A Shared Geometry of Difficulty in Multilingual Language Models
作者: Stefano Civelli, Pietro Bernardelle, Nicolò Brunello, Gianluca Demartini
分类: cs.CL, cs.AI
发布日期: 2026-01-19
💡 一句话要点
揭示多语言模型中难度几何:浅层泛化,深层特化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 问题难度 线性探针 跨语言泛化 模型可解释性
📋 核心要点
- 现有方法难以理解LLM如何跨语言处理问题难度,缺乏对模型内部表示的深入分析。
- 本文提出通过训练线性探针,研究LLM在不同层级对问题难度的表示,揭示其多语言几何结构。
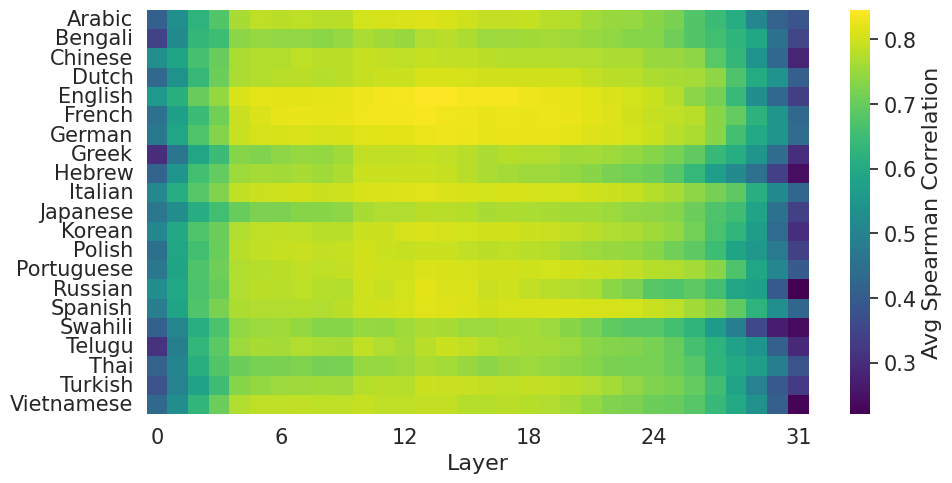
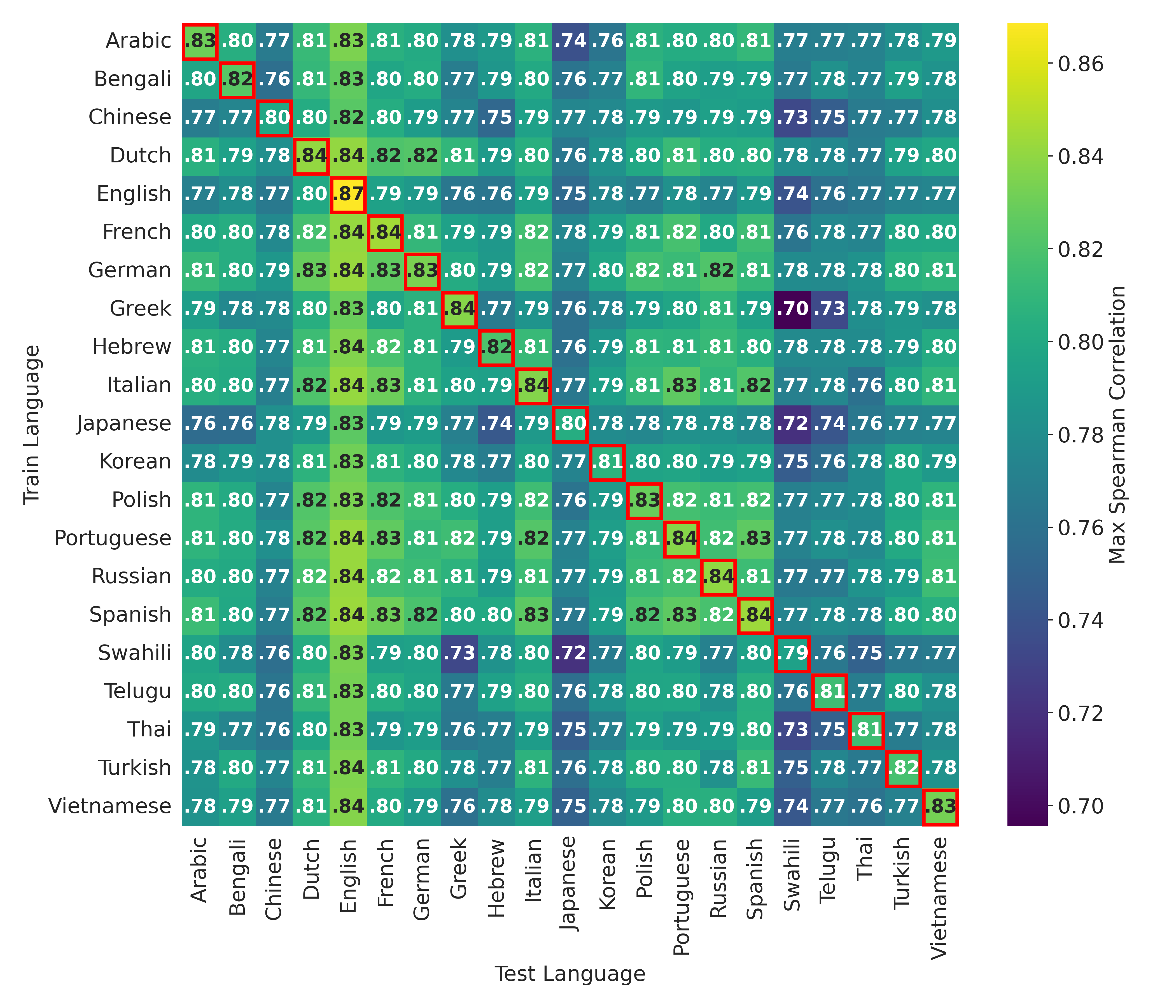
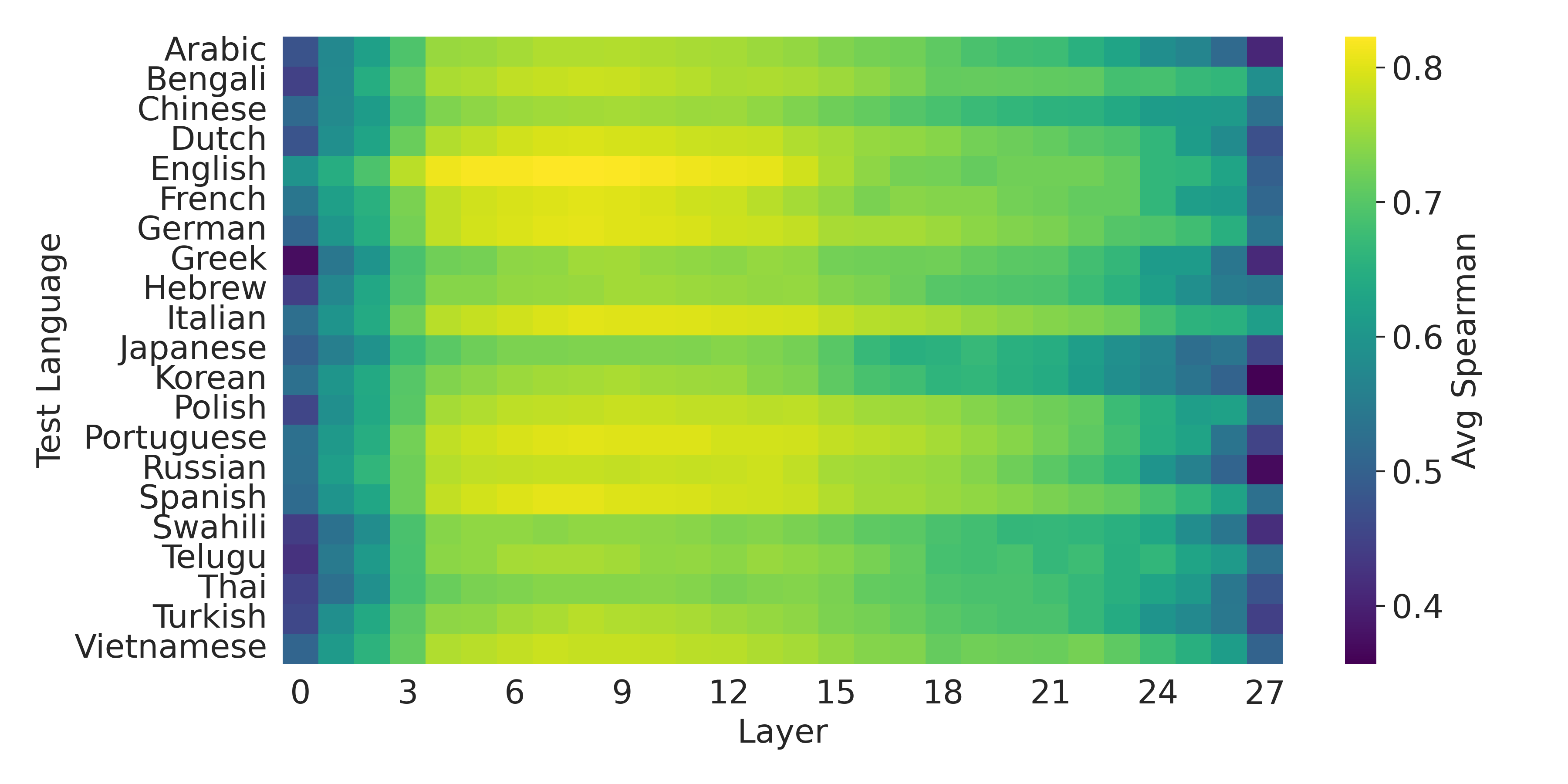
- 实验表明,浅层表示具有更好的跨语言泛化能力,而深层表示在特定语言上表现更佳,揭示了难度表示的两阶段过程。
📝 摘要(中文)
本文研究了大型语言模型(LLM)中问题难度的多语言几何结构。通过在Easy2Hard基准测试的AMC子集上训练线性探针,并将该子集翻译成21种语言,我们发现与难度相关的信号出现在模型内部的两个不同阶段:浅层(早期层)和深层(后期层)内部表示,它们表现出功能不同的行为。在同一种语言上评估时,在深层表示上训练的探针实现了高精度,但跨语言泛化能力较差。相比之下,在浅层表示上训练的探针在跨语言方面表现出更好的泛化能力,尽管在语言内部的性能较低。这些结果表明,LLM首先形成问题难度的语言无关表示,然后逐渐变得特定于语言。这与LLM可解释性方面的现有发现非常吻合,即模型倾向于在生成特定于语言的输出之前,在抽象的概念空间中运行。我们证明了这种两阶段表示过程超越了语义内容,扩展到诸如问题难度估计之类的高级元认知属性。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)如何处理不同语言的问题难度。现有的方法通常关注模型在特定语言上的表现,而忽略了跨语言的难度表示。因此,如何理解LLM内部跨语言的难度表示,以及模型在哪些层级处理语言无关和语言相关的难度信息,是本文要解决的关键问题。
