Race, Ethnicity and Their Implication on Bias in Large Language Models
作者: Shiyue Hu, Ruizhe Li, Yanjun Gao
分类: cs.CL, cs.LG
发布日期: 2026-01-19
备注: Work in process
💡 一句话要点
通过可解释性分析揭示大语言模型中种族和族裔偏见的内在机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见分析 可解释性 种族和族裔 神经元归因
📋 核心要点
- 现有研究主要关注LLM偏见的结果层面,缺乏对内部机制的深入理解,难以有效缓解。
- 论文提出一种可复现的可解释性流程,结合探测、神经元归因和干预,分析种族和族裔信息在LLM中的表示。
- 实验发现人口统计信息分布广泛且模型间差异大,抑制特定神经元可减少偏见,但存在残余效应。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于医疗等高风险场景,在这些场景中,种族和族裔等人口属性可能会被明确声明或从文本中隐式推断出来。然而,现有的研究主要记录了结果层面的差异,对这些影响背后的内部机制的洞察有限。本文对LLMs中种族和族裔的表示和运作方式进行了机制性研究。使用两个公开可用的数据集,涵盖毒性相关的生成和临床叙事理解任务,分析了三个开源模型,并结合了探测、神经元级别的归因和有针对性的干预,构建了一个可复现的可解释性流程。研究发现,人口统计信息分布在内部单元中,且模型间的差异很大。尽管一些单元编码了来自预训练的敏感或刻板印象相关的关联,但相同的人口统计线索可以诱导出性质上不同的行为。抑制这些神经元的干预减少了偏见,但留下了大量的残余效应,表明是行为而非表征的改变,并促使进行更系统的缓解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中种族和族裔偏见内在机制不明确的问题。现有方法主要关注输出结果的偏差,缺乏对模型内部如何表示和处理这些敏感属性的深入理解,因此难以提出有效的缓解策略。这种理解的缺失阻碍了LLMs在医疗等高风险场景中的可靠应用。
核心思路:论文的核心思路是通过可解释性方法,深入剖析LLMs内部神经元的激活模式,从而揭示种族和族裔信息是如何被编码和使用的。通过识别与偏见相关的神经元,并对其进行干预,来评估这些神经元在偏见行为中的作用。这种方法侧重于理解偏见的根源,而非仅仅纠正输出结果。
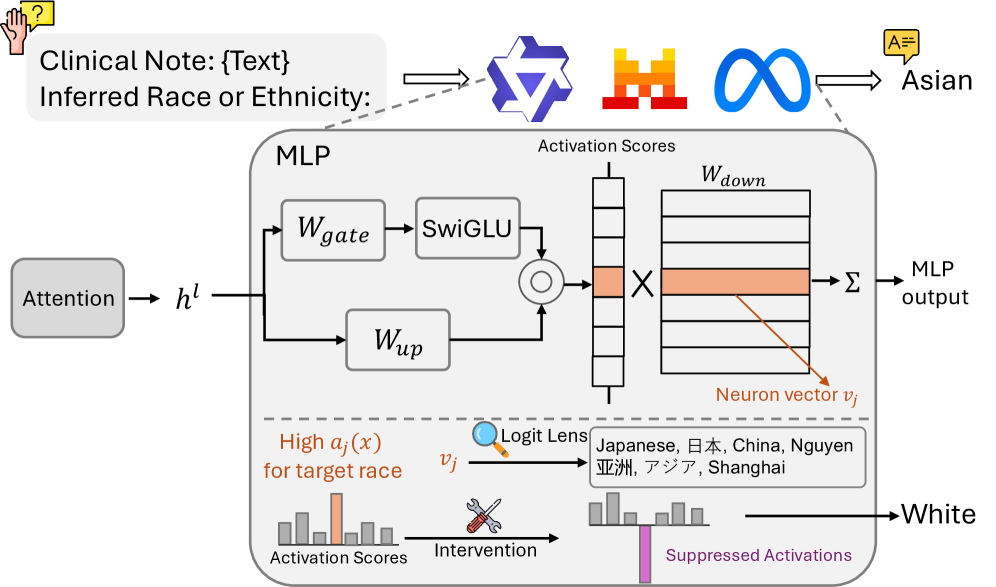
技术框架:论文采用一个包含三个主要阶段的可解释性流程:1) 探测 (Probing):训练分类器来预测LLM内部神经元的激活是否与特定种族或族裔相关。2) 神经元级别归因 (Neuron-level Attribution):使用归因方法识别对特定输出影响最大的神经元。3) 有针对性的干预 (Targeted Intervention):通过抑制或修改特定神经元的激活,观察对模型行为的影响。该流程应用于三个开源LLM,并使用两个公开数据集,分别涉及毒性生成和临床叙事理解任务。
关键创新:论文的关键创新在于其机制性的研究方法,它超越了对LLM偏见现象的简单观察,深入到模型内部的神经元层面进行分析。通过结合探测、归因和干预,论文能够识别与种族和族裔相关的特定神经元,并评估它们在偏见行为中的作用。这种方法为理解和缓解LLM偏见提供了新的视角。
关键设计:论文的关键设计包括:1) 使用线性探测来识别编码种族和族裔信息的神经元。2) 使用神经元级别的归因方法(具体方法未知)来确定对特定输出影响最大的神经元。3) 通过抑制(将激活设置为零)或修改(具体修改方式未知)这些神经元的激活来进行干预。论文还特别关注了不同模型之间以及同一模型在不同任务上的差异,以评估种族和族裔信息表示的鲁棒性。
