ZPD Detector: Data Selection via Capability-Difficulty Alignment for Large Language Models
作者: Bo Yang, Yunkui Chen, Lanfei Feng, Yu Zhang, Shijian Li
分类: cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出ZPD Detector,通过能力-难度对齐进行大语言模型数据选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据选择 最近发展区 能力-难度对齐 项目反应理论
📋 核心要点
- 现有数据选择方法依赖静态标准,忽略了模型与数据间的动态关系,导致数据利用效率低下。
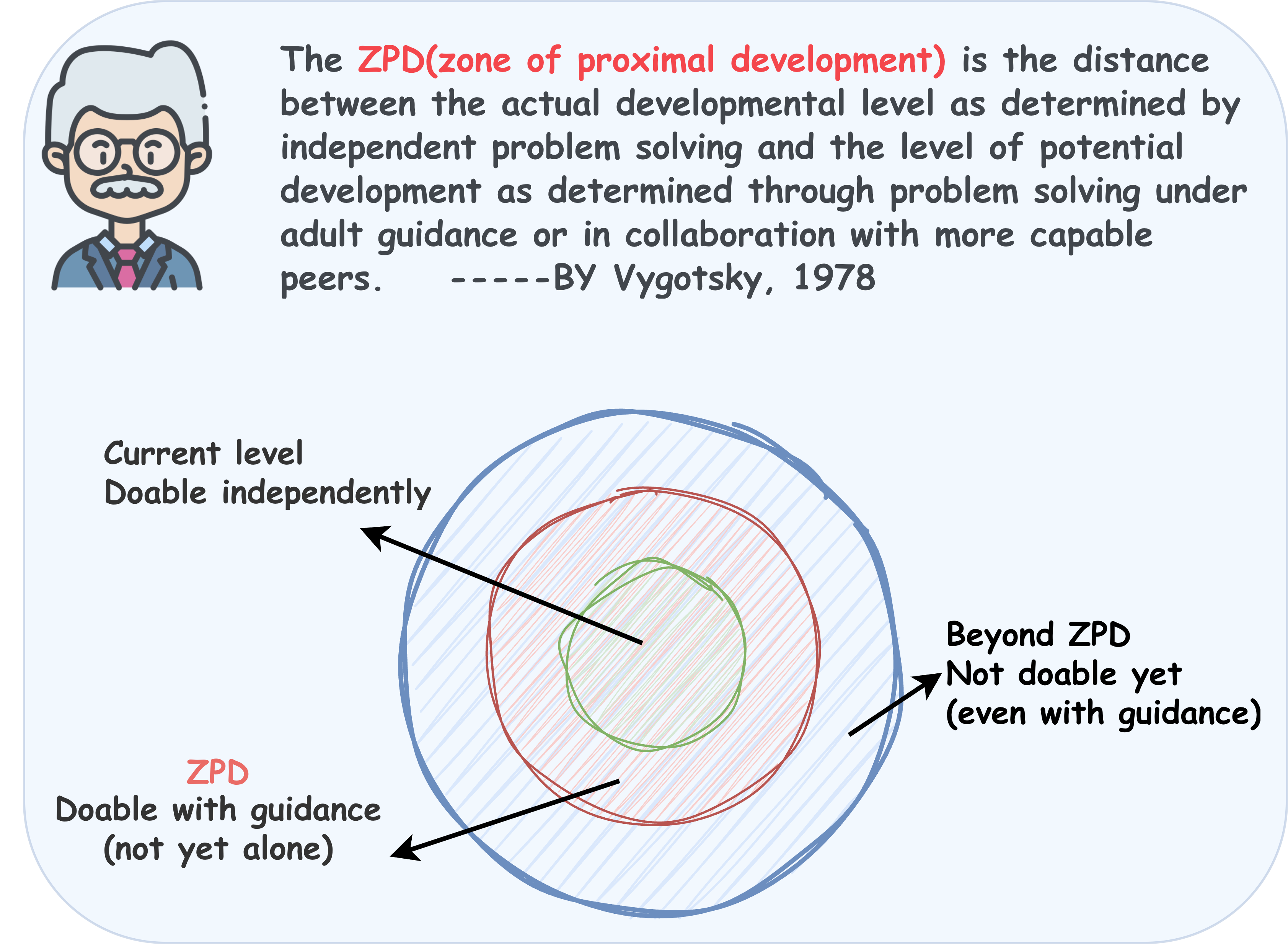
- ZPD Detector 借鉴最近发展区理论,通过建模模型能力与样本难度之间的对齐关系,动态选择信息量最大的样本。
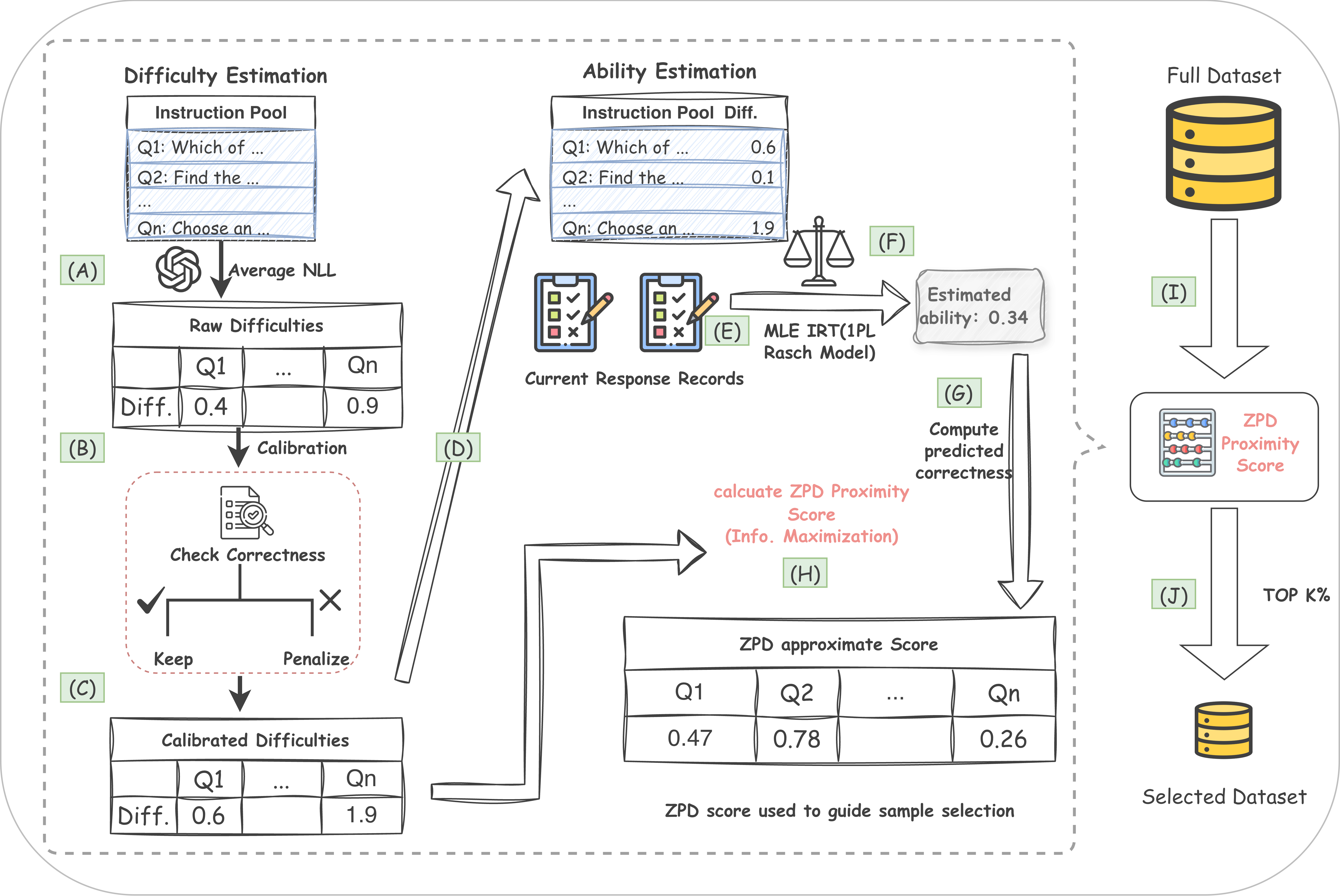
- 该方法集成了难度校准、基于IRT的模型能力估计和能力-难度匹配得分,提升数据利用率,并为训练策略设计提供新思路。
📝 摘要(中文)
随着大型语言模型训练成本的不断增加和高质量训练数据日益稀缺,在有限的数据预算下选择高价值样本或合成有效的训练数据已成为一个关键的研究问题。大多数现有的数据选择方法依赖于静态标准,如难度、不确定性或启发式方法,而未能对模型和数据之间不断演变的关系进行建模。受到最近发展区(ZPD)教育理论的启发,我们提出了ZPD Detector,这是一个数据选择框架,通过显式地建模样本难度和模型当前能力之间的对齐,从而采用模型和数据之间的双向视角。