F-Actor: Controllable Conversational Behaviour in Full-Duplex Models
作者: Maike Züfle, Ondrej Klejch, Nicholas Sanders, Jan Niehues, Alexandra Birch, Tsz Kin Lam
分类: cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出F-Actor:一个可控的全双工会话语音模型,提升人机交互自然度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全双工对话系统 可控会话行为 指令遵循 语音生成 人机交互
📋 核心要点
- 现有口语会话系统缺乏对会话行为的定制能力,限制了人机交互的自然性和可用性。
- F-Actor模型通过冻结音频编码器并微调语言模型,实现了在有限资源下对会话行为的有效控制。
- 该模型能够根据指令控制说话者声音、会话主题、后信道和对话发起等多种会话属性。
📝 摘要(中文)
为了使口语会话系统更自然和吸引人,需要产生能够动态适应上下文的会话行为,而不仅仅是准确的语音生成。然而,目前的口语会话系统很少允许这种定制,限制了它们的自然性和可用性。本文提出了第一个开放的、遵循指令的全双工会话语音模型,该模型可以在典型的学术资源约束下高效训练。通过冻结音频编码器并仅微调语言模型,我们的模型仅需2000小时的数据,无需依赖大规模预训练或多阶段优化。该模型可以遵循明确的指令来控制说话者声音、会话主题、会话行为(例如,后信道和中断)以及对话发起。我们提出了一种单阶段训练协议,并系统地分析了设计选择。模型和训练代码都将发布,以实现对可控全双工语音系统可复现的研究。
🔬 方法详解
问题定义:现有口语会话系统难以定制会话行为,例如控制说话者声音、会话主题、后信道和对话发起等,导致人机交互不够自然。现有方法通常需要大规模预训练或多阶段优化,计算资源需求高,难以在学术界推广。
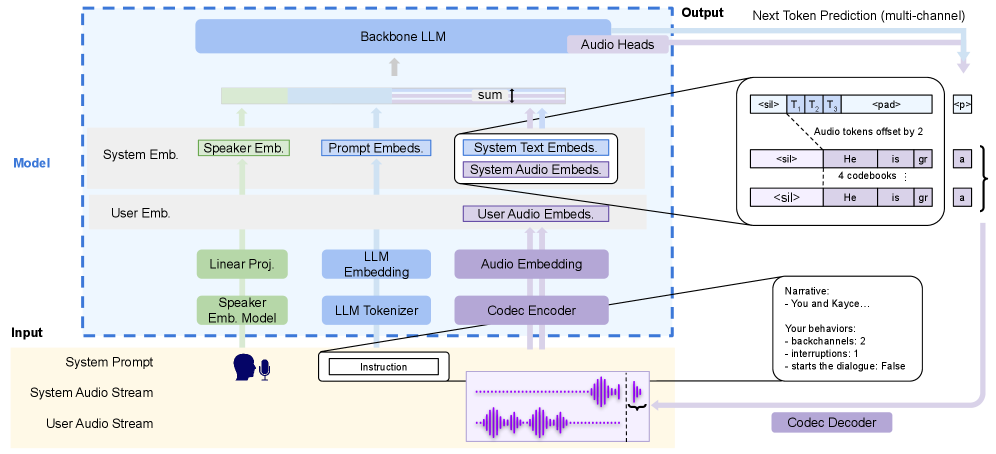
核心思路:本文的核心思路是利用指令遵循(instruction-following)的方式,通过明确的指令来控制全双工会话语音模型的行为。通过冻结音频编码器,只微调语言模型,降低了训练成本,使得在有限的计算资源下也能实现可控的会话行为。
技术框架:F-Actor模型采用全双工架构,包含音频编码器和语言模型两个主要模块。音频编码器负责将语音信号转换为特征表示,语言模型则基于这些特征生成回复文本。模型的训练采用单阶段训练协议,即同时优化所有可训练参数。
关键创新:该模型的主要创新在于:1) 提出了一个可控的全双工会话语音模型,能够根据指令控制多种会话属性;2) 采用单阶段训练协议,降低了训练成本,使得在有限资源下也能实现有效训练;3) 公开了模型和训练代码,促进了可复现的研究。
关键设计:音频编码器采用预训练模型,并保持参数冻结。语言模型采用Transformer架构,并进行微调。损失函数包括语言模型损失和指令遵循损失。训练数据包含2000小时的会话数据,并添加了指令信息。模型通过调整指令的格式和内容,可以控制说话者声音、会话主题、后信道和对话发起等会话属性。
🖼️ 关键图片

📊 实验亮点
该模型在2000小时的数据上进行了训练,无需大规模预训练或多阶段优化,即可实现对说话者声音、会话主题、会话行为和对话发起的有效控制。实验结果表明,该模型能够较好地遵循指令,生成自然流畅的会话语音。
🎯 应用场景
该研究成果可应用于智能客服、虚拟助手、教育机器人等领域,提升人机交互的自然性和用户体验。通过控制会话行为,可以使对话系统更具个性化和适应性,从而更好地满足用户的需求。未来,该技术有望应用于更广泛的场景,例如情感计算、心理咨询等。
📄 摘要(原文)
Spoken conversational systems require more than accurate speech generation to have human-like conversations: to feel natural and engaging, they must produce conversational behaviour that adapts dynamically to the context. Current spoken conversational systems, however, rarely allow such customization, limiting their naturalness and usability. In this work, we present the first open, instruction-following full-duplex conversational speech model that can be trained efficiently under typical academic resource constraints. By keeping the audio encoder frozen and finetuning only the language model, our model requires just 2,000 hours of data, without relying on large-scale pretraining or multi-stage optimization. The model can follow explicit instructions to control speaker voice, conversation topic, conversational behaviour (e.g., backchanneling and interruptions), and dialogue initiation. We propose a single-stage training protocol and systematically analyze design choices. Both the model and training code will be released to enable reproducible research on controllable full-duplex speech systems.