CoG: Controllable Graph Reasoning via Relational Blueprints and Failure-Aware Refinement over Knowledge Graphs
作者: Yuanxiang Liu, Songze Li, Xiaoke Guo, Zhaoyan Gong, Qifei Zhang, Huajun Chen, Wen Zhang
分类: cs.CL, cs.LG
发布日期: 2026-01-16
💡 一句话要点
CoG:通过关系蓝图和失败感知精炼实现知识图谱上的可控图推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱推理 大型语言模型 双过程理论 关系蓝图 失败感知精炼 可控推理 免训练框架
📋 核心要点
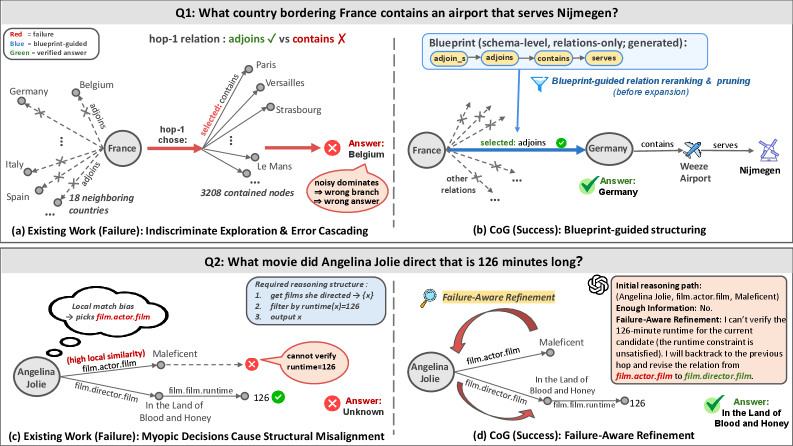
- 现有KG增强LLM方法认知僵化,易受噪声和结构错位影响,导致推理停滞。
- CoG框架模拟双过程理论,利用关系蓝图引导搜索方向,并进行失败感知精炼。
- 实验表明,CoG在准确性和效率上显著优于现有方法,提升了知识图谱推理性能。
📝 摘要(中文)
大型语言模型(LLMs)展现了卓越的推理能力,但常常面临幻觉等可靠性挑战。知识图谱(KGs)提供了显式的 grounding,但现有的KG增强LLM范式通常表现出认知僵化——应用同质的搜索策略,使其容易受到邻域噪声和结构错位的影响,导致推理停滞。为了解决这些挑战,我们提出了CoG,一个受双过程理论启发的免训练框架,模拟直觉和审议之间的相互作用。首先,作为快速、直观的过程,关系蓝图引导模块利用关系蓝图作为可解释的软结构约束,快速稳定搜索方向以对抗噪声。其次,作为谨慎、分析的过程,失败感知精炼模块在遇到推理僵局时进行干预。它触发证据条件反射并执行受控回溯以克服推理停滞。在三个基准测试上的实验结果表明,CoG在准确性和效率方面均显著优于最先进的方法。
🔬 方法详解
问题定义:现有基于知识图谱增强的大语言模型在进行推理时,通常采用同质化的搜索策略,这种策略在面对知识图谱中的噪声(例如错误的边或实体)以及结构错位(例如图谱结构与推理任务不匹配)时,容易陷入推理停滞,无法有效利用知识图谱进行可靠的推理。现有方法缺乏对推理过程的有效控制和动态调整机制。
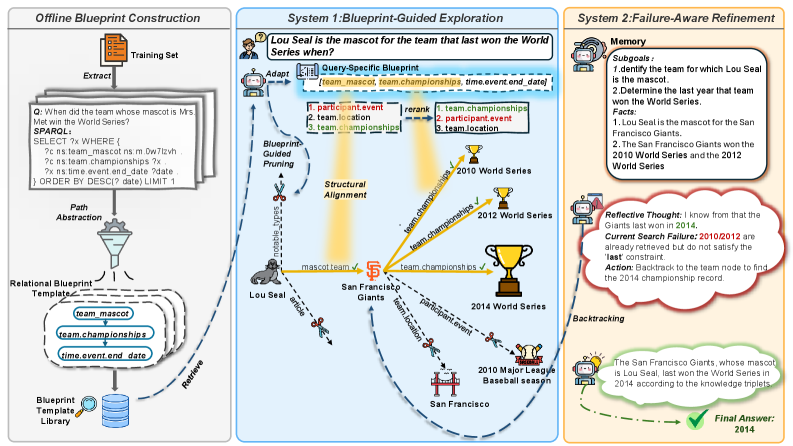
核心思路:CoG的核心思路是模拟人类的“双过程理论”,即直觉和审议的结合。它将知识图谱推理过程分解为两个阶段:首先,利用“关系蓝图”快速确定推理方向,类似于直觉;然后,在遇到推理瓶颈时,通过“失败感知精炼”进行回溯和反思,类似于审议。通过这种方式,CoG能够更稳健地应对知识图谱中的噪声和结构错位,提高推理的准确性和效率。
技术框架:CoG框架包含两个主要模块:关系蓝图引导模块和失败感知精炼模块。关系蓝图引导模块利用预定义的“关系蓝图”作为软约束,引导推理过程沿着更有可能成功的路径进行。失败感知精炼模块则监控推理过程,一旦检测到推理停滞,就会触发回溯机制,并根据已有的证据进行反思,调整推理策略。整个框架无需训练,可以直接应用于现有的知识图谱推理任务。
关键创新:CoG的关键创新在于其双过程推理机制,以及关系蓝图和失败感知精炼这两个模块的设计。关系蓝图提供了一种可解释的结构约束,能够快速稳定搜索方向。失败感知精炼则通过动态调整推理策略,克服推理停滞。这种双过程机制使得CoG能够更有效地利用知识图谱进行推理,并提高推理的鲁棒性。