🖼️ 关键图片
📊 实验亮点
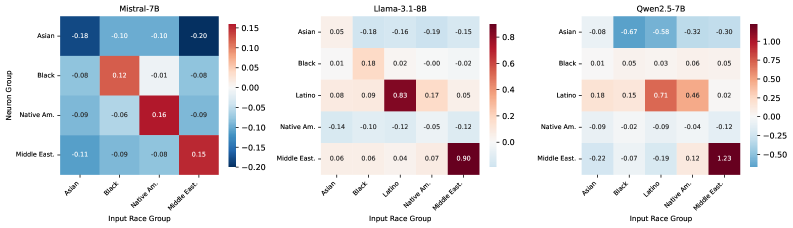
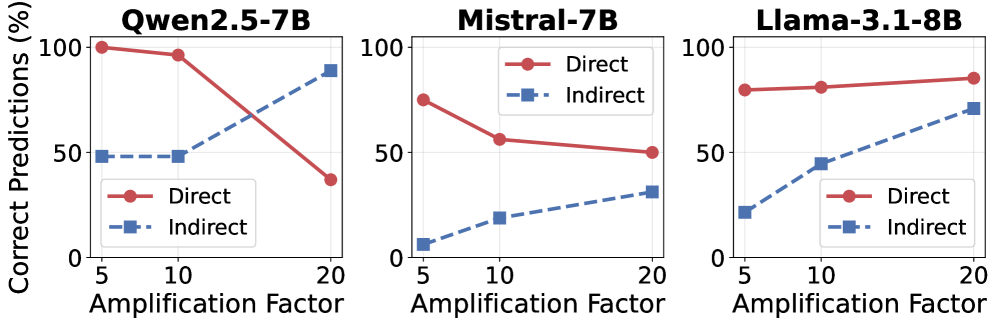
实验结果表明,种族和族裔信息在LLM内部的表示是分散的,并且模型之间存在显著差异。尽管一些神经元编码了刻板印象相关的关联,但相同的人口统计线索可以诱导出不同的行为。通过抑制这些神经元可以减少偏见,但仍存在残余效应,表明偏见的缓解更多是行为上的改变,而非表征上的改变。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于开发更公平、更可靠的LLM,尤其是在医疗、法律等涉及敏感人口属性的高风险领域。通过理解和缓解LLM中的偏见,可以避免歧视性或不准确的决策,提升LLM在实际应用中的公平性和可信度。未来的研究可以进一步探索更有效的偏见缓解策略,并将其应用于更广泛的LLM和任务。
📄 摘要(原文)
Large language models (LLMs) increasingly operate in high-stakes settings including healthcare and medicine, where demographic attributes such as race and ethnicity may be explicitly stated or implicitly inferred from text. However, existing studies primarily document outcome-level disparities, offering limited insight into internal mechanisms underlying these effects. We present a mechanistic study of how race and ethnicity are represented and operationalized within LLMs. Using two publicly available datasets spanning toxicity-related generation and clinical narrative understanding tasks, we analyze three open-source models with a reproducible interpretability pipeline combining probing, neuron-level attribution, and targeted intervention. We find that demographic information is distributed across internal units with substantial cross-model variation. Although some units encode sensitive or stereotype-related associations from pretraining, identical demographic cues can induce qualitatively different behaviors. Interventions suppressing such neurons reduce bias but leave substantial residual effects, suggesting behavioral rather than representational change and motivating more systematic mitigation.