Towards Robust Process Reward Modeling via Noise-aware Learning
作者: Bin Xie, Bingbing Xu, Xueyun Tian, Yilin Chen, Huawei Shen
分类: cs.CL
发布日期: 2026-01-19
💡 一句话要点
提出噪声感知学习框架,提升过程奖励模型在复杂推理中的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 噪声感知学习 大型语言模型 标签校正 迭代训练
📋 核心要点
- 现有过程奖励模型依赖昂贵的过程级监督,而蒙特卡洛估计引入了策略依赖的标签噪声。
- 论文提出两阶段框架,首先使用LLM进行反射感知标签校正,然后进行噪声感知迭代训练。
- 实验表明,该方法显著提高了步骤级正确性判别,平均F1值绝对提高了27%。
📝 摘要(中文)
过程奖励模型(PRMs)在复杂推理中取得了显著成果,但受到昂贵的过程级监督的限制。一种广泛使用的替代方法是蒙特卡洛估计(MCE),它将过程奖励定义为策略模型从给定推理步骤到达正确最终答案的概率。然而,步骤正确性是推理轨迹的内在属性,应该与策略选择无关。我们的经验结果表明,MCE产生依赖于策略的奖励,从而导致标签噪声,包括奖励不正确步骤的假阳性和惩罚正确步骤的假阴性。为了解决上述挑战,我们提出了一个两阶段框架来减轻噪声监督。在标注阶段,我们引入了一种反射感知标签校正机制,该机制使用大型语言模型(LLM)作为判断器来检测与当前推理步骤相关的反射和自我校正行为,从而抑制高估的奖励。在训练阶段,我们进一步提出了一个噪声感知迭代训练框架,使PRM能够根据自身置信度逐步细化噪声标签。大量实验表明,我们的方法显著提高了步骤级正确性判别,与使用噪声监督训练的PRM相比,平均F1值绝对提高了27%。
🔬 方法详解
问题定义:过程奖励模型(PRMs)在复杂推理任务中表现出色,但训练需要大量的过程级标注数据,成本高昂。蒙特卡洛估计(MCE)作为一种替代方案,通过评估策略模型从中间步骤到达正确答案的概率来生成奖励信号。然而,MCE生成的奖励信号会受到策略选择的影响,导致标签噪声,即错误地奖励了不正确的步骤(假阳性)或惩罚了正确的步骤(假阴性)。这种噪声会严重影响PRM的学习效果,降低其鲁棒性。
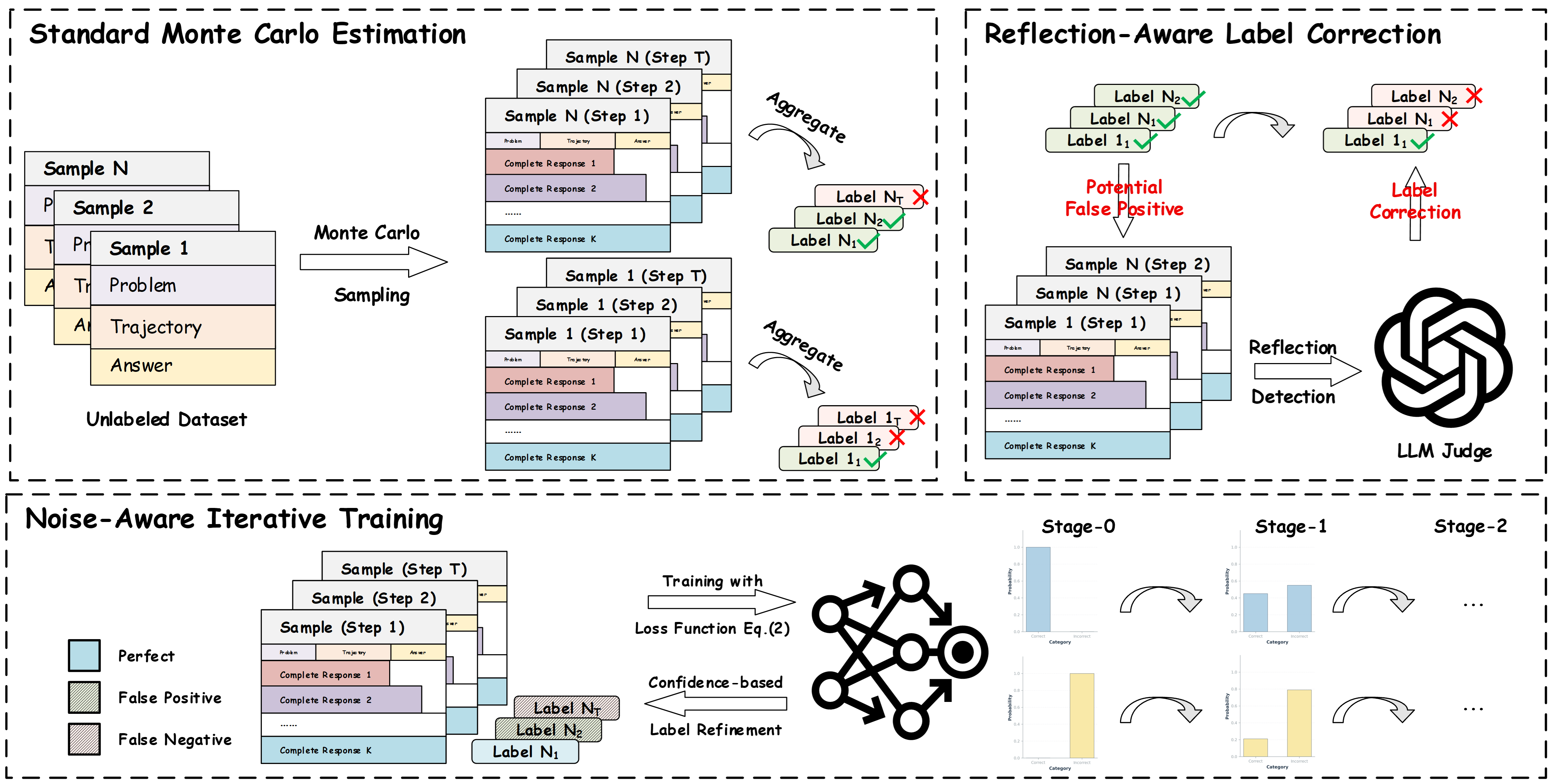
核心思路:论文的核心思路是通过两阶段的噪声抑制方法来提高过程奖励模型的鲁棒性。首先,在标注阶段,利用大型语言模型(LLM)的推理能力来识别和纠正MCE引入的标签噪声,特别是那些由于模型反射和自我纠正行为而产生的高估奖励。其次,在训练阶段,设计一个噪声感知迭代训练框架,让PRM能够根据自身对步骤正确性的置信度,逐步优化和修正标签,从而更好地学习真实的奖励信号。
