Idea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming
作者: Sama Hadhoud, Alaa Elsetohy, Frederikus Hudi, Jan Christian Blaise Cruz, Steven Halim, Alham Fikri Aji
分类: cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出“先思路后代码”的评估框架,解耦LLM在编程竞赛中的问题解决与代码生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编程竞赛 问题解决 代码生成 算法推理 自然语言题解 评估框架
📋 核心要点
- 现有LLM在编程竞赛中的评估方法混淆了算法推理和代码实现,无法准确衡量模型的问题解决能力。
- 论文提出“先思路后代码”的评估框架,通过生成和评估自然语言题解,将问题解决与代码生成解耦。
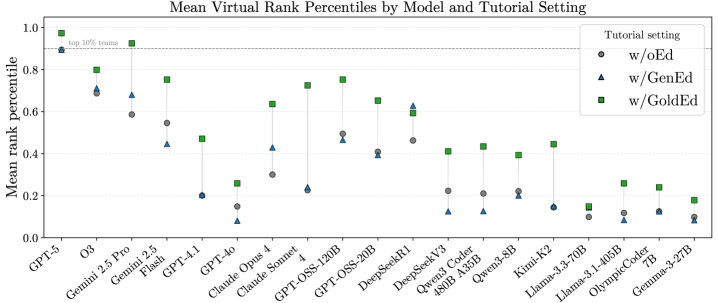
- 实验表明,使用标准题解能显著提升LLM的解题率,并揭示了模型在问题解决和代码实现上的瓶颈。
📝 摘要(中文)
大型语言模型(LLM)在编程竞赛问题上取得了越来越多的成功,但现有的评估方法将算法推理与代码级实现混为一谈。我们认为,编程竞赛本质上是一个问题解决任务,并建议在解决方案生成和评估中都以自然语言题解为中心。在编写代码之前生成题解可以提高某些LLM的解决率,尤其是在使用专家编写的标准题解时,提升效果更为显著。然而,即使有了标准题解,模型仍然难以实现代码,而生成题解与标准题解之间的差距揭示了在指定正确和完整算法时,仍然存在问题解决的瓶颈。除了通过/失败指标之外,我们还通过专家注释将模型生成的题解与黄金标准进行比较,从而诊断推理错误,并验证了一种用于可扩展评估的LLM-as-a-judge协议。我们引入了一个包含83个ICPC风格问题的数据集,其中包含标准题解和完整的测试套件,并评估了19个LLM,认为未来的基准测试应该明确区分问题解决和实现。
🔬 方法详解
问题定义:现有评估LLM在编程竞赛中的表现时,通常直接评估其代码的正确性,这无法区分模型是擅长算法推理还是代码实现。这种评估方式的痛点在于,即使模型生成的代码通过了测试,也无法确定模型是否真正理解了问题的本质,或者只是通过某种技巧绕过了问题。
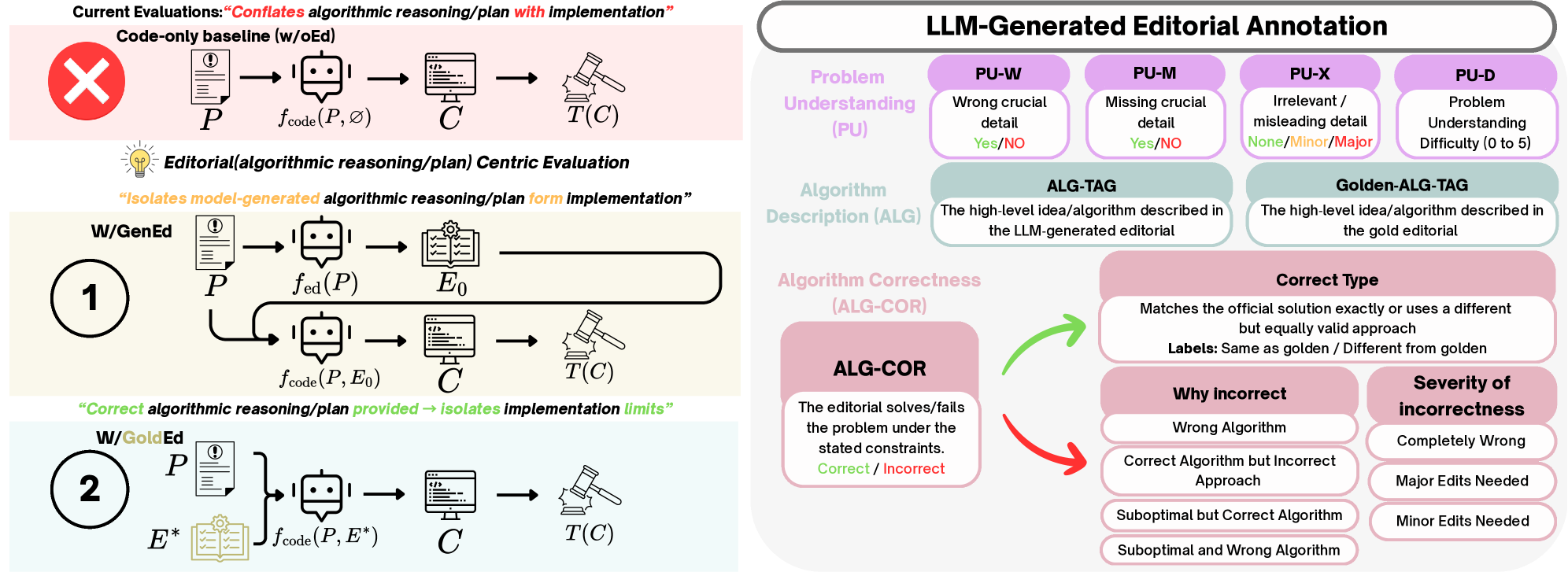
核心思路:论文的核心思路是将问题解决和代码实现两个阶段分离。首先,要求LLM生成自然语言的题解(editorial),描述解决问题的算法思路。然后,再根据题解生成代码。通过比较LLM生成的题解与专家编写的标准题解,可以更准确地评估LLM的问题解决能力。这种设计模仿了人类解决编程竞赛问题的过程,即先理解问题,设计算法,再编写代码。
技术框架:整体框架包含以下几个主要阶段:1. 问题输入:将ICPC风格的编程竞赛问题输入给LLM。2. 题解生成:要求LLM生成自然语言的题解,描述解决问题的算法思路。3. 代码生成:根据生成的题解,要求LLM生成代码。4. 题解评估:将LLM生成的题解与专家编写的标准题解进行比较,评估LLM的问题解决能力。5. 代码评估:运行生成的代码,评估代码的正确性。
关键创新:最重要的技术创新点在于将问题解决和代码实现两个阶段分离,并引入自然语言题解作为中间表示。这使得可以更准确地评估LLM的问题解决能力,而不仅仅是代码的正确性。与现有方法的本质区别在于,现有方法通常只关注代码的正确性,而忽略了模型是否真正理解了问题的本质。