ZPD Detector集成了难度校准、基于项目反应理论(IRT)的模型能力估计以及能力-难度匹配得分,以动态地识别每个学习阶段中最具信息量的样本,从而提高数据利用效率;此外,这种动态匹配策略为训练策略设计提供了新的见解。所有代码和数据将在我们的工作被接受后发布,以支持可重复的研究。
🔬 方法详解
问题定义:论文旨在解决大语言模型训练中,如何从海量数据中选择最具价值的训练样本,以提高模型性能和训练效率的问题。现有数据选择方法通常采用静态的难度、不确定性等指标,无法有效捕捉模型学习过程中的动态变化,导致选择的样本与模型当前的学习状态不匹配,造成数据利用率低下。
核心思路:论文的核心思路是借鉴教育学中的“最近发展区”(Zone of Proximal Development, ZPD)理论,认为最有效的学习材料是那些难度略高于学习者现有水平,但通过努力可以掌握的材料。因此,论文提出通过动态地衡量样本难度和模型能力之间的匹配程度,选择位于模型“最近发展区”的样本进行训练。
技术框架:ZPD Detector 框架主要包含三个模块:1) 难度校准模块,用于评估每个样本的难度;2) 模型能力估计模块,基于项目反应理论(IRT)估计模型在不同样本上的能力水平;3) 能力-难度匹配模块,计算样本难度与模型能力之间的匹配得分,选择匹配得分最高的样本。整个流程是动态的,在每个训练阶段都会重新评估样本难度和模型能力,从而选择最合适的样本。
关键创新:该方法最重要的创新在于将教育学理论引入到大语言模型的数据选择中,通过动态建模模型能力和样本难度之间的关系,实现了更有效的数据选择。与现有方法相比,ZPD Detector 能够更好地适应模型学习过程中的动态变化,选择更具信息量的样本,从而提高训练效率和模型性能。
