Evaluating LLM Behavior in Hiring: Implicit Weights, Fairness Across Groups, and Alignment with Human Preferences
作者: Morgane Hoffmann, Emma Jouffroy, Warren Jouanneau, Marc Palyart, Charles Pebereau
分类: cs.CL, cs.AI, cs.CY, cs.SI
发布日期: 2026-01-16
💡 一句话要点
评估LLM在招聘中的行为:隐式权重、群体公平性及与人类偏好的一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 招聘 公平性 隐式权重 决策逻辑
📋 核心要点
- 现有招聘方法难以有效处理非结构化文本,且难以平衡多个招聘标准,对候选人能力评估不够全面。
- 该论文提出一个评估框架,通过分析LLM在招聘中的决策逻辑,揭示其对不同属性的隐式权重分配。
- 实验结果表明,LLM重视技能和经验等生产力信号,但不同人口群体间,生产力信号的权重存在差异。
📝 摘要(中文)
通用大型语言模型(LLM)在招聘领域展现出巨大潜力,尤其是在需要对非结构化文本进行推理、平衡多个标准以及从间接生产力信号中推断匹配度和能力的情况下。然而,LLM如何分配每个属性的重要性,以及这种分配是否符合经济原则、招聘人员偏好或更广泛的社会规范,仍然不确定。本文提出一个框架,通过借鉴成熟的经济学方法来分析人类招聘行为,从而评估LLM在招聘中的决策逻辑。我们从欧洲主要在线自由职业者市场上的真实自由职业者资料和项目描述中构建合成数据集,并应用全因子设计来估计LLM在评估自由职业者与项目匹配度时如何权衡不同的匹配相关标准。我们识别出LLM优先考虑的属性,并分析这些权重如何在项目背景和人口子群体之间变化。最后,我们解释了如何使用人类招聘人员实施类似的可比实验设置,以评估模型和人类决策之间的一致性。我们的研究结果表明,LLM权衡核心生产力信号,如技能和经验,但会解释某些超出其明确匹配价值的特征。虽然在平均水平上对少数群体表现出最小的歧视,但交叉效应表明,生产力信号在不同人口群体之间具有不同的权重。
🔬 方法详解
问题定义:论文旨在解决LLM在招聘场景中决策逻辑的透明性和公平性问题。现有方法缺乏对LLM如何权衡不同候选人属性的深入理解,以及LLM决策是否与人类招聘人员的偏好和社会规范相符。此外,现有方法难以评估LLM在不同人口群体中是否存在潜在的歧视。
