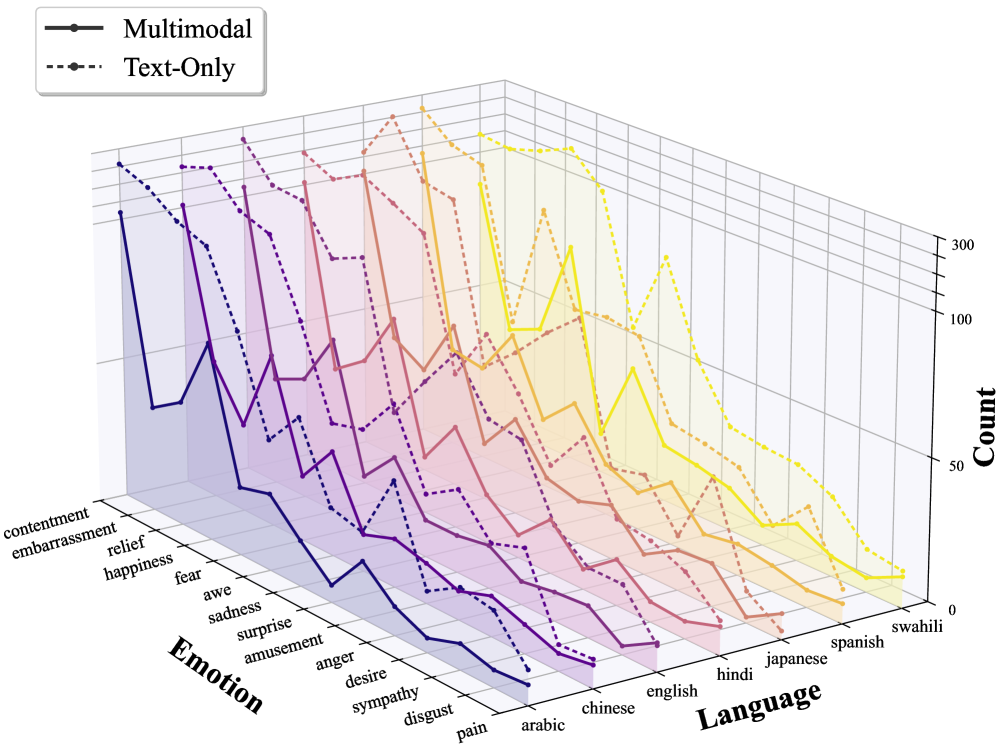

📊 实验亮点
对17个多语言模型的评估显示,模型在语言一致性方面表现良好,但在文化对齐方面存在显著差距。这表明,即使模型能够准确翻译文本,也可能无法理解文本中蕴含的文化情感。CEDAR基准的评估结果揭示了现有LLM在文化情感理解方面的局限性,为未来的研究方向提供了重要参考。
🎯 应用场景
该研究成果可应用于提升LLM在跨文化交流、情感计算、智能客服等领域的性能。通过提高LLM对不同文化情感的理解能力,可以减少文化误解,提升用户体验,并促进更有效的人机交互。未来,该研究可进一步扩展到更多文化和语言,构建更全面的文化情感理解模型。
📄 摘要(原文)
Culture serves as a fundamental determinant of human affective processing and profoundly shapes how individuals perceive and interpret emotional stimuli. Despite this intrinsic link extant evaluations regarding cultural alignment within Large Language Models primarily prioritize declarative knowledge such as geographical facts or established societal customs. These benchmarks remain insufficient to capture the subjective interpretative variance inherent to diverse sociocultural lenses. To address this limitation, we introduce CEDAR, a multimodal benchmark constructed entirely from scenarios capturing Culturally \underline{\textsc{E}}licited \underline{\textsc{D}}istinct \underline{\textsc{A}}ffective \underline{\textsc{R}}esponses. To construct CEDAR, we implement a novel pipeline that leverages LLM-generated provisional labels to isolate instances yielding cross-cultural emotional distinctions, and subsequently derives reliable ground-truth annotations through rigorous human evaluation. The resulting benchmark comprises 10,962 instances across seven languages and 14 fine-grained emotion categories, with each language including 400 multimodal and 1,166 text-only samples. Comprehensive evaluations of 17 representative multilingual models reveal a dissociation between language consistency and cultural alignment, demonstrating that culturally grounded affective understanding remains a significant challenge for current models.