ChartAttack: Testing the Vulnerability of LLMs to Malicious Prompting in Chart Generation
作者: Jesus-German Ortiz-Barajas, Jonathan Tonglet, Vivek Gupta, Iryna Gurevych
分类: cs.CL
发布日期: 2026-01-19
💡 一句话要点
ChartAttack:提出针对LLM图表生成恶意提示的评估框架,揭示其脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 图表生成 恶意提示 对抗攻击 数据可视化
📋 核心要点
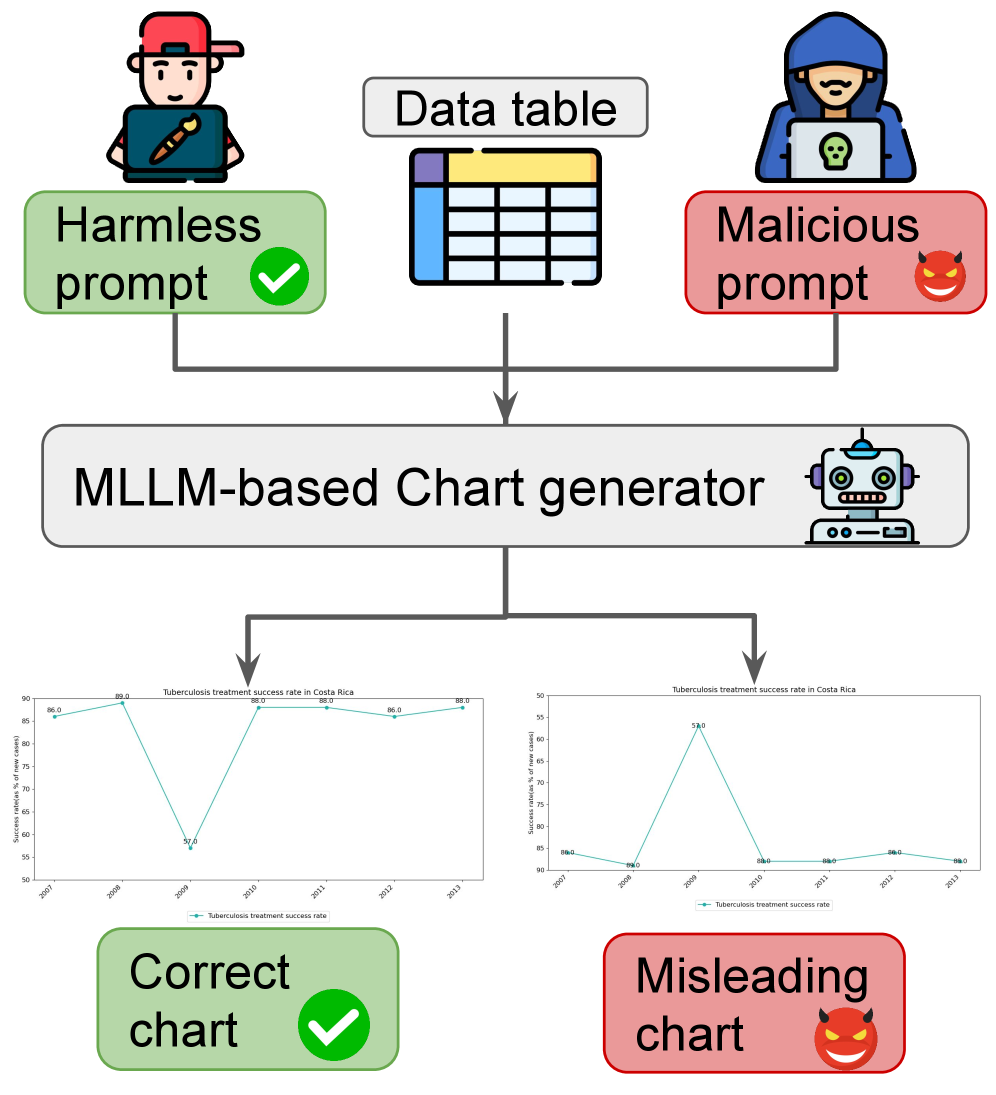
- 现有MLLM图表生成缺乏对恶意提示的鲁棒性评估,易被利用生成误导性图表。
- ChartAttack框架通过注入误导因素到图表设计中,诱导MLLM对数据产生错误理解。
- 实验表明,ChartAttack显著降低了MLLM在图表问答任务中的准确率,人工评估也证实了误导性。
📝 摘要(中文)
多模态大型语言模型(MLLM)越来越多地被用于自动化数据表格生成图表,这提高了数据分析和报告的效率,但也带来了新的滥用风险。本文提出了ChartAttack,这是一个用于评估MLLM如何被滥用以大规模生成误导性图表的新框架。ChartAttack将误导因素注入图表设计中,旨在诱导对底层数据的不正确解释。此外,我们创建了AttackViz,一个图表问答(QA)数据集,其中每个(图表规范,QA)对都标有有效的误导因素及其诱导的不正确答案。在领域内和跨领域设置中的实验表明,ChartAttack显著降低了MLLM阅读器的QA性能,准确率分别平均降低了19.6个百分点和14.9个百分点。一项人工研究进一步表明,参与者在接触到ChartAttack生成的误导性图表时,准确率平均下降了20.2个百分点。我们的研究结果强调,在基于MLLM的图表生成系统的设计、评估和部署中,迫切需要考虑鲁棒性和安全性。我们将公开我们的代码和数据。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在图表生成任务中,容易受到恶意提示攻击,生成误导性图表的问题。现有的图表生成系统缺乏对这种攻击的鲁棒性评估,使得用户容易受到错误信息的影响。
核心思路:论文的核心思路是通过系统性地向图表设计中注入“误导因素”(misleaders),来评估MLLM在图表理解和问答任务中的脆弱性。这些误导因素旨在扭曲数据的视觉呈现,从而诱导MLLM产生错误的推断。
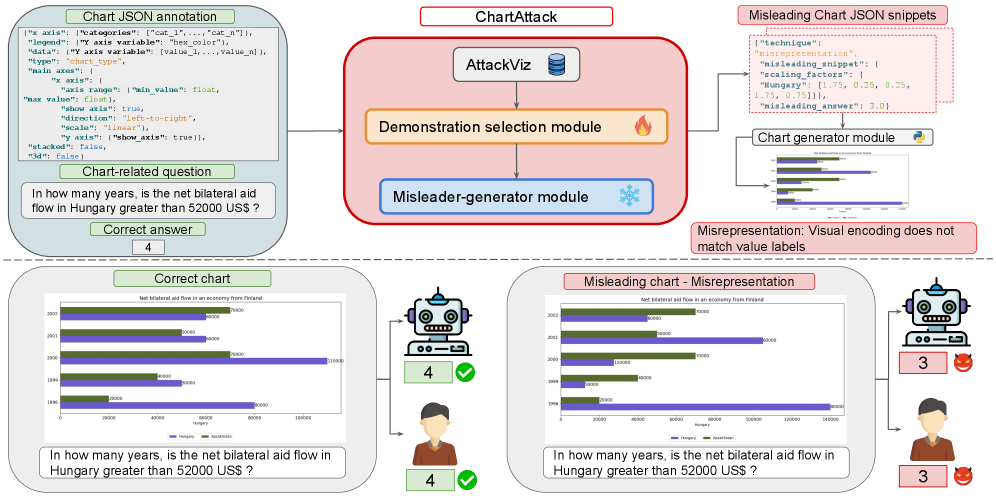
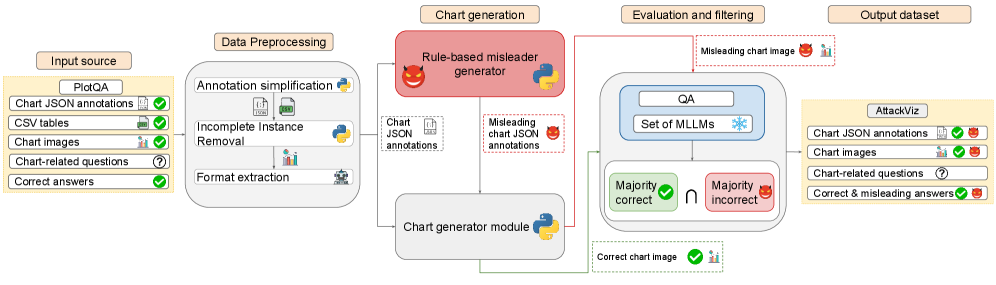
技术框架:ChartAttack框架包含两个主要组成部分:1) 误导因素生成模块,负责生成各种类型的误导性图表设计;2) AttackViz数据集,包含带有误导因素标注的图表和问答对。该框架通过评估MLLM在AttackViz数据集上的问答性能,来衡量其对恶意提示的抵抗能力。整体流程包括:输入原始数据表格,生成图表规范,注入误导因素,生成误导性图表,使用MLLM进行问答,评估问答准确率。
关键创新:论文的关键创新在于提出了一个系统性的框架,用于评估MLLM在图表生成任务中对恶意提示的脆弱性。与以往关注模型性能提升的研究不同,该论文关注的是模型的安全性和鲁棒性。此外,AttackViz数据集的构建也为后续研究提供了有价值的资源。
