NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
作者: Jiayu Liu, Rui Wang, Qing Zong, Qingcheng Zeng, Tianshi Zheng, Haochen Shi, Dadi Guo, Baixuan Xu, Chunyang Li, Yangqiu Song
分类: cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出NAACL框架,解决RAG系统中LLM因噪声上下文导致的置信度校准问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 置信度校准 检索增强生成 噪声感知 大型语言模型 监督微调
📋 核心要点
- RAG系统中LLM的置信度校准受噪声上下文干扰,导致模型过度自信,影响事实判断。
- NAACL框架通过噪声感知校准规则,指导模型学习区分噪声,提升置信度评估的准确性。
- 实验表明,NAACL在域内和域外均显著提升了LLM的置信度校准效果,降低了错误率。
📝 摘要(中文)
在关键事实领域部署大型语言模型(LLM)时,准确评估模型置信度至关重要。检索增强生成(RAG)被广泛用于提高 grounding,但 RAG 环境下的置信度校准仍然缺乏深入理解。本文对四个基准进行了系统研究,揭示了 LLM 由于检索到的上下文噪声而表现出较差的校准性能。具体而言,矛盾或不相关的证据往往会夸大模型的错误确定性,导致严重的过度自信。为了解决这个问题,我们提出了 NAACL 规则(噪声感知置信度校准规则),为解决噪声下的过度自信提供了原则性基础。我们进一步设计了 NAACL,一个噪声感知校准框架,它在这些规则的指导下,从大约 2K 个 HotpotQA 示例中综合监督信息。通过使用此数据执行监督微调(SFT),NAACL 使模型具备内在的噪声感知能力,而无需依赖更强大的教师模型。实验结果表明,NAACL 产生了显著的增益,在域内将 ECE 分数提高了 10.9%,在域外提高了 8.0%。通过弥合检索噪声和语言校准之间的差距,NAACL 为准确且认知上可靠的 LLM 铺平了道路。
🔬 方法详解
问题定义:论文旨在解决RAG系统中,大型语言模型(LLM)由于检索到的噪声上下文(如矛盾或不相关信息)而产生的置信度校准问题。现有方法无法有效处理这些噪声,导致LLM在给出答案时过度自信,即使答案是错误的。这种过度自信会严重影响LLM在需要高可靠性的事实性任务中的应用。
