One LLM to Train Them All: Multi-Task Learning Framework for Fact-Checking
作者: Malin Astrid Larsson, Harald Fosen Grunnaleite, Vinay Setty
分类: cs.CL
发布日期: 2026-01-16
备注: Accepted version in ECIR 2026
💡 一句话要点
提出基于多任务学习的自动事实核查框架,提升小模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 自动事实核查 大型语言模型 指令调优 证据排序
📋 核心要点
- 现有自动事实核查方法依赖多个独立模型,成本高且效率低,难以充分利用数据。
- 论文提出多任务学习框架,使用单个小型语言模型同时执行声明检测、证据排序和立场检测。
- 实验结果表明,该方法在多个任务上显著优于零/少样本设置,并提供了实践指导。
📝 摘要(中文)
大型语言模型(LLMs)通过实现统一的端到端验证流程,正在重塑自动事实核查(AFC),取代了孤立的组件。虽然大型专有模型表现出色,但其封闭的权重、复杂性和高成本限制了可持续性。为单个AFC任务微调较小的开源权重模型有所帮助,但需要多个专用模型,从而导致高成本。我们提出多任务学习(MTL)作为一种更有效的替代方案,该方案微调单个模型以联合执行声明检测、证据排序和立场检测。使用小型解码器LLM(例如,Qwen3-4b),我们探索了三种MTL策略:分类头、因果语言建模头和指令调优,并在模型大小、任务顺序和标准非LLM基线上评估它们。虽然多任务模型并非普遍超越单任务基线,但它们产生了显著的改进,在零/少样本设置下,声明检测、证据重新排序和立场检测分别实现了高达44%、54%和31%的相对收益。最后,我们还提供了实用的、基于经验的指南,以帮助从业者将MTL与LLM应用于自动事实核查。
🔬 方法详解
问题定义:自动事实核查(AFC)通常需要多个独立的任务,例如声明检测、证据检索和立场检测。现有方法通常为每个任务训练一个单独的模型,这导致了高昂的计算成本和维护成本。此外,这些独立训练的模型无法共享知识,从而限制了整体性能。
核心思路:论文的核心思路是利用多任务学习(MTL)框架,训练一个单一的语言模型来同时执行多个AFC任务。通过共享模型参数,MTL可以提高模型的泛化能力,并减少训练所需的资源。论文探索了不同的MTL策略,例如分类头、因果语言建模头和指令调优,以找到最适合AFC任务的组合。
技术框架:该框架使用一个预训练的小型解码器LLM(例如,Qwen3-4b)作为基础模型。然后,根据不同的MTL策略,在基础模型之上添加不同的任务特定头。例如,对于分类任务(如声明检测和立场检测),可以使用分类头;对于序列生成任务(如证据排序),可以使用因果语言建模头。指令调优则通过在训练数据中加入指令,引导模型学习执行不同的任务。
关键创新:该论文的关键创新在于将多任务学习应用于自动事实核查领域,并探索了不同的MTL策略在小型LLM上的有效性。与以往的单任务模型相比,该方法能够显著提高模型的效率和性能。此外,论文还提供了实用的指导,帮助从业者将MTL应用于实际的AFC任务。
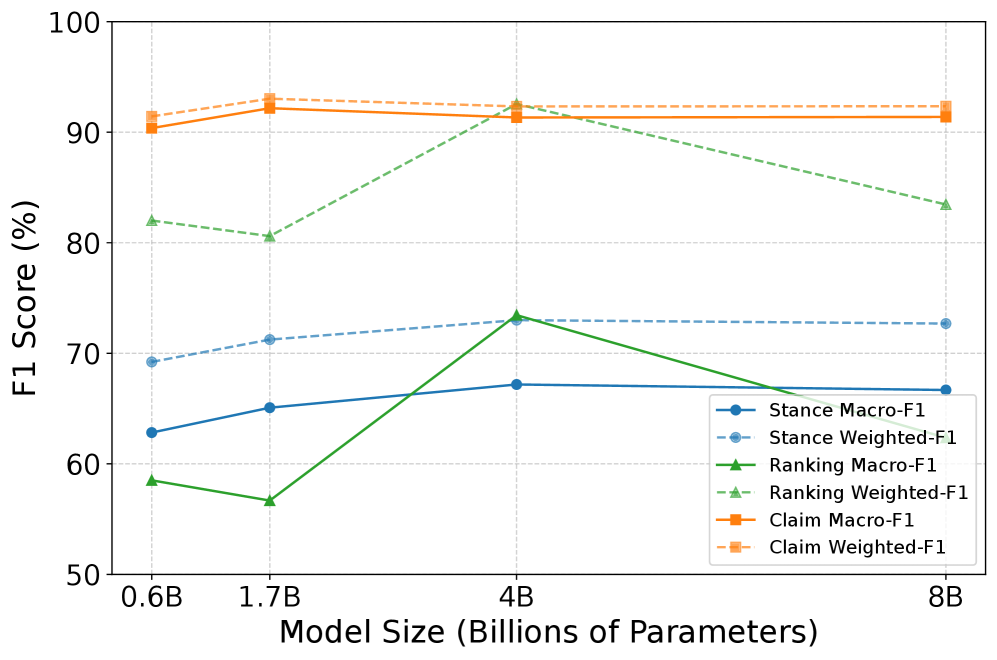
关键设计:论文探索了三种MTL策略:1) 分类头:为每个分类任务添加一个独立的分类层;2) 因果语言建模头:使用语言模型生成文本,例如证据排序;3) 指令调优:在训练数据中加入指令,指导模型执行不同的任务。论文还研究了不同的任务顺序对模型性能的影响,并评估了不同模型大小的影响。
🖼️ 关键图片