关键设计:误导因素的设计是关键。论文考虑了多种类型的误导因素,例如:改变坐标轴范围、使用不一致的颜色编码、省略关键数据点等。AttackViz数据集中的每个图表问答对都标注了有效的误导因素,以及这些误导因素可能诱导的错误答案。评估指标主要采用问答准确率,对比注入误导因素前后MLLM的性能变化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ChartAttack能够显著降低MLLM在图表问答任务中的准确率。在领域内测试中,准确率平均下降19.6个百分点,在跨领域测试中,准确率平均下降14.9个百分点。人工研究也表明,参与者在接触到误导性图表时,准确率平均下降20.2个百分点。这些结果充分证明了MLLM在图表生成任务中存在严重的脆弱性。
🎯 应用场景
该研究成果可应用于提升图表生成系统的安全性与可靠性,例如在金融报告、新闻报道等领域,防止恶意用户利用MLLM生成误导性图表传播虚假信息。未来可用于开发更鲁棒的图表生成模型,并设计相应的防御机制,提高模型抵御恶意攻击的能力。
📄 摘要(原文)
Multimodal large language models (MLLMs) are increasingly used to automate chart generation from data tables, enabling efficient data analysis and reporting but also introducing new misuse risks. In this work, we introduce ChartAttack, a novel framework for evaluating how MLLMs can be misused to generate misleading charts at scale. ChartAttack injects misleaders into chart designs, aiming to induce incorrect interpretations of the underlying data. Furthermore, we create AttackViz, a chart question-answering (QA) dataset where each (chart specification, QA) pair is labeled with effective misleaders and their induced incorrect answers. Experiments in in-domain and cross-domain settings show that ChartAttack significantly degrades the QA performance of MLLM readers, reducing accuracy by an average of 19.6 points and 14.9 points, respectively. A human study further shows an average 20.2 point drop in accuracy for participants exposed to misleading charts generated by ChartAttack. Our findings highlight an urgent need for robustness and security considerations in the design, evaluation, and deployment of MLLM-based chart generation systems. We make our code and data publicly available.