The Bitter Lesson of Diffusion Language Models for Agentic Workflows: A Comprehensive Reality Check
作者: Qingyu Lu, Liang Ding, Kanjian Zhang, Jinxia Zhang, Dacheng Tao
分类: cs.CL
发布日期: 2026-01-19
备注: Under Review
💡 一句话要点
扩散语言模型在Agent任务中表现不佳,需引入因果推理机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 Agent任务 具身Agent 工具调用 因果推理 多Agent系统 DiffuAgent
📋 核心要点
- 现有自回归语言模型在实时Agent交互中存在顺序延迟瓶颈,限制了Agent的效率。
- 论文探索了基于扩散的语言模型(dLLMs)作为Agent主干网络的可行性,旨在打破延迟瓶颈。
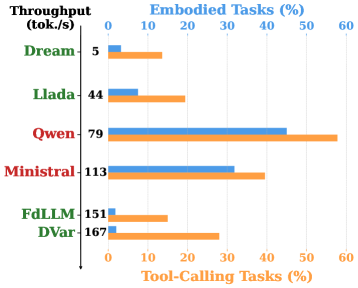
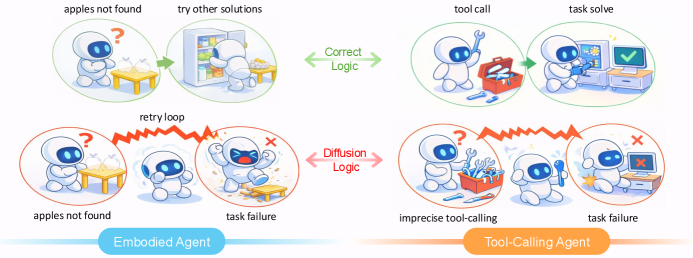
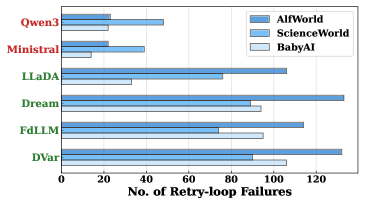
- 实验表明,dLLMs在具身Agent和工具调用Agent任务中表现不佳,需要引入因果推理机制。
📝 摘要(中文)
本文全面评估了基于扩散的语言模型(dLLMs)作为自回归主干网络的替代方案,在实时Agent交互中的表现。尽管dLLMs有望打破顺序延迟瓶颈,但其在具身Agent(需要长程规划)和工具调用Agent(需要精确格式)两种Agent范式下的表现并不理想。在Agentboard和BFCL上的实验结果表明,dLLMs难以作为可靠的Agent主干网络,经常导致系统性失败。具体来说,dLLMs在具身环境中重复尝试失败,无法在时间反馈下进行分支;在工具调用环境中,dLLMs无法在扩散噪声下保持符号精度(如严格的JSON模式)。为了评估dLLMs在Agent工作流中的潜力,本文提出了DiffuAgent,一个集成了dLLMs作为即插即用认知核心的多Agent评估框架。分析表明,dLLMs在非因果角色(如记忆总结和工具选择)中有效,但需要将因果、精确和逻辑推理机制融入到去噪过程中,才能适用于Agent任务。
🔬 方法详解
问题定义:现有自回归语言模型在Agent任务中存在推理延迟,限制了实时交互能力。扩散语言模型(dLLMs)被认为是解决这一问题的潜在方案,但其在实际Agent任务中的表现尚不明确。现有研究缺乏对dLLMs在不同Agent范式下的全面评估,以及对dLLMs失效原因的深入分析。
核心思路:论文的核心思路是通过实验评估dLLMs在具身Agent和工具调用Agent两种典型Agent任务中的表现,分析其优势和不足。通过引入DiffuAgent框架,研究dLLMs在多Agent环境下的潜力,并探讨如何改进dLLMs以使其更适合Agent任务。
技术框架:论文提出了DiffuAgent框架,该框架将dLLMs作为即插即用的认知核心,集成到多Agent环境中。该框架允许研究人员评估dLLMs在不同Agent角色中的表现,例如记忆总结和工具选择。同时,论文还设计了针对具身Agent和工具调用Agent的评估任务,以全面测试dLLMs的能力。
关键创新:论文的关键创新在于对dLLMs在Agent任务中的系统性评估,揭示了dLLMs在因果推理和符号精度方面的不足。DiffuAgent框架的提出为研究dLLMs在多Agent环境下的应用提供了新的平台。论文还提出了改进dLLMs的思路,即引入因果、精确和逻辑推理机制到去噪过程中。
关键设计:DiffuAgent框架的关键设计包括:1) 将dLLMs作为可替换的认知核心,方便集成不同的dLLMs模型;2) 提供多种Agent角色,例如记忆总结Agent和工具选择Agent;3) 设计了Agentboard和BFCL等评估环境,用于测试dLLMs在具身Agent和工具调用Agent任务中的表现。论文还针对工具调用Agent任务,设计了严格的JSON模式,用于评估dLLMs的符号精度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,dLLMs在具身Agent任务中表现不佳,无法在时间反馈下进行有效的分支探索。在工具调用Agent任务中,dLLMs难以保持符号精度,例如生成符合严格JSON模式的输出。DiffuAgent框架的评估结果表明,dLLMs在非因果角色(如记忆总结和工具选择)中表现较好,但在需要因果推理的任务中表现欠佳。
🎯 应用场景
该研究成果可应用于机器人、智能助手、游戏AI等领域,帮助开发者更好地选择和改进Agent模型。通过引入因果推理机制,可以提升Agent的决策能力和任务完成效率,从而实现更智能、更可靠的Agent系统。未来的研究可以探索更有效的因果推理方法,并将其集成到dLLMs中,以进一步提升Agent的性能。
📄 摘要(原文)
The pursuit of real-time agentic interaction has driven interest in Diffusion-based Large Language Models (dLLMs) as alternatives to auto-regressive backbones, promising to break the sequential latency bottleneck. However, does such efficiency gains translate into effective agentic behavior? In this work, we present a comprehensive evaluation of dLLMs (e.g., LLaDA, Dream) across two distinct agentic paradigms: Embodied Agents (requiring long-horizon planning) and Tool-Calling Agents (requiring precise formatting). Contrary to the efficiency hype, our results on Agentboard and BFCL reveal a "bitter lesson": current dLLMs fail to serve as reliable agentic backbones, frequently leading to systematically failure. (1) In Embodied settings, dLLMs suffer repeated attempts, failing to branch under temporal feedback. (2) In Tool-Calling settings, dLLMs fail to maintain symbolic precision (e.g. strict JSON schemas) under diffusion noise. To assess the potential of dLLMs in agentic workflows, we introduce DiffuAgent, a multi-agent evaluation framework that integrates dLLMs as plug-and-play cognitive cores. Our analysis shows that dLLMs are effective in non-causal roles (e.g., memory summarization and tool selection) but require the incorporation of causal, precise, and logically grounded reasoning mechanisms into the denoising process to be viable for agentic tasks.