技术框架:该方法包含两个主要阶段:标签校正阶段和噪声感知训练阶段。在标签校正阶段,首先使用MCE生成初始的奖励标签。然后,利用LLM作为裁判,判断当前推理步骤是否包含反射或自我纠正行为。如果检测到这些行为,则降低相应的奖励值,以抑制高估的奖励。在噪声感知训练阶段,采用迭代训练的方式。在每次迭代中,PRM首先根据当前的奖励标签进行训练,然后利用训练好的PRM对奖励标签进行重新评估和修正。这个过程不断重复,直到PRM的性能收敛。
关键创新:该论文的关键创新在于提出了一个结合LLM和噪声感知学习的框架,用于解决过程奖励模型中存在的标签噪声问题。具体来说,利用LLM的推理能力来检测和纠正由于模型反射和自我纠正行为而产生的标签噪声,这是一种新颖的噪声抑制方法。此外,提出的噪声感知迭代训练框架能够让PRM根据自身置信度逐步优化和修正标签,从而更好地学习真实的奖励信号。
关键设计:在标签校正阶段,LLM被用作一个二元分类器,判断当前推理步骤是否包含反射或自我纠正行为。具体的prompt设计和阈值设置会影响校正效果。在噪声感知训练阶段,可以使用各种噪声鲁棒的损失函数,例如Huber loss或Generalized Cross-Entropy loss,来降低噪声标签的影响。迭代训练的次数和学习率等超参数也需要仔细调整,以保证模型的收敛性和性能。
🖼️ 关键图片
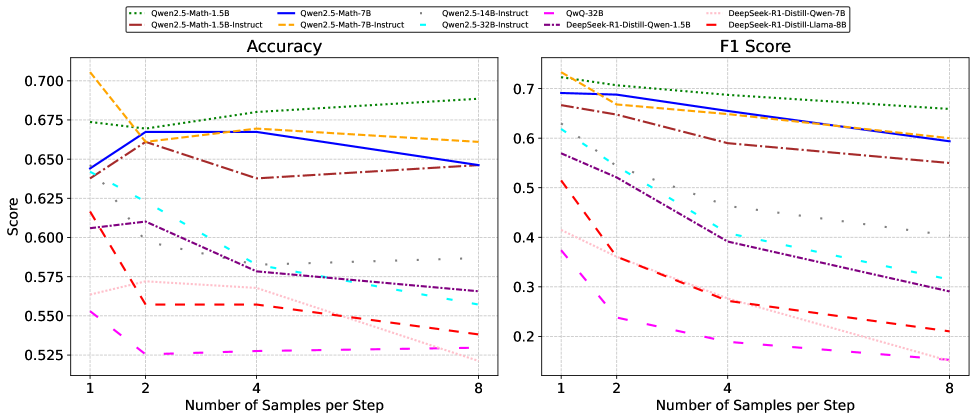

📊 实验亮点
实验结果表明,该方法在步骤级正确性判别方面取得了显著提升,与使用噪声监督训练的PRM相比,平均F1值绝对提高了27%。这表明该方法能够有效地抑制标签噪声,提高PRM的鲁棒性。此外,实验还验证了该方法在不同数据集和任务上的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要复杂推理和决策的任务中,例如问答系统、代码生成、机器人导航等。通过提高过程奖励模型的鲁棒性,可以使其在噪声环境下更好地学习和执行任务,从而提高系统的整体性能和可靠性。未来,该方法可以进一步扩展到其他类型的奖励模型和监督信号,例如人类反馈和专家演示。
📄 摘要(原文)
Process Reward Models (PRMs) have achieved strong results in complex reasoning, but are bottlenecked by costly process-level supervision. A widely used alternative, Monte Carlo Estimation (MCE), defines process rewards as the probability that a policy model reaches the correct final answer from a given reasoning step. However, step correctness is an intrinsic property of the reasoning trajectory, and should be invariant to policy choice. Our empirical findings show that MCE producing policy-dependent rewards that induce label noise, including false positives that reward incorrect steps and false negatives that penalize correct ones. To address above challenges, we propose a two-stage framework to mitigate noisy supervision. In the labeling stage, we introduce a reflection-aware label correction mechanism that uses a large language model (LLM) as a judge to detect reflection and self-correction behaviors related to the current reasoning step, thereby suppressing overestimated rewards. In the training stage, we further propose a \underline{\textbf{N}}oise-\underline{\textbf{A}}ware \underline{\textbf{I}}terative \underline{\textbf{T}}raining framework that enables the PRM to progressively refine noisy labels based on its own confidence. Extensive Experiments show that our method substantially improves step-level correctness discrimination, achieving up to a 27\% absolute gain in average F1 over PRMs trained with noisy supervision.