关键设计:论文的关键设计包括:1. 数据集:构建了一个包含83个ICPC风格问题的数据集,其中包含标准题解和完整的测试套件。2. 评估指标:除了传统的通过/失败指标外,还引入了基于专家注释的题解比较指标,用于评估LLM的问题解决能力。3. LLM-as-a-judge协议:验证了一种使用LLM作为裁判的协议,用于可扩展地评估LLM生成的题解。
🖼️ 关键图片
📊 实验亮点
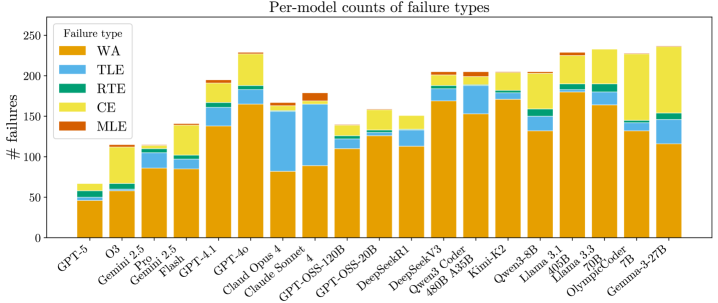
实验结果表明,在编写代码之前生成题解可以提高某些LLM的解决率,尤其是在使用专家编写的标准题解时,提升效果更为显著。即使有了标准题解,模型仍然难以实现代码,揭示了代码实现上的瓶颈。通过比较模型生成的题解与标准题解,可以诊断推理错误。
🎯 应用场景
该研究成果可应用于更准确地评估和提升LLM在编程、算法设计和问题解决等方面的能力。通过分离问题解决和代码实现,可以更好地诊断LLM的不足,并针对性地进行改进。此外,该研究提出的评估框架和数据集,可作为未来LLM编程能力评估的基准。
📄 摘要(原文)
Large Language Models (LLMs) increasingly succeed on competitive programming problems, yet existing evaluations conflate algorithmic reasoning with code-level implementation. We argue that competitive programming is fundamentally a problem-solving task and propose centering natural-language editorials in both solution generation and evaluation. Generating an editorial prior to code improves solve rates for some LLMs, with substantially larger gains when using expertly written gold editorials. However, even with gold editorials, models continue to struggle with implementation, while the gap between generated and gold editorials reveals a persistent problem-solving bottleneck in specifying correct and complete algorithms. Beyond pass/fail metrics, we diagnose reasoning errors by comparing model-generated editorials to gold standards using expert annotations and validate an LLM-as-a-judge protocol for scalable evaluation. We introduce a dataset of 83 ICPC-style problems with gold editorials and full test suites, and evaluate 19 LLMs, arguing that future benchmarks should explicitly separate problem solving from implementation.