核心思路:论文的核心思路是通过训练线性探针来分析LLM内部不同层级的表示。线性探针是一种简单但有效的工具,可以用来解码模型内部的隐藏状态,从而了解模型在不同层级学习到的信息。通过在不同语言的数据上训练探针,并评估其跨语言的泛化能力,可以揭示模型如何跨语言表示问题难度。
技术框架:整体框架包括以下几个主要步骤:1) 数据准备:将Easy2Hard基准测试的AMC子集翻译成21种语言。2) 模型选择:选择一个预训练的LLM作为研究对象。3) 探针训练:在LLM的不同层级上训练线性探针,以预测问题难度。4) 评估:评估探针在同一种语言和不同语言上的性能,分析其泛化能力。
关键创新:论文的关键创新在于发现了LLM中问题难度表示的两阶段过程:浅层表示具有更好的跨语言泛化能力,而深层表示在特定语言上表现更佳。这表明LLM首先形成一个语言无关的难度表示,然后在更深的层级将其转化为语言相关的表示。
关键设计:论文的关键设计包括:1) 使用Easy2Hard基准测试的AMC子集,该数据集包含不同难度的问题。2) 将数据集翻译成21种语言,以研究跨语言的难度表示。3) 在LLM的不同层级上训练线性探针,以分析不同层级的表示。4) 使用准确率作为评估指标,衡量探针的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在深层表示上训练的探针在同一种语言上实现了高精度,但在跨语言泛化方面表现较差。相反,在浅层表示上训练的探针在跨语言方面表现出更好的泛化能力,尽管在语言内部的性能较低。这表明LLM首先形成问题难度的语言无关表示,然后逐渐变得特定于语言。
🎯 应用场景
该研究成果可应用于提升多语言LLM的鲁棒性和泛化能力,例如,通过优化模型结构或训练策略,使其更好地学习语言无关的难度表示。此外,该研究也有助于理解LLM的内部工作机制,为模型可解释性研究提供新的视角。
📄 摘要(原文)
Predicting problem-difficulty in large language models (LLMs) refers to estimating how difficult a task is according to the model itself, typically by training linear probes on its internal representations. In this work, we study the multilingual geometry of problem-difficulty in LLMs by training linear probes using the AMC subset of the Easy2Hard benchmark, translated into 21 languages. We found that difficulty-related signals emerge at two distinct stages of the model internals, corresponding to shallow (early-layers) and deep (later-layers) internal representations, that exhibit functionally different behaviors. Probes trained on deep representations achieve high accuracy when evaluated on the same language but exhibit poor cross-lingual generalization. In contrast, probes trained on shallow representations generalize substantially better across languages, despite achieving lower within-language performance. Together, these results suggest that LLMs first form a language-agnostic representation of problem difficulty, which subsequently becomes language-specific. This closely aligns with existing findings in LLM interpretability showing that models tend to operate in an abstract conceptual space before producing language-specific outputs. We demonstrate that this two-stage representational process extends beyond semantic content to high-level meta-cognitive properties such as problem-difficulty estimation.