关键设计:难度校准模块可以使用多种方法,例如基于困惑度或梯度范数等指标。模型能力估计模块采用项目反应理论(IRT),将模型在每个样本上的表现视为一个概率分布,并估计模型的区分度和难度参数。能力-难度匹配模块可以使用不同的匹配函数,例如高斯函数或 sigmoid 函数,来衡量样本难度与模型能力之间的匹配程度。具体的参数设置和损失函数选择取决于具体的应用场景和数据集。
🖼️ 关键图片
📊 实验亮点
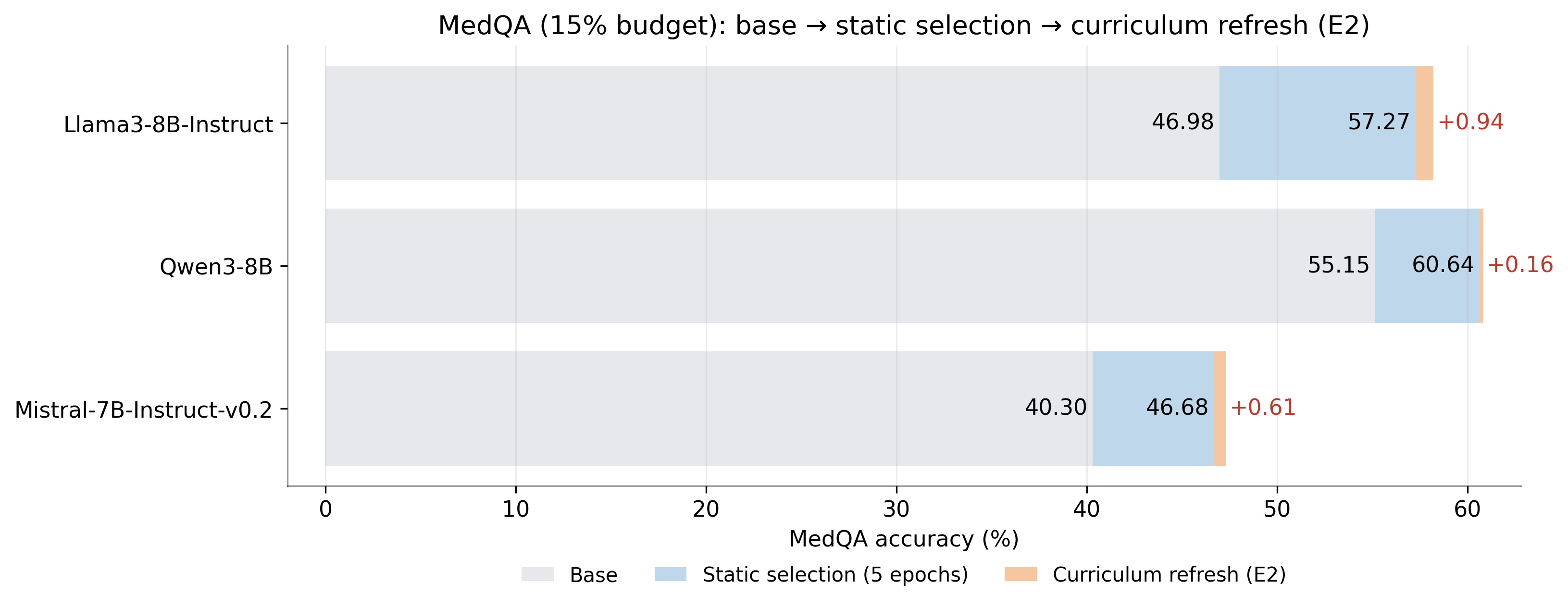
论文提出的ZPD Detector 能够动态地选择信息量最大的样本,从而提高数据利用效率。实验结果表明,该方法在多个数据集上优于现有的数据选择方法,能够显著提高模型的性能。具体的性能数据和对比基线将在论文发表后公布。
🎯 应用场景
ZPD Detector 可应用于各种大语言模型的预训练和微调阶段,尤其是在数据资源有限的情况下,能够显著提高数据利用效率,降低训练成本。此外,该方法还可以用于主动学习、课程学习等领域,指导模型选择合适的学习材料,提升学习效果。该研究为大语言模型训练策略的设计提供了新的视角。
📄 摘要(原文)
As the cost of training large language models continues to increase and high-quality training data become increasingly scarce, selecting high-value samples or synthesizing effective training data under limited data budgets has emerged as a critical research problem. Most existing data selection methods rely on static criteria, such as difficulty, uncertainty, or heuristics, and fail to model the evolving relationship between the model and the data. Inspired by the educational theory of the Zone of Proximal Development (ZPD), we propose ZPD Detector, a data selection framework that adopts a bidirectional perspective between models and data by explicitly modeling the alignment between sample difficulty and the model's current capability. ZPD Detector integrates difficulty calibration, model capability estimation based on Item Response Theory (IRT), and a capability-difficulty matching score to dynamically identify the most informative samples at each learning stage, improving data utilization efficiency; moreover, this dynamic matching strategy provides new insights into training strategy design. All code and data will be released after our work be accepted to support reproducible researc