FactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
作者: Javier Carnerero-Cano, Massimiliano Pronesti, Radu Marinescu, Tigran Tchrakian, James Barry, Jasmina Gajcin, Yufang Hou, Alessandra Pascale, Elizabeth Daly
分类: cs.CL, cs.AI
发布日期: 2026-01-16
💡 一句话要点
FactCorrector:一种图结构驱动的大语言模型长文本事实性纠正方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实性纠正 大语言模型 图神经网络 知识图谱 长文本生成
📋 核心要点
- 现有大语言模型在知识密集型任务中常产生事实性错误,缺乏有效的后处理纠正方法。
- FactCorrector利用图结构化的事实性反馈,无需重新训练即可跨领域纠正LLM生成的事实错误。
- 在VELI5等数据集上,FactCorrector显著提升了事实精确性,同时保持了回复的相关性,优于现有方法。
📝 摘要(中文)
大型语言模型(LLMs)被广泛应用于知识密集型应用中,但经常生成事实不正确的回复。一个有希望的方法是使用反馈来纠正LLMs的这些缺陷。因此,在本文中,我们介绍了一种新的事后纠正方法FactCorrector,它可以在不重新训练的情况下适应不同的领域,并利用关于原始回复事实性的结构化反馈来生成纠正。为了支持对事实性纠正方法的严格评估,我们还开发了VELI5基准,这是一个包含系统注入的事实错误和ground-truth纠正的新数据集。在VELI5和几个流行的长文本事实性数据集上的实验表明,FactCorrector方法在保持相关性的同时,显著提高了事实精确性,优于强大的基线。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成长文本时出现的事实性错误问题。现有方法要么需要大量重新训练,要么难以有效利用关于错误的结构化反馈信息,导致纠正效果不佳,且泛化能力有限。
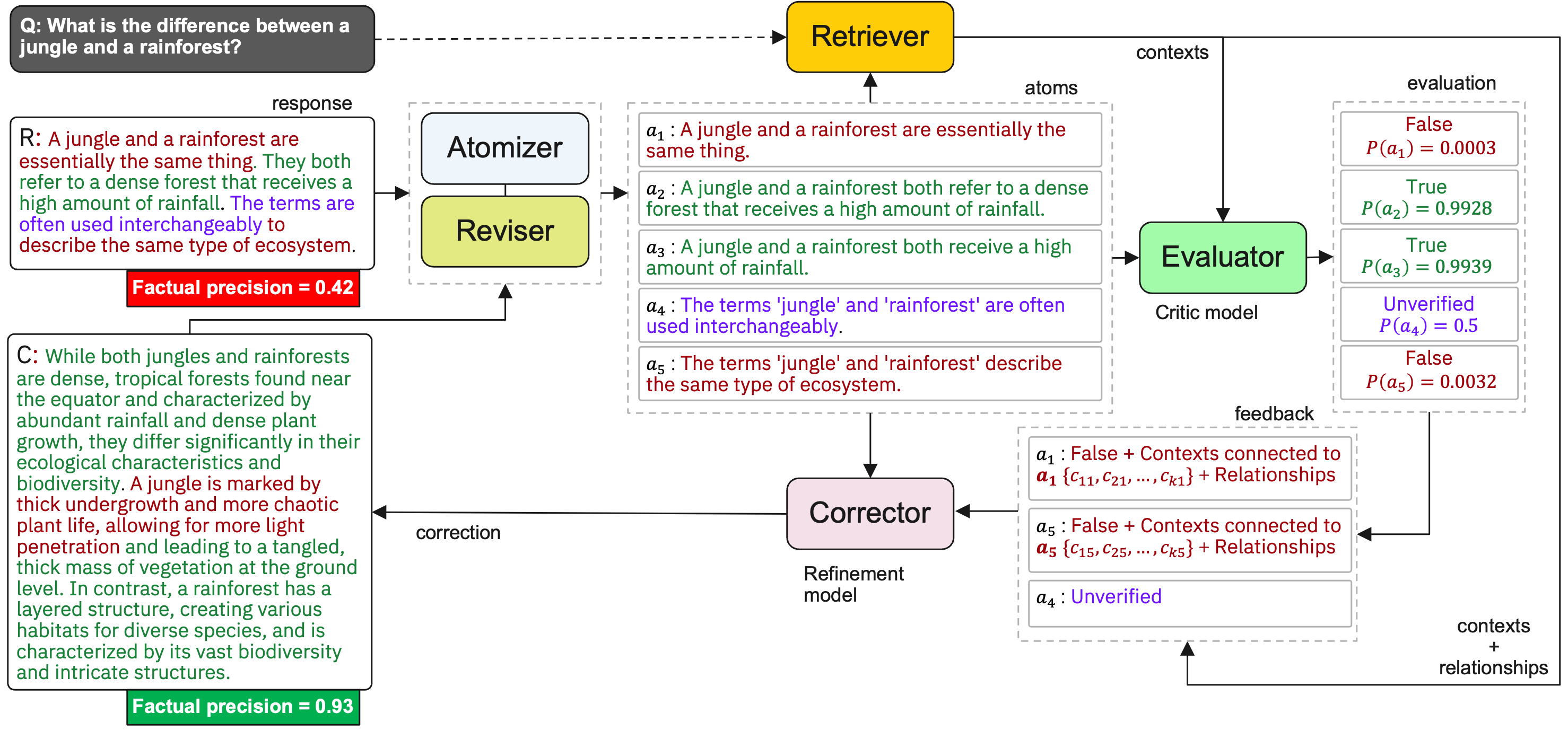
