Who Does This Name Remind You of? Nationality Prediction via Large Language Model Associative Memory
作者: Keito Inoshita
分类: cs.CL
发布日期: 2026-01-19
💡 一句话要点
提出LAMA:利用大语言模型联想记忆进行国籍预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 联想记忆 国籍预测 多代理系统 知识检索
📋 核心要点
- 现有LLM国籍预测方法依赖直接推理,难以有效利用其蕴含的文化历史知识。
- LAMA框架将LLM视为联想记忆,通过回忆同名人物的国籍进行间接推理。
- LAMA在99国国籍预测任务中达到0.817准确率,显著优于传统方法。
📝 摘要(中文)
大型语言模型(LLM)蕴含着丰富的世界知识,然而有效提取这些知识的方法仍有待探索。国籍和地区预测任务不仅需要理解语言特征,还需要文化和历史背景,这使得LLM的世界知识尤为重要。传统的LLM提示方法依赖于直接推理,在应用抽象语言规则方面存在局限性。我们提出了LLM联想记忆代理(LAMA),这是一个利用LLM世界知识作为联想记忆的新框架。LAMA不是直接从名字推断国籍,而是回忆具有相同名字的著名人物,并通过间接推理聚合他们的国籍。一个由Person Agent和Media Agent组成的双代理架构,分别专注于不同的知识领域,并行地回忆著名人物,通过投票生成Top-1预测,通过条件补全生成Top-K预测。在99个国家的国籍预测任务中,LAMA实现了0.817的准确率,显著优于传统的LLM提示方法和神经模型。实验表明,LLM在回忆具体例子方面比在抽象推理方面表现出更高的可靠性,基于回忆的方法对低频国籍具有鲁棒性,不受数据频率分布的影响,并且双代理架构能够互补地产生协同效应。这些结果证明了一种新的多代理系统的有效性,该系统检索和聚合LLM知识,而不是提示推理。
🔬 方法详解
问题定义:论文旨在解决国籍预测问题,即给定一个名字,预测其所属国籍。现有方法,特别是基于直接推理的LLM提示方法,在处理需要文化和历史背景知识的任务时表现不佳,因为它们难以有效利用LLM中蕴含的丰富世界知识。这些方法依赖于抽象的语言规则,而忽略了具体实例的联想。
核心思路:论文的核心思路是将LLM视为一个联想记忆库,通过回忆与给定名字相关的著名人物及其国籍,间接推断该名字的国籍。这种方法避免了直接推理的局限性,充分利用了LLM在存储和检索具体实例方面的优势。通过聚合多个相关人物的国籍信息,可以更准确地预测目标名字的国籍。
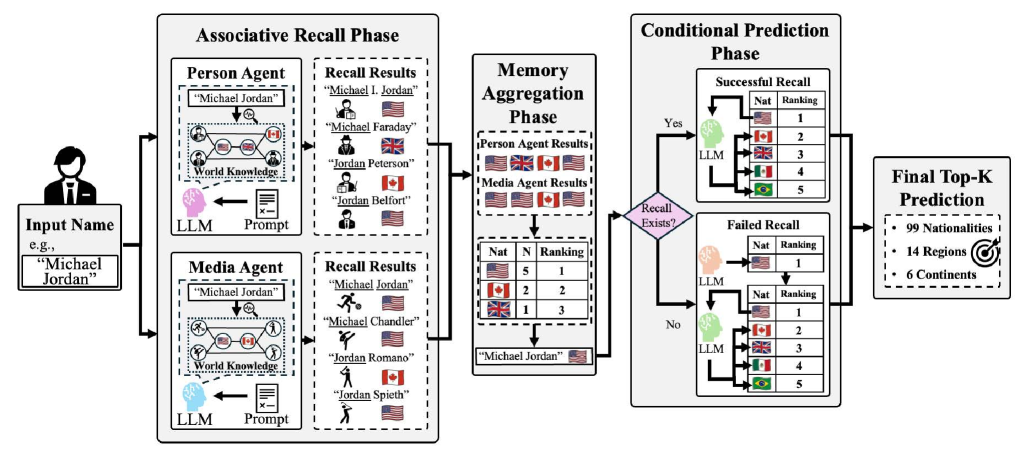
技术框架:LAMA框架采用双代理架构,包括Person Agent和Media Agent。Person Agent专注于回忆与名字相关的著名人物,而Media Agent则侧重于从媒体信息中提取相关人物。这两个代理并行工作,各自生成一组候选人物及其国籍。然后,通过投票机制(Top-1预测)或条件补全(Top-K预测)将两个代理的结果进行融合,得到最终的国籍预测结果。
关键创新:LAMA的关键创新在于将LLM的知识利用方式从直接推理转变为联想记忆检索。与传统的提示方法不同,LAMA不依赖于LLM的推理能力,而是利用其存储和检索具体实例的能力。此外,双代理架构的设计允许从不同角度(人物和媒体)检索相关信息,从而提高预测的准确性和鲁棒性。
关键设计:Person Agent和Media Agent的具体实现依赖于LLM的文本生成能力。通过精心设计的提示语,引导LLM回忆与给定名字相关的著名人物或媒体信息。投票机制采用简单的多数投票原则,选择出现频率最高的国籍作为Top-1预测结果。条件补全则利用LLM的文本补全能力,根据已有的候选人物及其国籍信息,生成更完整的国籍预测列表。
🖼️ 关键图片
📊 实验亮点
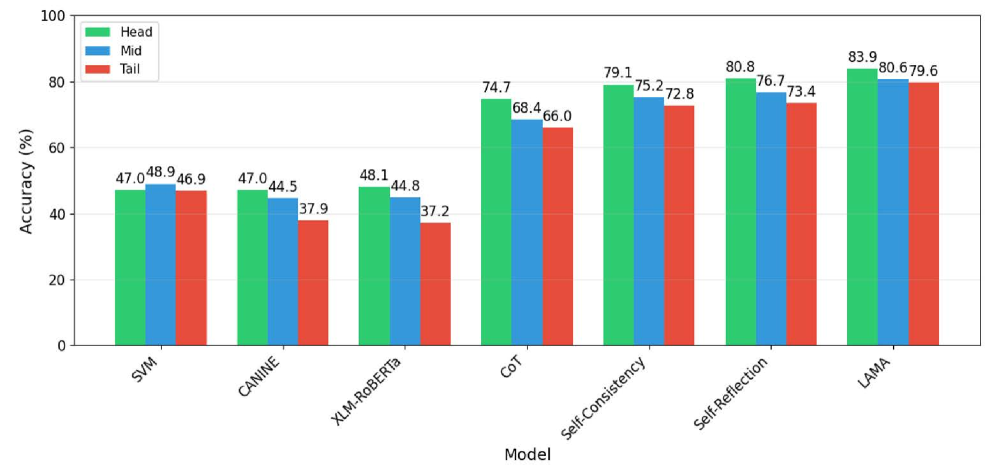
LAMA在99个国家的国籍预测任务中取得了0.817的准确率,显著优于传统的LLM提示方法和神经模型。实验结果表明,LLM在回忆具体例子方面比在抽象推理方面表现出更高的可靠性。此外,LAMA对低频国籍具有鲁棒性,不受数据频率分布的影响。双代理架构能够互补地产生协同效应,进一步提高了预测的准确性。
