VISPA: Pluralistic Alignment via Automatic Value Selection and Activation
作者: Shenyan Zheng, Jiayou Zhong, Anudeex Shetty, Heng Ji, Preslav Nakov, Usman Naseem
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-19
备注: WIP
💡 一句话要点
VISPA:通过自动价值选择和激活实现大语言模型的多元化对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多元化对齐 价值观控制 内部激活机制 无训练方法
📋 核心要点
- 现有大语言模型难以反映不同人群的价值观,倾向于输出“平均”偏好,缺乏对多元价值观的有效控制和表达。
- VISPA框架通过动态选择和激活模型内部机制,实现了对大语言模型价值观表达的直接控制,无需额外的训练。
- 实验结果表明,VISPA在医疗等多个领域表现出色,且能适应不同的模型和价值观,具有良好的可扩展性。
📝 摘要(中文)
随着大型语言模型越来越多地应用于高风险领域,至关重要的是,它们的输出应反映不同视角的范围,而不是“平均”人类偏好。然而,实现这种多元化仍然具有挑战性。现有的方法考虑的价值观有限,或者依赖于提示级别的干预,缺乏价值控制和表示。为了解决这个问题,我们引入了VISPA,这是一个无需训练的多元化对齐框架,它通过动态选择和内部模型激活引导,能够直接控制价值表达。通过跨多个模型和评估设置的广泛实证研究,我们表明VISPA在医疗保健及其他领域的各种多元化对齐模式中都表现出色。进一步的分析表明,VISPA可以适应不同的引导启动、模型和/或价值观。这些结果表明,多元化对齐可以通过内部激活机制来实现,为服务于所有人的语言模型提供了一条可扩展的路径。
🔬 方法详解
问题定义:现有的大语言模型在应用于高风险领域时,其输出往往未能充分考虑不同人群的价值观,而是倾向于反映一种“平均”的偏好。这种现象可能导致模型在处理涉及伦理、道德或文化差异的问题时,产生偏差或不公正的结果。现有的方法要么只考虑有限的价值观,要么依赖于提示工程等外部干预手段,缺乏对模型内部价值观表达的有效控制和表示。
核心思路:VISPA的核心思路是通过动态地选择和激活模型内部的特定神经元或激活模式,来引导模型表达特定的价值观。这种方法避免了对模型进行重新训练或微调的需求,而是直接利用模型已有的知识和能力,通过内部机制来实现价值观的对齐。其设计理念在于,大语言模型内部已经蕴含了各种价值观的潜在表达能力,只需要找到合适的方式来激活这些能力即可。
技术框架:VISPA框架主要包含两个阶段:价值选择阶段和激活引导阶段。在价值选择阶段,框架会根据用户的需求,选择一组与目标价值观相关的词汇或概念。在激活引导阶段,框架会利用这些词汇或概念,通过某种方式来影响模型内部的激活状态,从而引导模型生成符合目标价值观的文本。具体的流程是,首先确定需要表达的价值观,然后找到与该价值观相关的“价值激活词”,最后利用这些词汇来引导模型的生成过程。
关键创新:VISPA最重要的创新点在于它提出了一种无需训练的多元化对齐方法,通过内部激活机制来实现对模型价值观表达的直接控制。与现有的方法相比,VISPA不需要对模型进行重新训练或微调,具有更高的效率和灵活性。此外,VISPA还能够适应不同的模型和价值观,具有良好的可扩展性。这种内部激活机制的探索,为实现更公平、更负责任的大语言模型提供了一种新的思路。
关键设计:VISPA的关键设计包括价值激活词的选择策略和激活引导的具体方法。价值激活词的选择需要保证其与目标价值观具有高度的相关性,可以通过人工标注或自动挖掘的方式来获取。激活引导的具体方法可以采用多种形式,例如,可以通过修改模型的输入或隐藏层的激活值,来影响模型的生成过程。论文中可能使用了特定的损失函数来鼓励模型生成符合目标价值观的文本,或者采用了特定的网络结构来增强模型对价值观的感知能力。(具体细节未知,需查阅论文)
🖼️ 关键图片


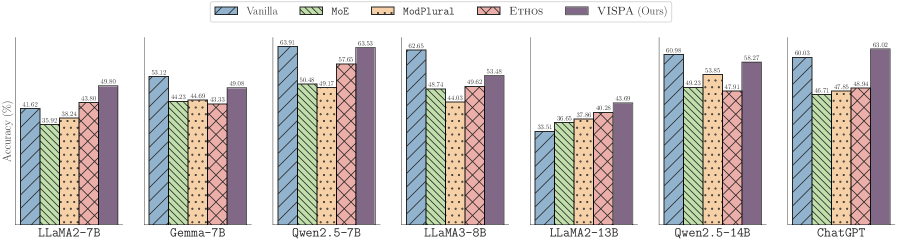
📊 实验亮点
VISPA在多个模型和评估设置下进行了广泛的实验,结果表明其在医疗保健等领域的各种多元化对齐模式中都表现出色。实验结果还表明,VISPA可以适应不同的引导启动、模型和/或价值观,具有良好的可扩展性。具体的性能数据和提升幅度需要在论文中查找,但总体而言,VISPA展示了其在多元化对齐方面的有效性和通用性。
🎯 应用场景
VISPA框架具有广泛的应用前景,尤其是在医疗、法律、教育等高风险领域。它可以帮助大语言模型在生成文本时,充分考虑不同人群的价值观,避免产生偏差或不公正的结果。例如,在医疗领域,VISPA可以用于生成更符合患者价值观的诊断建议;在法律领域,可以用于生成更公正的判决书;在教育领域,可以用于生成更具包容性的教材。此外,VISPA还可以用于个性化推荐、情感分析等领域,提高模型的实用性和用户满意度。
📄 摘要(原文)
As large language models are increasingly used in high-stakes domains, it is essential that their outputs reflect not average} human preference, rather range of varying perspectives. Achieving such pluralism, however, remains challenging. Existing approaches consider limited values or rely on prompt-level interventions, lacking value control and representation. To address this, we introduce VISPA, a training-free pluralistic alignment framework, that enables direct control over value expression by dynamic selection and internal model activation steering. Across extensive empirical studies spanning multiple models and evaluation settings, we show VISPA is performant across all pluralistic alignment modes in healthcare and beyond. Further analysis reveals VISPA is adaptable with different steering initiations, model, and/or values. These results suggest that pluralistic alignment can be achieved through internal activation mechanisms, offering a scalable path toward language models that serves all.