核心思路:论文的核心思路是让LLM具备噪声感知能力,使其能够识别并降低噪声上下文对置信度评估的影响。具体来说,通过定义一套NAACL规则,指导模型学习如何根据上下文的质量调整其置信度。这些规则旨在惩罚那些基于噪声上下文给出的高置信度预测,从而校准模型的置信度输出。
技术框架:NAACL框架主要包含两个阶段:首先,定义NAACL规则,这些规则描述了在不同噪声情况下,模型应该如何调整其置信度。其次,利用这些规则生成监督数据,通过监督微调(SFT)训练LLM。具体而言,使用HotpotQA数据集,并根据NAACL规则生成约2K个示例,用于训练模型。训练后的模型能够更好地识别噪声上下文,并给出更准确的置信度评估。
关键创新:该论文的关键创新在于提出了NAACL规则,并将其应用于LLM的置信度校准。与以往依赖更强大的教师模型进行校准的方法不同,NAACL通过规则引导的监督学习,使模型具备内在的噪声感知能力。这种方法不需要额外的教师模型,降低了计算成本,并提高了模型的泛化能力。
关键设计:NAACL规则的设计是关键。这些规则需要准确地描述噪声上下文对置信度的影响。具体规则细节未知,但可以推测规则会考虑上下文的相关性、一致性等因素。损失函数的设计也至关重要,需要能够有效地惩罚基于噪声上下文的高置信度预测。此外,用于SFT的数据集的构建也需要精心设计,以确保数据集能够充分覆盖各种噪声情况。
🖼️ 关键图片
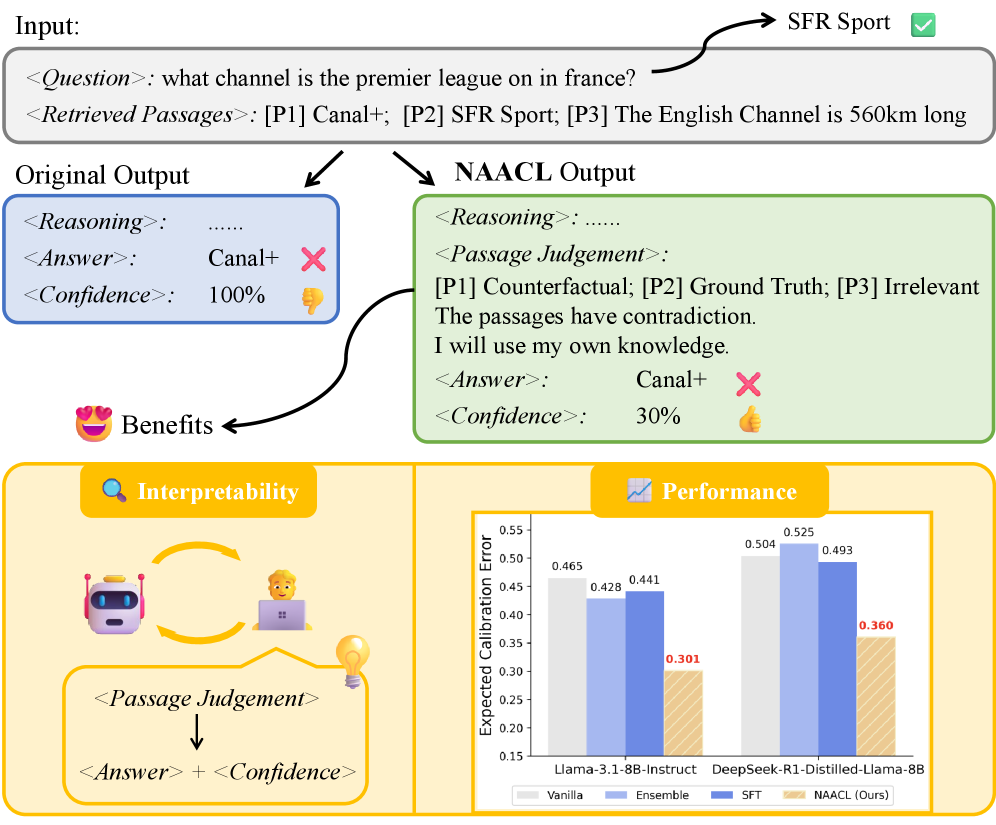
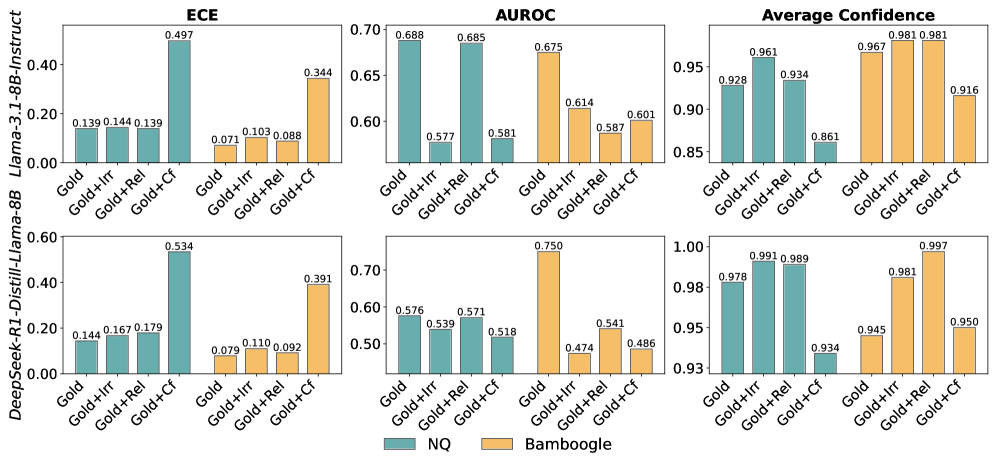
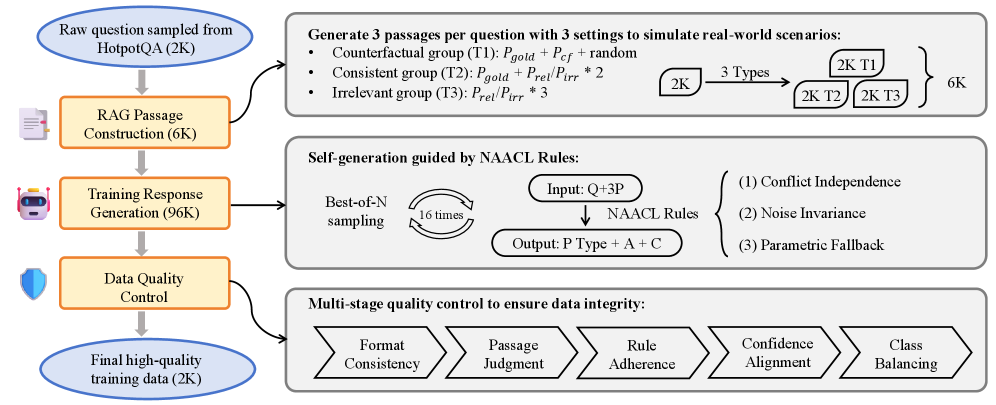
📊 实验亮点
NAACL框架在四个基准测试中均取得了显著的性能提升。特别是在域内测试中,ECE分数降低了10.9%,在域外测试中降低了8.0%。这些结果表明,NAACL能够有效地提高LLM的置信度校准能力,使其在面对噪声上下文时更加可靠。该方法无需依赖更强大的教师模型,具有较高的实用价值。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的RAG系统,例如医疗诊断、金融分析、法律咨询等领域。通过提高LLM的置信度校准能力,可以减少错误信息的传播,提高决策的准确性,并增强用户对AI系统的信任度。未来,该方法可以扩展到其他类型的噪声,进一步提升LLM的鲁棒性。
📄 摘要(原文)
Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.