Budget-Aware Anytime Reasoning with LLM-Synthesized Preference Data
作者: Xuanming Zhang, Shwan Ashrafi, Aziza Mirsaidova, Amir Rezaeian, Miguel Ballesteros, Lydia B. Chilton, Zhou Yu, Dan Roth
分类: cs.CL
发布日期: 2026-01-16
备注: 13 pages, 3 figures
💡 一句话要点
提出预算感知的随时推理框架,利用LLM合成偏好数据提升推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 随时推理 预算感知 自提升学习 偏好数据
📋 核心要点
- 现有LLM推理在计算资源受限时表现不佳,难以在预算内快速给出高质量的中间结果。
- 提出随时推理框架,并利用LLM合成的偏好数据进行自提升,优化中间结果质量。
- 实验表明,该方法在多个数据集和模型上均能有效提升推理质量和效率,尤其是在预算有限的情况下。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)在有限计算预算下的推理行为。在这种情况下,快速产生有用的部分解决方案通常比耗尽所有计算资源进行详尽推理更实用。许多现实世界的任务,如旅行规划,要求模型在固定的推理预算内提供尽可能好的输出。我们引入了一个随时推理框架和随时索引(Anytime Index),该指标量化了解决方案质量随着推理token增加而提高的有效性。为了进一步提高效率,我们提出了一种使用LLM合成偏好数据的推理时自提升方法,模型通过学习自身的推理比较来产生更好的中间解决方案。