📊 实验亮点
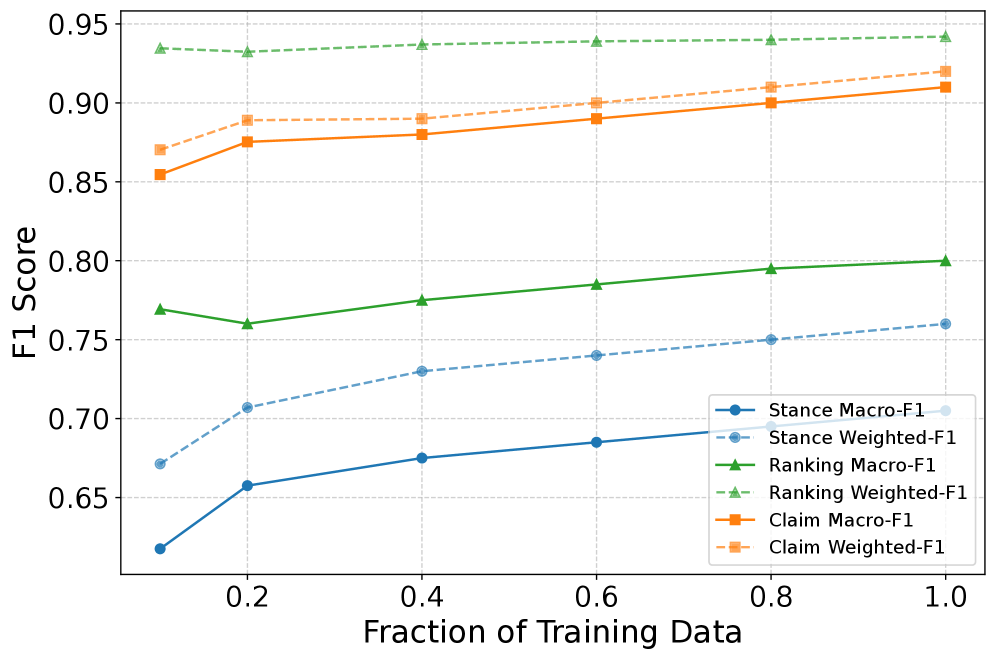
实验结果表明,多任务学习框架在声明检测、证据重新排序和立场检测任务上分别实现了高达44%、54%和31%的相对收益,显著优于零/少样本设置。该研究还发现,不同的MTL策略和任务顺序对模型性能有显著影响,并提供了实践指导。
🎯 应用场景
该研究成果可应用于自动化新闻事实核查系统、虚假信息检测平台等领域,有助于提高信息的可信度和透明度。通过降低模型训练和部署的成本,该方法使得自动事实核查技术能够更广泛地应用于资源有限的场景,例如低成本新闻媒体和社区平台。
📄 摘要(原文)
Large language models (LLMs) are reshaping automated fact-checking (AFC) by enabling unified, end-to-end verification pipelines rather than isolated components. While large proprietary models achieve strong performance, their closed weights, complexity, and high costs limit sustainability. Fine-tuning smaller open weight models for individual AFC tasks can help but requires multiple specialized models resulting in high costs. We propose \textbf{multi-task learning (MTL)} as a more efficient alternative that fine-tunes a single model to perform claim detection, evidence ranking, and stance detection jointly. Using small decoder-only LLMs (e.g., Qwen3-4b), we explore three MTL strategies: classification heads, causal language modeling heads, and instruction-tuning, and evaluate them across model sizes, task orders, and standard non-LLM baselines. While multitask models do not universally surpass single-task baselines, they yield substantial improvements, achieving up to \textbf{44\%}, \textbf{54\%}, and \textbf{31\%} relative gains for claim detection, evidence re-ranking, and stance detection, respectively, over zero-/few-shot settings. Finally, we also provide practical, empirically grounded guidelines to help practitioners apply MTL with LLMs for automated fact-checking.