核心思路:论文的核心思路是借鉴经济学中分析人类招聘行为的方法,构建一个评估LLM招聘决策逻辑的框架。通过构建合成数据集,并采用全因子设计,可以系统地分析LLM如何权衡不同的匹配相关标准,并识别其优先考虑的属性。通过对比LLM和人类招聘人员的决策,可以评估模型与人类偏好的一致性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 从真实的自由职业者平台收集数据,包括自由职业者资料和项目描述。2) 基于收集到的数据,构建合成数据集,并采用全因子设计,系统地改变不同候选人属性的取值。3) 使用LLM对合成数据集中的候选人进行评估,并记录LLM的决策结果。4) 使用统计方法分析LLM的决策结果,估计LLM对不同属性的隐式权重。5) 分析LLM的决策结果在不同人口群体中是否存在差异,评估LLM的公平性。6) 设计实验,让人类招聘人员对相同的候选人进行评估,并对比LLM和人类招聘人员的决策。
关键创新:该论文的关键创新在于:1) 提出了一个评估LLM在招聘中决策逻辑的框架,该框架借鉴了经济学中分析人类招聘行为的方法。2) 使用全因子设计,系统地分析了LLM如何权衡不同的匹配相关标准。3) 评估了LLM在不同人口群体中是否存在潜在的歧视。4) 对比了LLM和人类招聘人员的决策,评估了模型与人类偏好的一致性。
关键设计:论文的关键设计包括:1) 合成数据集的构建,需要保证数据集的真实性和多样性,同时需要控制不同属性之间的相关性。2) 全因子设计的选择,需要根据实际情况选择合适的因子和水平数,以保证实验结果的可靠性。3) 统计方法的选择,需要根据数据的特点选择合适的统计方法,以准确估计LLM对不同属性的隐式权重。4) 公平性指标的选择,需要选择合适的公平性指标,以全面评估LLM在不同人口群体中是否存在潜在的歧视。
🖼️ 关键图片
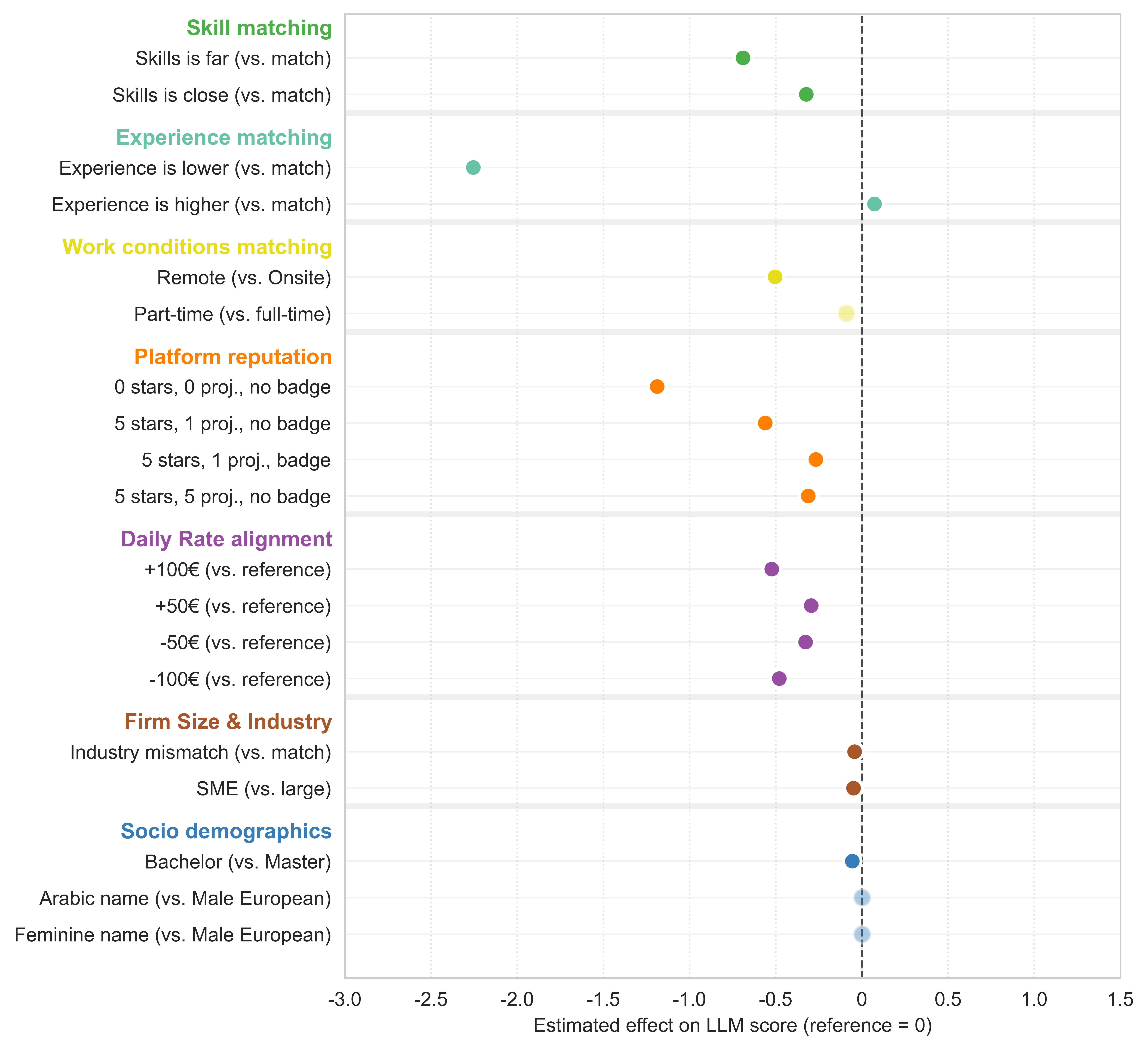
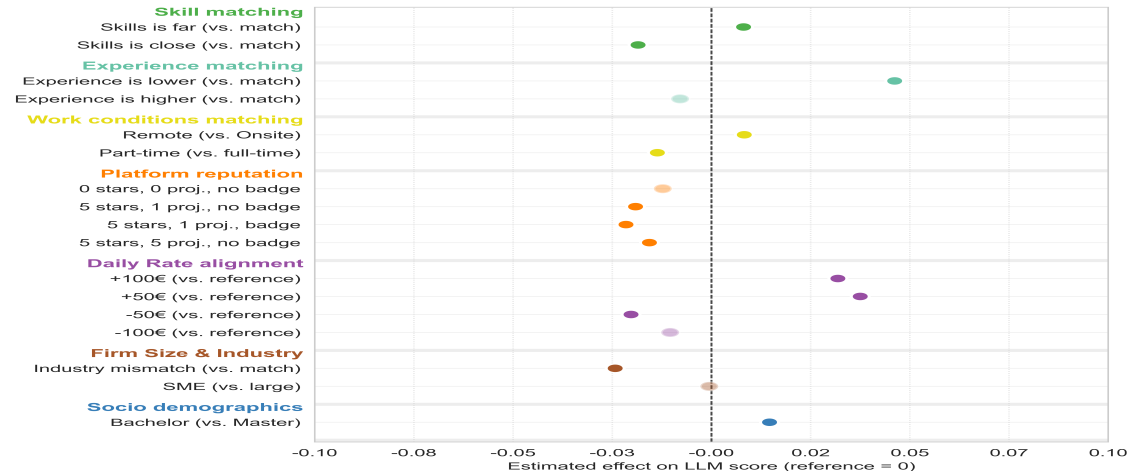

📊 实验亮点
实验结果表明,LLM在评估候选人时,会权衡技能和经验等核心生产力信号。然而,LLM也会解释某些超出其明确匹配价值的特征。虽然平均而言,LLM对少数群体表现出最小的歧视,但交叉效应表明,生产力信号在不同人口群体之间具有不同的权重。这些发现为优化LLM在招聘中的应用提供了重要的参考。
🎯 应用场景
该研究成果可应用于改进招聘流程,提高招聘效率和公平性。通过理解LLM的决策逻辑,可以优化LLM在招聘中的应用,减少潜在的偏见,并提高候选人与职位的匹配度。此外,该研究方法也可推广到其他需要评估AI决策逻辑的领域,如信贷评估、医疗诊断等。
📄 摘要(原文)
General-purpose Large Language Models (LLMs) show significant potential in recruitment applications, where decisions require reasoning over unstructured text, balancing multiple criteria, and inferring fit and competence from indirect productivity signals. Yet, it is still uncertain how LLMs assign importance to each attribute and whether such assignments are in line with economic principles, recruiter preferences or broader societal norms. We propose a framework to evaluate an LLM's decision logic in recruitment, by drawing on established economic methodologies for analyzing human hiring behavior. We build synthetic datasets from real freelancer profiles and project descriptions from a major European online freelance marketplace and apply a full factorial design to estimate how a LLM weighs different match-relevant criteria when evaluating freelancer-project fit. We identify which attributes the LLM prioritizes and analyze how these weights vary across project contexts and demographic subgroups. Finally, we explain how a comparable experimental setup could be implemented with human recruiters to assess alignment between model and human decisions. Our findings reveal that the LLM weighs core productivity signals, such as skills and experience, but interprets certain features beyond their explicit matching value. While showing minimal average discrimination against minority groups, intersectional effects reveal that productivity signals carry different weights between demographic groups.