在NaturalPlan (Trip)、AIME和GPQA数据集上的实验表明,Grok-3、GPT-oss、GPT-4.1/4o和LLaMA模型均获得了持续的收益,从而提高了预算约束下的推理质量和效率。
🔬 方法详解
问题定义:论文旨在解决LLM在计算预算有限的情况下,如何进行高效的随时推理问题。现有方法通常无法在推理过程中根据预算动态调整策略,导致在预算耗尽时,输出结果的质量可能远低于预期。痛点在于无法在推理时间和结果质量之间取得平衡,尤其是在需要快速响应的场景下。
核心思路:论文的核心思路是引入一个随时推理框架,并利用LLM自身生成的数据进行自提升。通过让LLM学习自身推理过程中的偏好,从而优化中间步骤的输出质量,使得在任何时间点停止推理,都能获得尽可能好的结果。这种方法旨在提高LLM在预算约束下的推理效率和质量。
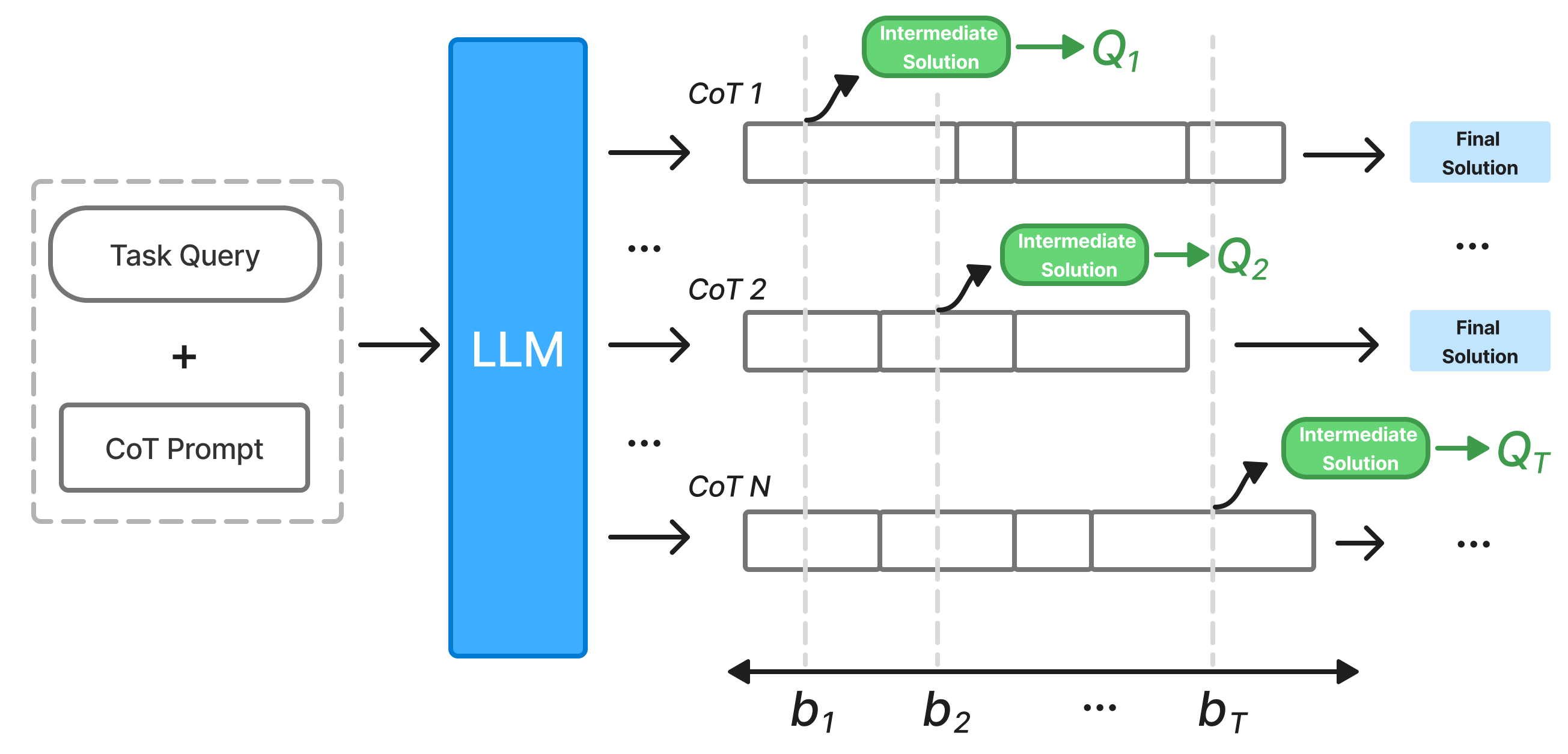
技术框架:整体框架包含以下几个主要阶段:1) 初始推理:使用LLM进行初步推理,生成一系列中间结果。2) 偏好数据合成:利用LLM对中间结果进行比较,生成偏好数据,即哪些中间结果更优。3) 模型自提升:使用合成的偏好数据训练LLM,使其学习如何生成更好的中间结果。4) 随时推理:在推理过程中,根据预算动态调整推理步骤,并输出当前最佳结果。
关键创新:最重要的技术创新点在于利用LLM自身生成偏好数据,进行推理时自提升。与传统的监督学习方法不同,该方法无需人工标注数据,而是通过LLM自身的判断来指导学习过程。这种自监督学习的方式可以有效利用LLM的知识,提高推理效率和质量。另一个创新点是提出了Anytime Index,用于量化随时推理的有效性。
