Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
作者: Xinwei Wu, Heng Liu, Xiaohu Zhao, Yuqi Ren, Linlong Xu, Longyue Wang, Deyi Xiong, Weihua Luo, Kaifu Zhang
分类: cs.CL, cs.AI
发布日期: 2026-01-16
备注: Accepted by AAAI 2026
🔗 代码/项目: GITHUB
💡 一句话要点
利用稀疏自编码器发现LLM翻译启动特征,提升翻译效率与鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器翻译 稀疏自编码器 特征提取 因果干预 数据选择 微调 任务启动特征
📋 核心要点
- 现有方法难以解释LLM内在翻译能力的内部机制,缺乏对翻译过程关键特征的理解。
- 该论文提出一种基于稀疏自编码器(SAEs)的框架,用于识别和隔离LLM中的翻译启动特征。
- 实验表明,放大翻译启动特征可提升翻译准确性,而消融则导致幻觉,并提出了一种基于该特征的数据选择策略,提高了微调效率。
📝 摘要(中文)
大型语言模型(LLMs)即使在没有特定任务微调的情况下也经常表现出强大的翻译能力。然而,这种内在能力的内部机制在很大程度上仍然不透明。为了揭示这一过程,我们利用稀疏自编码器(SAEs)并引入了一种新颖的框架来识别特定任务的特征。我们的方法首先回忆在翻译输入上频繁共同激活的特征,然后使用基于PCA的一致性度量来过滤它们的功能连贯性。该框架成功地隔离了一小部分翻译启动特征。因果干预表明,放大这些特征会引导模型进行正确的翻译,而消融这些特征会导致幻觉和脱离任务的输出,证实它们代表了模型内在翻译能力的核心组成部分。从分析到应用,我们利用这种机械洞察力提出了一种新的数据选择策略,以实现高效的微调。具体来说,我们优先考虑在机械困难样本上进行训练——那些未能自然激活翻译启动特征的样本。实验表明,这种方法显著提高了数据效率并抑制了幻觉。此外,我们发现这些机制可以转移到同一系列的更大模型。我们的工作不仅解码了LLM中翻译机制的核心组成部分,而且还为使用内部模型机制创建更强大和高效的模型提供了一个蓝图。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在翻译任务中,其内在翻译能力背后的机制不明确的问题。现有方法缺乏对LLM内部如何启动和执行翻译过程的理解,导致难以优化翻译性能和抑制幻觉。
核心思路:论文的核心思路是通过识别和操纵LLM中负责启动翻译任务的特定神经元特征,来理解和控制其翻译行为。通过找到这些“翻译启动特征”,可以更好地理解LLM的翻译机制,并利用这些知识来改进翻译性能和数据效率。
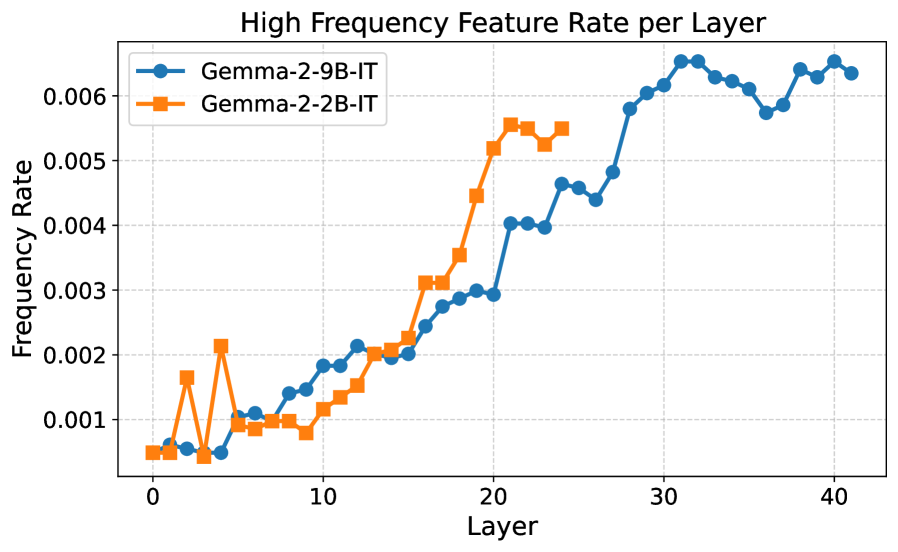
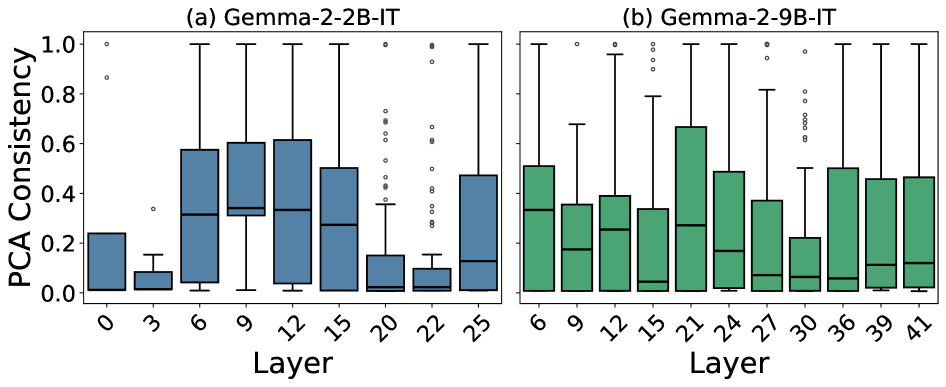
技术框架:整体框架包括以下几个主要阶段:1) 特征回忆:使用稀疏自编码器(SAEs)从LLM的激活中提取特征,并识别在翻译输入上频繁共同激活的特征。2) 特征过滤:使用基于PCA的一致性度量来过滤提取的特征,以确保它们在功能上是连贯的,从而获得更可靠的翻译启动特征。3) 因果干预:通过放大或消融识别出的翻译启动特征,观察LLM的翻译行为变化,验证这些特征在翻译过程中的作用。4) 数据选择:基于翻译启动特征的激活情况,选择“机械困难”样本进行微调,以提高数据效率和抑制幻觉。
关键创新:该论文的关键创新在于提出了一种基于稀疏自编码器和PCA一致性度量的框架,用于识别LLM中的任务启动特征,特别是翻译启动特征。与以往主要关注模型输出或整体性能的方法不同,该方法深入到模型内部,试图理解其内在机制。此外,利用识别出的特征进行数据选择,实现了更高效的微调。
关键设计:论文的关键设计包括:1) 使用稀疏自编码器提取LLM的激活特征,保证特征的稀疏性和可解释性。2) 使用基于PCA的一致性度量来过滤特征,确保特征在功能上是连贯的,减少噪声。3) 通过因果干预验证特征的作用,确保识别出的特征确实与翻译任务相关。4) 基于特征激活情况选择“机械困难”样本进行微调,提高数据效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过放大翻译启动特征可以显著提高LLM的翻译准确性,而消融这些特征会导致幻觉。基于翻译启动特征的数据选择策略,在微调过程中显著提高了数据效率,并有效抑制了幻觉。此外,研究发现这些机制可以迁移到同一系列更大的模型中,验证了该方法的泛化能力。
🎯 应用场景
该研究成果可应用于提升机器翻译系统的性能和鲁棒性,尤其是在资源受限的场景下。通过理解和控制LLM的翻译启动机制,可以开发更高效的微调策略,减少对大规模标注数据的依赖。此外,该方法也为理解和控制其他LLM任务提供了思路,具有广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of translation initiation features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on mechanistically hard samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.