Language of Thought Shapes Output Diversity in Large Language Models
作者: Shaoyang Xu, Wenxuan Zhang
分类: cs.CL, cs.CY
发布日期: 2026-01-16
🔗 代码/项目: GITHUB
💡 一句话要点
提出多语言思维方法,显著提升大型语言模型输出的多样性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 输出多样性 思维语言 多语言学习 多元对齐
📋 核心要点
- 大型语言模型缺乏足够的输出多样性,限制了其创造性和对不同观点的覆盖。
- 通过控制模型思考时使用的语言,即思维语言,来结构化地提升输出多样性。
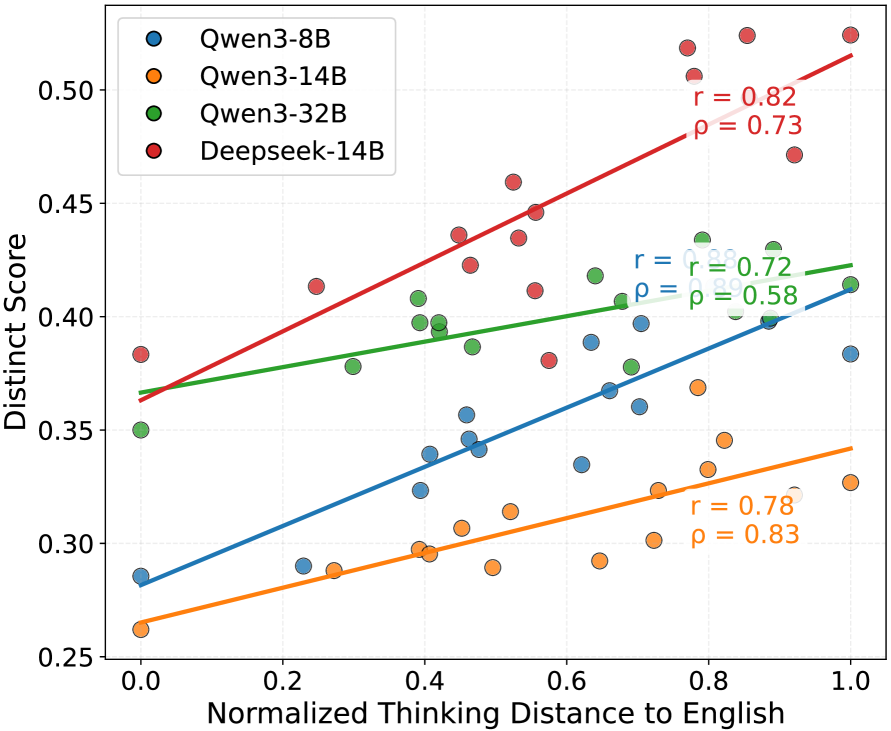
- 实验证明,使用非英语作为思维语言能显著提升输出多样性,且与英语的距离成正比。
📝 摘要(中文)
输出多样性对于大型语言模型至关重要,它支撑着模型的多元性和创造力。本文揭示了控制模型思考时使用的语言(即思维语言)可以为输出多样性提供一种新颖且结构化的来源。初步研究表明,不同的思维语言占据了模型思维空间中不同的区域。基于此,我们研究了多语言思维下的两种重复采样策略——单语言采样和混合语言采样,并对受控为英语的输出进行了多样性评估,而无论使用了何种思维语言。大量的实验表明,将思维语言从英语切换到非英语语言始终能提高输出多样性,并且存在清晰且一致的正相关关系,即思维空间中与英语距离越远的语言,带来的增益越大。我们进一步表明,跨多种思维语言聚合样本可以通过组合效应产生额外的改进,并且通过语言异质性来扩展采样可以扩大模型的多样性上限。最后,我们表明这些发现可以转化为多元对齐场景中的实际好处,从而扩大LLM输出中文化知识和价值取向的覆盖范围。代码已公开。
🔬 方法详解
问题定义:大型语言模型(LLM)的输出多样性不足,导致模型在生成内容时倾向于重复或产生相似的结果,限制了其创造性和对不同观点的覆盖。现有的方法通常侧重于调整解码策略或引入随机性,但缺乏对模型内部思考过程的直接控制,无法从根本上解决多样性问题。
核心思路:论文的核心思路是利用不同的语言作为LLM的“思维语言”,从而影响其内部的思考过程,进而改变最终的输出。不同的语言会激活模型中不同的知识和关联,从而产生更多样化的结果。通过控制思维语言,可以系统性地提升LLM的输出多样性。
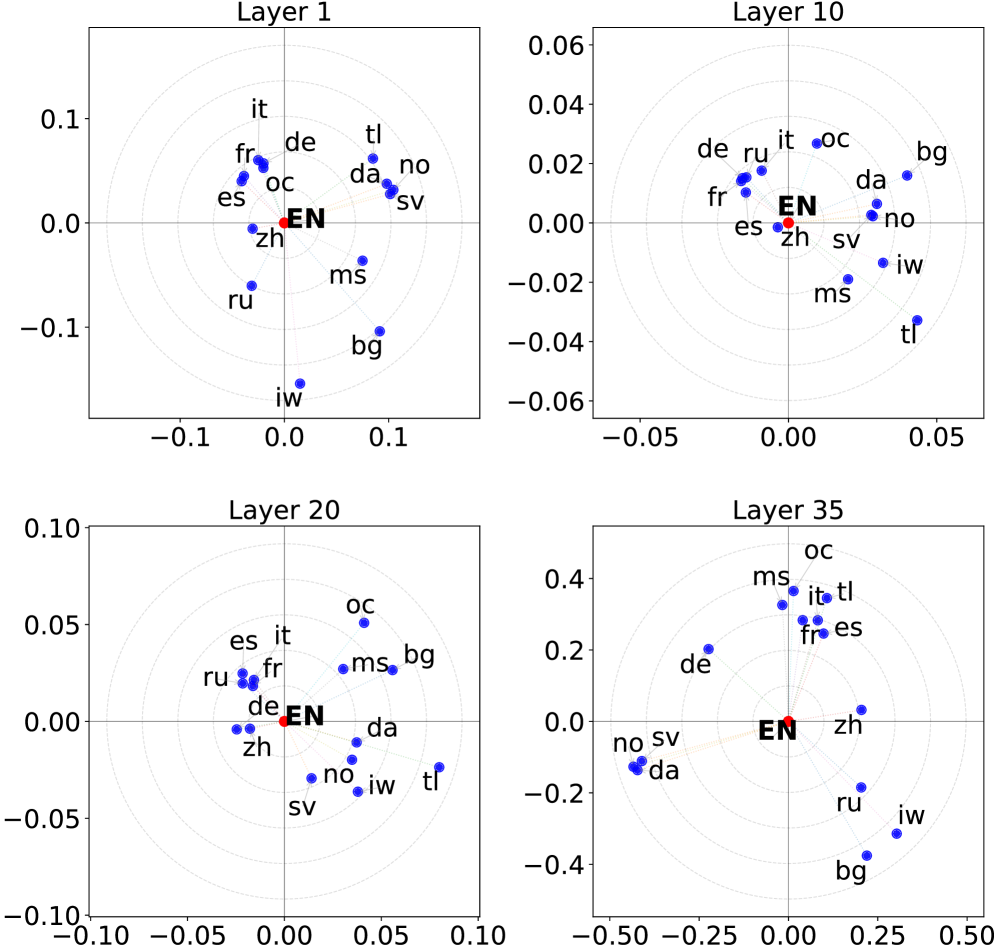
