From Prefix Cache to Fusion RAG Cache: Accelerating LLM Inference in Retrieval-Augmented Generation
作者: Jiahao Wang, Weiyu Xie, Mingxing Zhang, Boxing Zhang, Jianwei Dong, Yuening Zhu, Chen Lin, Jinqi Tang, Yaochen Han, Zhiyuan Ai, Xianglin Chen, Yongwei Wu, Congfeng Jiang
分类: cs.CL, cs.AI
发布日期: 2026-01-19
DOI: 10.1145/3786655
💡 一句话要点
提出FusionRAG,通过融合检索增强生成中的上下文信息加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG KV缓存 LLM推理加速 上下文融合 首个token生成时间 大语言模型 知识检索
📋 核心要点
- 现有RAG方法在重用KV缓存时,因缺乏跨文本块的上下文信息,导致生成质量显著下降。
- FusionRAG通过在预处理阶段嵌入相关文本块信息,并在后处理阶段重新计算关键token的KV缓存,实现质量与效率的平衡。
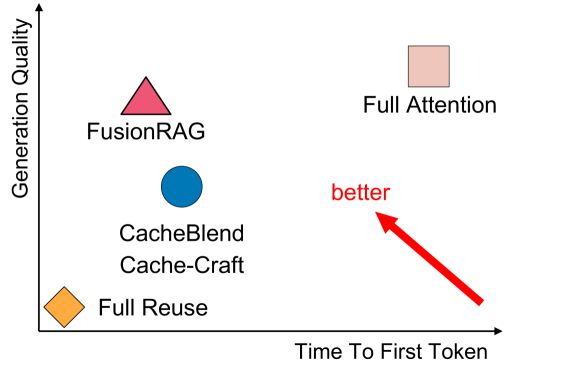
- 实验表明,FusionRAG在重计算少量token的情况下,显著提升了生成质量,并大幅降低了首个token生成时间。
📝 摘要(中文)
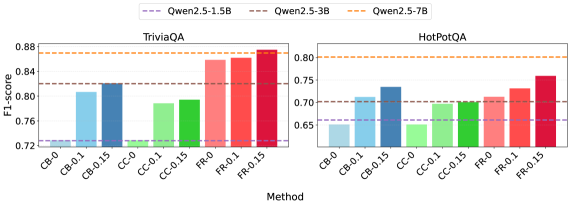
检索增强生成(RAG)通过整合外部知识来增强大型语言模型(LLM),虽然减少了幻觉,但也增加了prompt长度。这导致更高的计算成本和更长的首个token生成时间(TTFT)。为了缓解这个问题,现有的解决方案旨在重用每个检索到的文本块的预处理KV缓存来加速RAG。然而,由于缺乏跨文本块的上下文信息,导致生成质量显著下降,使得KV缓存重用的潜在好处未能充分实现。挑战在于如何在保持生成质量的同时重用文本块的预计算KV缓存。我们提出了FusionRAG,一种新颖的推理框架,优化了RAG的预处理和后处理阶段。在离线预处理阶段,我们将来自其他相关文本块的信息嵌入到每个文本块中,而在在线后处理阶段,我们重新计算模型关注的token的KV缓存。因此,我们在生成质量和效率之间实现了更好的权衡。实验表明,与先前的最先进解决方案相比,FusionRAG在相同的重计算率下显著提高了生成质量。通过重新计算少于15%的token,FusionRAG实现了比基线高出高达70%的标准化F1分数,并比完全注意力机制减少了2.66x-9.39x的TTFT。
🔬 方法详解
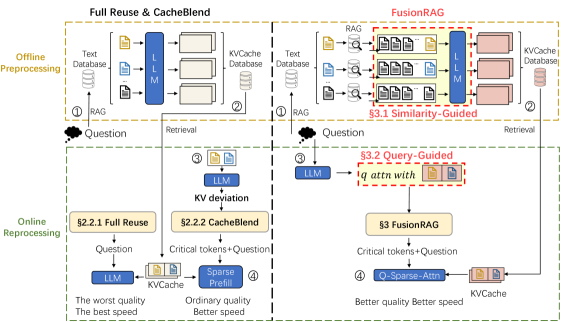
问题定义:论文旨在解决检索增强生成(RAG)中,由于prompt长度增加导致计算成本高昂和首个token生成时间(TTFT)过长的问题。现有方法尝试重用预计算的KV缓存,但由于缺乏跨文本块的上下文信息,导致生成质量显著下降,无法充分发挥KV缓存重用的优势。
核心思路:FusionRAG的核心思路是在保证生成质量的前提下,最大程度地重用预计算的KV缓存。通过在预处理阶段融合上下文信息,并在后处理阶段选择性地重新计算关键token的KV缓存,从而在生成质量和计算效率之间取得平衡。
技术框架:FusionRAG包含离线预处理和在线后处理两个阶段。在离线预处理阶段,将相关文本块的信息嵌入到每个文本块中,生成融合上下文信息的文本块。在在线后处理阶段,根据模型对token的关注度,选择性地重新计算部分token的KV缓存。整体流程为:检索相关文本块 -> 融合上下文信息(预处理)-> LLM生成 -> 选择性KV缓存重计算(后处理)。
关键创新:FusionRAG的关键创新在于融合了上下文信息的KV缓存重用机制。与现有方法直接重用单个文本块的KV缓存不同,FusionRAG通过预处理阶段的上下文融合,使得重用的KV缓存包含了更丰富的上下文信息,从而提高了生成质量。同时,通过后处理阶段的选择性重计算,进一步提升了生成质量,并降低了计算成本。