关键设计:关系蓝图是通过分析知识图谱中常见的关系模式得到的,可以人工定义或自动学习。失败感知精炼模块使用证据条件反射机制,根据已有的推理路径和结果,判断是否需要进行回溯。回溯策略包括改变推理方向、放松约束条件等。具体参数设置和网络结构(如果使用)在论文中未明确说明,可能根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
CoG在三个知识图谱推理基准测试上取得了显著的性能提升。具体而言,CoG在准确性和效率方面均优于现有最先进的方法。实验结果表明,CoG能够有效地应对知识图谱中的噪声和结构错位,提高推理的鲁棒性。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
CoG框架可应用于各种需要知识图谱推理的场景,例如问答系统、推荐系统、知识发现等。通过提高知识图谱推理的准确性和效率,CoG可以提升这些应用的性能和用户体验。未来,CoG可以进一步扩展到更复杂的知识图谱推理任务,例如多跳推理、逻辑推理等,并与其他技术(例如强化学习、元学习)相结合,实现更智能的知识图谱推理。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities but often grapple with reliability challenges like hallucinations. While Knowledge Graphs (KGs) offer explicit grounding, existing paradigms of KG-augmented LLMs typically exhibit cognitive rigidity--applying homogeneous search strategies that render them vulnerable to instability under neighborhood noise and structural misalignment leading to reasoning stagnation. To address these challenges, we propose CoG, a training-free framework inspired by Dual-Process Theory that mimics the interplay between intuition and deliberation. First, functioning as the fast, intuitive process, the Relational Blueprint Guidance module leverages relational blueprints as interpretable soft structural constraints to rapidly stabilize the search direction against noise. Second, functioning as the prudent, analytical process, the Failure-Aware Refinement module intervenes upon encountering reasoning impasses. It triggers evidence-conditioned reflection and executes controlled backtracking to overcome reasoning stagnation. Experimental results on three benchmarks demonstrate that CoG significantly outperforms state-of-the-art approaches in both accuracy and efficiency.