MultiCaption: Detecting disinformation using multilingual visual claims
作者: Rafael Martins Frade, Rrubaa Panchendrarajan, Arkaitz Zubiaga
分类: cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出MultiCaption数据集,用于检测多语言视觉声明中的虚假信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言 视觉声明 虚假信息检测 事实核查 自然语言推理
📋 核心要点
- 现有事实核查数据集难以反映多媒体和多语言环境下虚假信息的复杂性,限制了自动事实核查方法的有效性。
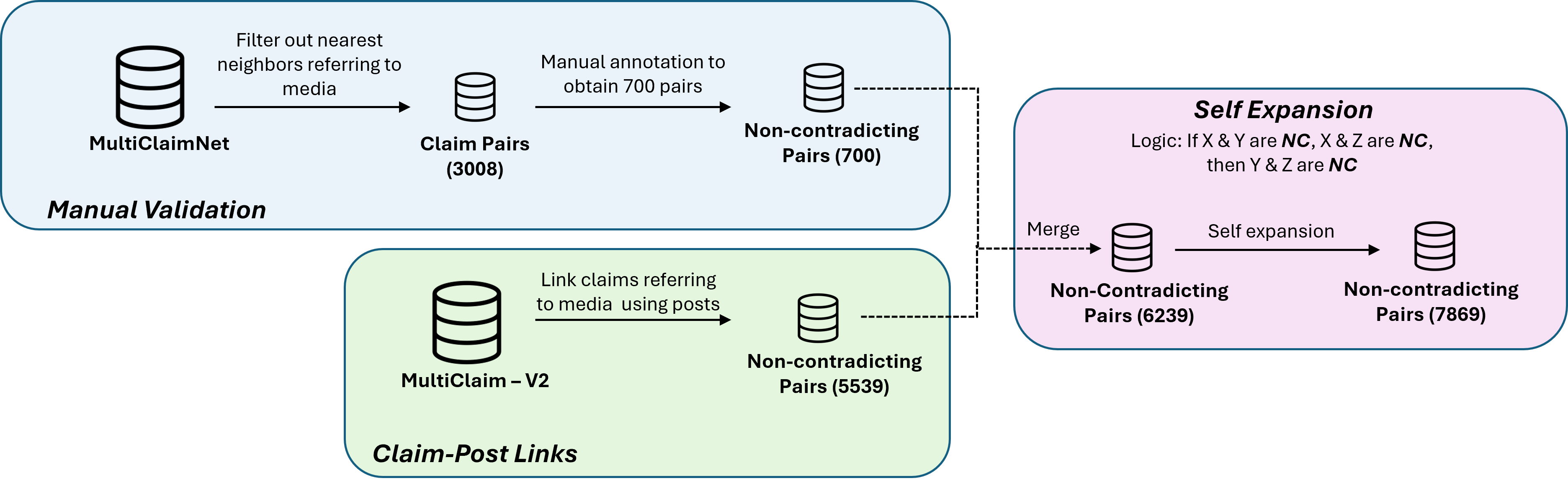
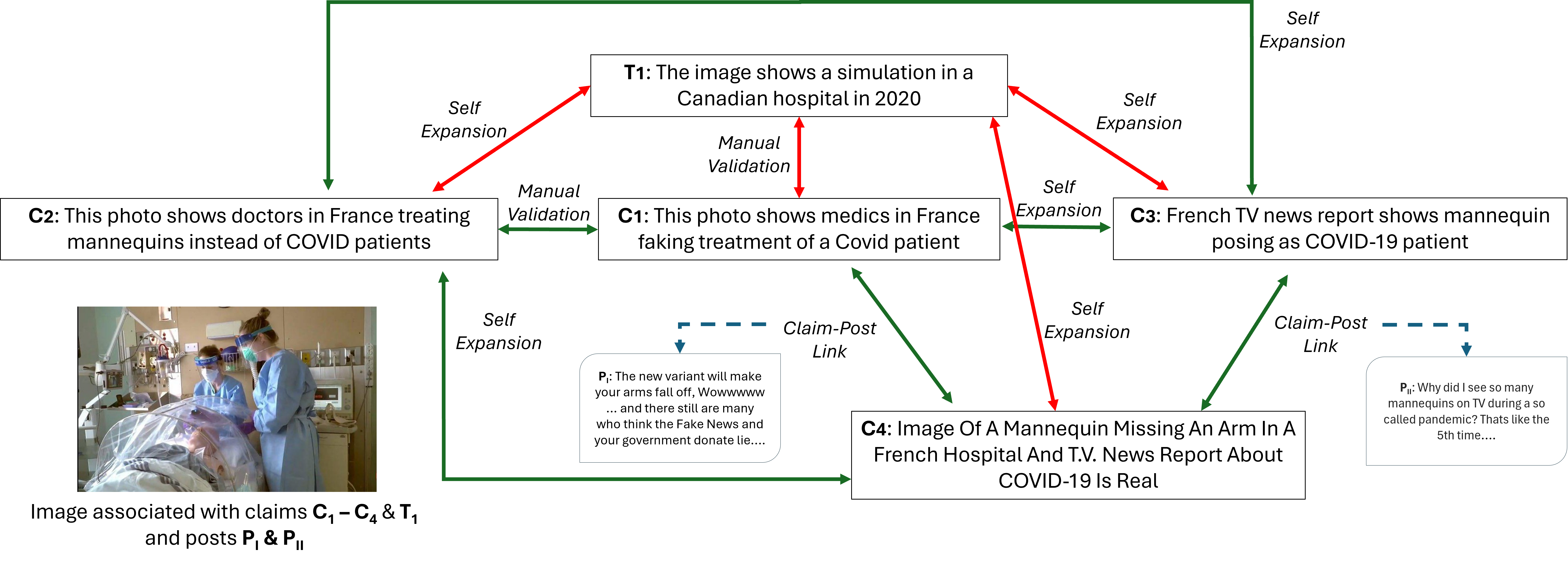
- 论文构建了MultiCaption数据集,包含64种语言的11,088个视觉声明,用于检测视觉声明中的矛盾,无需依赖机器翻译。
- 实验表明MultiCaption数据集具有挑战性,需要针对特定任务进行微调,多语言训练能有效提升性能。
📝 摘要(中文)
在线虚假信息对社会构成日益严重的威胁,其驱动力是误导性内容在多媒体和多语言平台上的快速传播。虽然自动事实核查方法近年来取得了进展,但其有效性仍然受到数据集稀缺的限制,这些数据集未能反映现实世界的复杂性。为了解决这个问题,我们首先提出了MultiCaption,这是一个专门为检测视觉声明中矛盾而设计的新数据集。通过多种策略对引用相同图像或视频的声明对进行标记,以确定它们是否相互矛盾。最终的数据集包含64种语言的11,088个视觉声明,为构建和评估真正多模态和多语言环境中的虚假信息检测系统提供了独特的资源。然后,我们使用基于Transformer的架构、自然语言推理模型和大型语言模型进行了全面的实验,为未来的研究建立了强大的基线。结果表明,MultiCaption比标准的NLI任务更具挑战性,需要针对特定任务进行微调才能获得良好的性能。此外,多语言训练和测试的收益突出了该数据集在构建有效的多语言事实核查流程方面的潜力,而无需依赖机器翻译。
🔬 方法详解
问题定义:论文旨在解决多语言环境下视觉声明的事实核查问题。现有方法依赖于单语数据集或机器翻译,无法有效处理多语言环境下的虚假信息检测,且缺乏专门针对视觉声明矛盾检测的数据集。
核心思路:论文的核心思路是构建一个大规模、多语言的视觉声明矛盾检测数据集,并利用该数据集训练模型,使其能够直接在多语言环境下进行事实核查,避免依赖机器翻译带来的信息损失和误差累积。
技术框架:整体框架包括数据集构建和模型训练两个阶段。数据集构建阶段,收集包含图像/视频和对应声明的样本,并标注声明之间的矛盾关系。模型训练阶段,使用基于Transformer的架构、自然语言推理模型和大型语言模型在MultiCaption数据集上进行训练和评估。
关键创新:关键创新在于构建了MultiCaption数据集,该数据集是首个大规模、多语言的视觉声明矛盾检测数据集,涵盖64种语言,为多语言事实核查研究提供了宝贵的资源。此外,论文还探索了多语言训练在事实核查中的应用,证明了其有效性。