关键设计:FusionRAG的关键设计包括:1) 上下文融合策略,具体如何将相关文本块的信息嵌入到目标文本块中,例如使用某种注意力机制或信息融合网络;2) 选择性重计算策略,如何判断哪些token是模型关注的,需要重新计算KV缓存,例如基于注意力权重或梯度信息;3) 重计算比例的控制,需要在生成质量和计算效率之间进行权衡,选择合适的重计算比例。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FusionRAG在相同的重计算率下,显著提高了生成质量。通过重新计算少于15%的token,FusionRAG实现了比基线高出高达70%的标准化F1分数,并比完全注意力机制减少了2.66x-9.39x的首个token生成时间(TTFT)。这些数据表明FusionRAG在效率和质量上都优于现有方法。
🎯 应用场景
FusionRAG可应用于各种需要利用外部知识增强LLM的场景,例如问答系统、文档摘要、知识图谱推理等。通过提高RAG的效率和生成质量,可以显著提升用户体验,并降低部署成本。该研究对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Retrieval-Augmented Generation enhances Large Language Models by integrating external knowledge, which reduces hallucinations but increases prompt length. This increase leads to higher computational costs and longer Time to First Token (TTFT). To mitigate this issue, existing solutions aim to reuse the preprocessed KV cache of each retrieved chunk to accelerate RAG. However, the lack of cross-chunk contextual information leads to a significant drop in generation quality, leaving the potential benefits of KV cache reuse largely unfulfilled. The challenge lies in how to reuse the precomputed KV cache of chunks while preserving generation quality. We propose FusionRAG, a novel inference framework that optimizes both the preprocessing and reprocessing stages of RAG. In the offline preprocessing stage, we embed information from other related text chunks into each chunk, while in the online reprocessing stage, we recompute the KV cache for tokens that the model focuses on. As a result, we achieve a better trade-off between generation quality and efficiency. According to our experiments, FusionRAG significantly improves generation quality at the same recomputation ratio compared to previous state-of-the-art solutions. By recomputing fewer than 15% of the tokens, FusionRAG achieves up to 70% higher normalized F1 scores than baselines and reduces TTFT by 2.66x-9.39x compared to Full Attention.