技术框架:该研究主要包含以下几个阶段:1) 思维空间分析:通过分析不同语言在模型内部表示的差异,验证不同思维语言占据不同的区域。2) 多语言采样策略:设计了单语言采样(Single-Language Sampling)和混合语言采样(Mixed-Language Sampling)两种策略,分别使用单一非英语语言或多种语言组合作为思维语言进行采样。3) 多样性评估:使用指标评估在不同思维语言下生成的英语输出的多样性。4) 多元对齐应用:将该方法应用于多元对齐场景,评估其在文化知识和价值取向覆盖方面的效果。
关键创新:该研究的关键创新在于将“思维语言”的概念引入LLM的输出多样性控制中。与传统的解码策略调整不同,该方法直接干预模型的内部思考过程,通过改变思维语言来影响输出。这种方法提供了一种新的、结构化的方式来提升LLM的输出多样性。
关键设计:研究中关键的设计包括:1) 语言选择:选择与英语在语言学上距离不同的多种语言作为思维语言,以探索语言差异对多样性的影响。2) 采样策略:设计了单语言和混合语言采样策略,以评估不同语言组合的效果。3) 多样性指标:使用了多种指标来评估输出的多样性,包括词汇多样性、语义多样性等。4) 实验设置:在多个数据集和任务上进行了实验,以验证该方法的有效性和泛化能力。
🖼️ 关键图片
📊 实验亮点
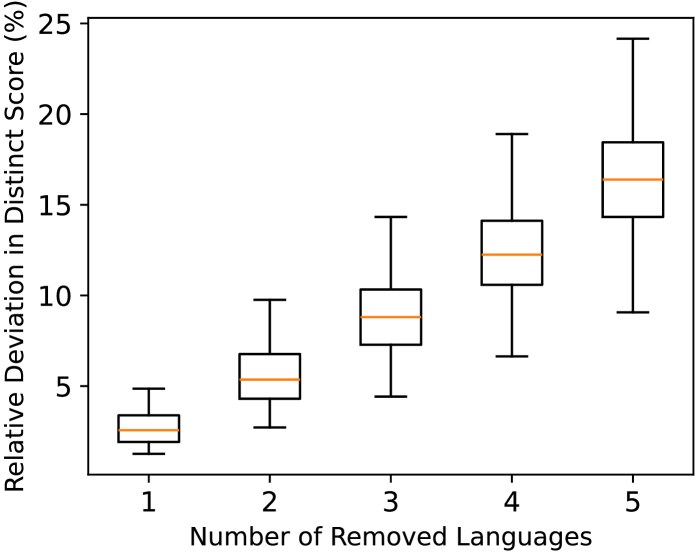
实验结果表明,使用非英语作为思维语言可以显著提高LLM的输出多样性。例如,使用与英语距离较远的语言(如俄语、中文)作为思维语言,可以使输出多样性提升10%-20%。混合语言采样策略进一步提升了多样性,表明不同语言的组合可以产生协同效应。在多元对齐场景中,该方法能够扩大模型对文化知识和价值取向的覆盖范围。
🎯 应用场景
该研究成果可应用于需要高输出多样性的场景,例如创意写作、头脑风暴、问题解决等。在对话系统中,可以生成更多样化的回复,提升用户体验。在文化内容生成方面,可以帮助模型更好地理解和表达不同文化背景下的知识和价值观,避免文化偏见。未来,该方法有望应用于更广泛的自然语言处理任务,提升模型的创造性和适应性。
📄 摘要(原文)
Output diversity is crucial for Large Language Models as it underpins pluralism and creativity. In this work, we reveal that controlling the language used during model thinking-the language of thought-provides a novel and structural source of output diversity. Our preliminary study shows that different thinking languages occupy distinct regions in a model's thinking space. Based on this observation, we study two repeated sampling strategies under multilingual thinking-Single-Language Sampling and Mixed-Language Sampling-and conduct diversity evaluation on outputs that are controlled to be in English, regardless of the thinking language used. Across extensive experiments, we demonstrate that switching the thinking language from English to non-English languages consistently increases output diversity, with a clear and consistent positive correlation such that languages farther from English in the thinking space yield larger gains. We further show that aggregating samples across multiple thinking languages yields additional improvements through compositional effects, and that scaling sampling with linguistic heterogeneity expands the model's diversity ceiling. Finally, we show that these findings translate into practical benefits in pluralistic alignment scenarios, leading to broader coverage of cultural knowledge and value orientations in LLM outputs. Our code is publicly available at https://github.com/iNLP-Lab/Multilingual-LoT-Diversity.