关键设计:在偏好数据合成阶段,论文设计了一种prompting策略,引导LLM对中间结果进行比较,并给出偏好排序。在模型自提升阶段,可以使用不同的损失函数,例如pairwise ranking loss,来训练LLM。此外,还可以调整推理过程中的参数,例如temperature,以控制探索和利用的平衡。
🖼️ 关键图片
📊 实验亮点
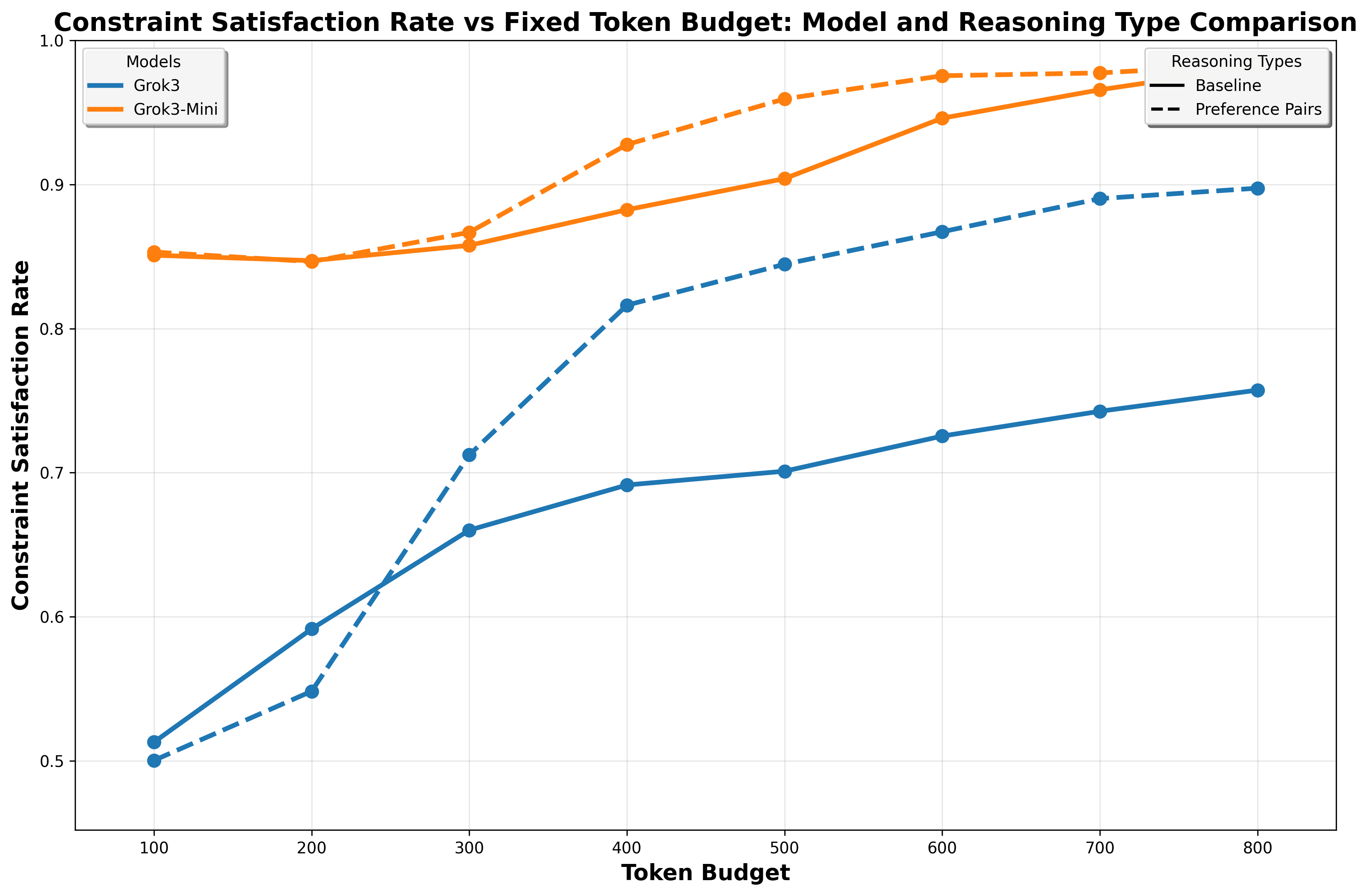
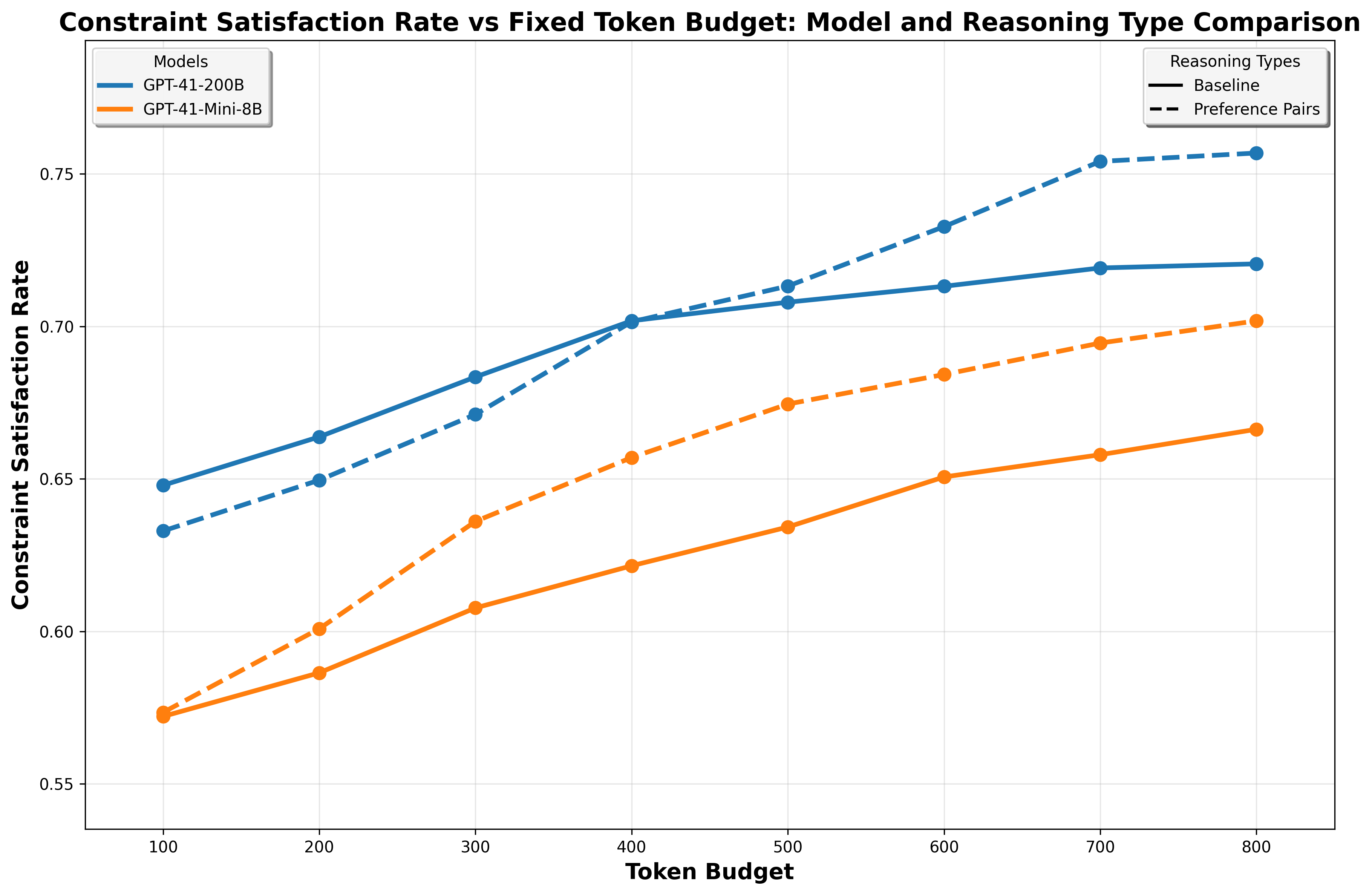
实验结果表明,该方法在NaturalPlan (Trip)、AIME和GPQA数据集上均取得了显著的性能提升。例如,在GPT-4o模型上,使用该方法可以显著提高推理质量,尤其是在预算有限的情况下。与基线方法相比,该方法能够更快地达到相同的性能水平,从而提高了推理效率。
🎯 应用场景
该研究成果可应用于各种需要快速响应和预算感知的场景,例如:旅行规划、智能客服、金融风控等。在这些场景中,系统需要在有限的计算资源下,快速给出尽可能好的解决方案。该方法可以提高LLM在这些场景下的实用性和效率,并降低推理成本。
📄 摘要(原文)
We study the reasoning behavior of large language models (LLMs) under limited computation budgets. In such settings, producing useful partial solutions quickly is often more practical than exhaustive reasoning, which incurs high inference costs. Many real-world tasks, such as trip planning, require models to deliver the best possible output within a fixed reasoning budget. We introduce an anytime reasoning framework and the Anytime Index, a metric that quantifies how effectively solution quality improves as reasoning tokens increase. To further enhance efficiency, we propose an inference-time self-improvement method using LLM-synthesized preference data, where models learn from their own reasoning comparisons to produce better intermediate solutions. Experiments on NaturalPlan (Trip), AIME, and GPQA datasets show consistent gains across Grok-3, GPT-oss, GPT-4.1/4o, and LLaMA models, improving both reasoning quality and efficiency under budget constraints.