🎯 应用场景
该研究成果可应用于人名识别、国际关系分析、文化背景理解等领域。例如,在社交媒体分析中,可以利用该方法识别用户的国籍,从而进行更精准的用户画像和内容推荐。此外,该方法还可以用于辅助历史研究,例如通过分析历史人物的名字来推断其所属地区和文化背景。未来,该方法可以扩展到其他需要世界知识的任务中,例如事件预测和知识图谱构建。
📄 摘要(原文)
Large language models (LLMs) possess extensive world knowledge, yet methods for effectively eliciting this knowledge remain underexplored. Nationality and region prediction tasks require understanding of not only linguistic features but also cultural and historical background, making LLM world knowledge particularly valuable. However, conventional LLM prompting methods rely on direct reasoning approaches, which have limitations in applying abstract linguistic rules. We propose LLM Associative Memory Agents (LAMA), a novel framework that leverages LLM world knowledge as associative memory. Rather than directly inferring nationality from names, LAMA recalls famous individuals with the same name and aggregates their nationalities through indirect reasoning. A dual-agent architecture comprising a Person Agent and a Media Agent, specialized in different knowledge domains, recalls famous individuals in parallel, generating Top-1 predictions through voting and Top-K predictions through conditional completion. On a 99-country nationality prediction task, LAMA achieved 0.817 accuracy, substantially outperforming conventional LLM prompting methods and neural models. Our experiments reveal that LLMs exhibit higher reliability in recalling concrete examples than in abstract reasoning, that recall-based approaches are robust to low-frequency nationalities independent of data frequency distributions, and that the dual-agent architecture functions complementarily to produce synergistic effects. These results demonstrate the effectiveness of a new multi-agent system that retrieves and aggregates LLM knowledge rather than prompting reasoning.