关键设计:数据集构建过程中,采用了多种策略来标注声明之间的矛盾关系,确保标注的准确性和一致性。模型训练过程中,使用了交叉熵损失函数来优化模型,并采用了微调策略来提升模型在MultiCaption数据集上的性能。具体参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MultiCaption数据集比标准的NLI任务更具挑战性,需要针对特定任务进行微调才能获得良好的性能。多语言训练和测试显著提升了模型的性能,表明该数据集在构建有效的多语言事实核查流程方面具有巨大潜力。具体性能数据和提升幅度在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻媒体等领域,用于自动检测和识别多语言环境下的虚假信息,提高信息的可信度和透明度。未来,可以进一步研究如何将该方法与其他事实核查技术相结合,构建更完善的虚假信息检测系统,从而有效遏制虚假信息的传播。
📄 摘要(原文)
Online disinformation poses an escalating threat to society, driven increasingly by the rapid spread of misleading content across both multimedia and multilingual platforms. While automated fact-checking methods have advanced in recent years, their effectiveness remains constrained by the scarcity of datasets that reflect these real-world complexities. To address this gap, we first present MultiCaption, a new dataset specifically designed for detecting contradictions in visual claims. Pairs of claims referring to the same image or video were labeled through multiple strategies to determine whether they contradict each other. The resulting dataset comprises 11,088 visual claims in 64 languages, offering a unique resource for building and evaluating misinformation-detection systems in truly multimodal and multilingual environments. We then provide comprehensive experiments using transformer-based architectures, natural language inference models, and large language models, establishing strong baselines for future research. The results show that MultiCaption is more challenging than standard NLI tasks, requiring task-specific finetuning for strong performance. Moreover, the gains from multilingual training and testing highlight the dataset's potential for building effective multilingual fact-checking pipelines without relying on machine translation.