核心思路:FactCorrector的核心思路是利用图结构来表示和处理关于原始回复的事实性反馈。通过构建图,将原始回复的各个部分及其对应的事实性判断连接起来,从而更有效地定位和纠正错误。这种方法无需重新训练模型,即可适应不同的领域。
技术框架:FactCorrector主要包含以下几个阶段:1) 事实性判断提取:从外部知识源或人工标注中获取关于原始回复的事实性判断。2) 图构建:基于原始回复和事实性判断,构建一个图结构,其中节点表示回复的各个部分,边表示它们之间的关系(例如,支持、反对、中立)。3) 错误定位:利用图结构和事实性判断,定位原始回复中可能存在错误的部分。4) 纠正生成:基于错误定位的结果,生成对原始回复的纠正。这个过程可以使用预训练的语言模型,并结合图结构信息进行指导。
关键创新:FactCorrector的关键创新在于其利用图结构来表示和处理事实性反馈。这种方法能够更有效地利用结构化信息,从而更准确地定位和纠正错误。此外,FactCorrector无需重新训练模型,即可适应不同的领域,具有较强的泛化能力。
关键设计:在图构建方面,论文可能采用了不同的图结构表示方法,例如知识图谱或依赖图。在纠正生成方面,论文可能使用了不同的损失函数来指导模型的训练,例如对比学习损失或生成对抗网络损失。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
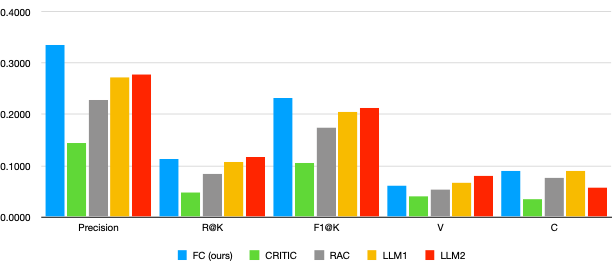
实验结果表明,FactCorrector在VELI5数据集上显著提高了事实精确性,同时保持了回复的相关性。与其他基线方法相比,FactCorrector在多个指标上都取得了显著的提升,证明了其有效性和优越性。VELI5数据集的发布也为后续研究提供了有价值的基准。
🎯 应用场景
FactCorrector可应用于各种知识密集型应用,例如自动问答系统、内容生成平台和智能助手。通过提高LLM生成内容的准确性和可靠性,FactCorrector可以提升用户体验,减少错误信息的传播,并促进知识的有效利用。该研究对提升AI系统的可信度和实用性具有重要意义。
📄 摘要(原文)
Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.